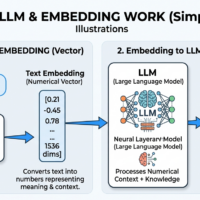
The commercially sensible way to build AI products in 2026 is usually not to pretrain a new frontier model from scratch. For most developers and small operators, the faster route to revenue is to package pretrained foundation models as products, then differentiate through proprietary data, workflow design, customer integration, evaluation, latency, compliance and support. That is especially true because fine-tuning needs far less compute, time and data than pretraining, and parameter-efficient fine-tuning reduces adaptation cost further. The result is a market where the most attractive products are often domain-adapted systems rather than brand-new base models.
The most monetisable product families today are SaaS APIs around foundation models, fine-tuned domain LLMs, vision systems, speech systems, recommendation and ranking engines, anomaly and fraud detection, generative media tools, and domain-specific models for regulated or workflow-heavy verticals. Their pricing patterns are already visible in the market: token- or request-based billing for APIs, per-seat subscriptions for workflow software, per-transaction pricing for risk systems, and bespoke annual contracts for private or regulated deployments.
A data centre is the operational backbone that makes these businesses possible. It supplies compute, storage, networking, orchestration and physical control for training, fine-tuning and inference. At scale, that matters not just for throughput but for unit economics: low-latency inference, high GPU utilisation, storage throughput, repeatable deployments and data locality all become commercial differentiators. Owning or controlling data-centre infrastructure also creates second-order revenue opportunities, such as managed model hosting, private LLM services, GPU rental, MLOps platforms and data services.
For a solo developer or small team with no stated budget constraint, the platform choice is straightforward. Google Colab is excellent for learning, prototyping and one-off experiments because setup is minimal, but resources are not guaranteed and limits fluctuate. A small self-owned or colocated GPU box becomes attractive when workloads are steady, data is sensitive, or full control matters. Public cloud and specialist GPU clouds remain the best fit when demand is bursty or when multi-GPU scale is required immediately.
Commercial opportunity map
The winning commercial pattern is to start with a narrow customer pain point, choose the lightest model class that can solve it, adapt rather than pretrain where possible, then wrap the model in a complete delivery system: data ingestion, evaluation, billing, monitoring, governance and customer success. In practice, the “product” is the full loop from customer signal to model output to measurable customer outcome.
The table below compares the main model families a developer or operator can realistically build and monetise. Cost bands are indicative synthesis rather than vendor quotes; they are inferred from current hosted notebook and cloud GPU pricing, consumer and data-centre GPU pricing, and the much lower compute profile of fine-tuning or PEFT compared with full pretraining.
| Model family | Core use cases | Typical development stack | Typical monetisation | Indicative cost / complexity |
|---|---|---|---|---|
| SaaS API over foundation models | Chat, extraction, summarisation, workflow automation, copilots | Hosted model API, retrieval, guardrails, billing, analytics, auth | Usage-based per token/request; enterprise minimums | Low to medium cost; medium complexity |
| Fine-tuned or domain LLMs | Legal, finance, support, coding, internal knowledge assistants | PyTorch, Transformers, PEFT, private datasets, vector search, model serving | Seat-based SaaS, private deployment, premium API | Medium cost; high complexity |
| Vision models | OCR, defect detection, moderation, document AI, product recognition | TorchVision, ViTs, object detection, annotation tools, GPU inference | Per image, per document, per seat, or workflow contract | Medium cost; medium to high complexity |
| Speech and audio models | Transcription, voice bots, subtitles, TTS, voice cloning | Whisper or other ASR, audio preprocessing, realtime serving, speaker controls | Per minute, per seat, API usage, studio/enterprise bundles | Medium cost; medium to high complexity |
| Recommendation and ranking | Ecommerce personalisation, feeds, “next best action”, search ranking | Feature store, embeddings, candidate generation, ranking, online feedback loops | Revenue share, uplift pricing, SaaS subscription, enterprise contract | Medium to high cost; high complexity |
| Anomaly, fraud and predictive maintenance | Fraud scoring, equipment alerts, cyber events, abuse detection | Time-series pipelines, risk scoring, streaming features, human review tools | Per transaction, per asset, per alert stream, annual platform fee | Medium cost; high complexity |
| Generative media models | Image, video, design, brand assets, synthetic content | Diffusion or multimodal generation, media pipelines, safety filters, asset management | Credit bundles, subscription, per generation, enterprise content platform | Medium to high cost; high complexity |
| Domain-specific vertical models | Medical triage, industrial copilots, insurance, procurement, compliance | Fine-tuned base models plus domain ontology, retrieval, governance, audit logging | High-ACV enterprise sales, deployment fees, services + software | High cost; very high complexity |
A useful rule of thumb follows from that table: the nearer your product gets to business workflow and proprietary data, the stronger your pricing power becomes. Generic wrapper apps can launch fastest, but recommendation, fraud, domain assistants and private AI platforms tend to be stickier because they are harder to replace and more deeply embedded in customer operations. That is visible in the market’s move towards enterprise plans, managed hosting, private deployments and workflow-native agents rather than generic chat alone.
Customers and monetisation strategies
The customer map splits into four practical segments. Developers and AI-native startups buy for speed, documentation, uptime and unit economics. For them, the product is usually an API, SDK or hosted endpoint, and the cleanest pricing is usage-based per token, second, request or image. OpenAI API Pricing and ElevenLabs Pricing both exemplify this style, while Replicate Pricing shows the same logic for model-time billing.
SMBs and team-based buyers tend to prefer seat pricing because it matches procurement habits and is easy to budget. Here the model is usually hidden inside a workflow product: writing help, marketing coordination, design generation, coding assistants or CRM automation. That is why per-user plans are common in software such as GitHub Copilot and Jasper. For early-stage vendors, seat pricing also smooths revenue better than raw per-call metering.
Enterprises and regulated buyers care less about headline model quality than about deployment control. Their buying criteria are data residency, SSO, auditability, model customisation, policy controls, indemnity, and private connectivity. That is why enterprise tiers often include codebase indexing, private models, governance and on-prem or private-cloud delivery. The relevant commercial pattern is annual contract value with implementation fees, capacity commitments and premium support.
Performance and transaction buyers want measurable lift: better conversion, lower fraud, higher retention, lower churn. For these customers, usage pricing can be directly linked to economic value — per screened transaction, per recommended interaction, per lead scored, per campaign generated, or per managed asset. That makes recommendation, fraud detection, lead scoring and bid optimisation especially attractive business models, because the ROI case is easier to prove than for generic content generation.
The strongest pricing design is usually hybrid. A good default is a platform fee that covers base value and support, plus a usage component that scales with volume. This protects vendor margin when workloads spike and aligns price with customer value when adoption grows. It is also the most natural bridge from self-serve to enterprise.
Technical requirements and the typical development stack
Most serious teams converge on a stack with five layers. The model layer is typically built with PyTorch Distributed for training and parallelism, paired with Transformers fine-tuning docs and PEFT for adaptation. This matters commercially because it shortens the path from idea to domain-specialised product. For vision work, developers usually fine-tune pretrained architectures through TorchVision or transformer-based image models; for speech they often start from models like Whisper rather than training ASR from scratch.
The serving layer matters as much as the model itself. Production inference is about latency, autoscaling, batching, streaming and graceful degradation under load. Teams commonly serve LLMs with engines such as Ray Serve and vLLM, or buy managed hosting through Hugging Face Inference Endpoints. This is where many otherwise promising products fail: they can demo a model, but not operate it economically in production.
The platform layer is the bridge between experimentation and repeatable deployment. Kubeflow provides a Kubernetes-native platform for the AI lifecycle, while MLflow Model Serving and its registry support model versioning, serving and lineage. The data layer is equally important: feature stores such as Feast separate offline training features from low-latency online serving. In recommendation, fraud and lead-scoring systems, that online/offline split is one of the main determinants of production quality.
A practical default stack for a new commercial product is therefore: PyTorch + Transformers/PEFT for training; managed or open-source serving for inference; Kubernetes/Kubeflow for orchestration; MLflow for registry and deployment; and a feature store or vector retrieval layer where personalisation or retrieval matters. That architecture is modular enough for a startup, but mature enough to scale into an enterprise platform.
The role of a data centre in AI
A data centre is not just “where the servers live”; it is the environment that turns model code into a service business. At minimum it provides compute nodes, storage, internal networking, power, cooling, isolation and operational tooling. In AI workloads those physical details matter directly, because training and inference performance are limited by GPU availability, memory bandwidth, storage throughput and interconnect efficiency.
For training at scale, the data centre’s job is to keep expensive accelerators continuously fed with data and parallel work. NVIDIA’s own docs frame this in terms of “training to convergence”, while PyTorch Distributed exposes the parallelism patterns that modern multi-GPU work depends on: data parallelism, tensor parallelism and pipeline parallelism. The economic implication is simple: poor storage or networking can turn a GPU cluster into an idle, cash-burning asset.
For inference serving, the data centre must optimise a different metric: cost per request or cost per token at an acceptable latency. NVIDIA describes real-world inference as a throughput-and-latency problem, and serving frameworks such as Ray Serve and Red Hat OpenShift AI focus on multi-node serving, autoscaling and production safety. In other words, a good AI data centre is not just fast at training; it is excellent at repeatedly serving models under real traffic.
For data storage, the data centre holds far more than raw files. It stores training corpora, checkpoints, model weights, embeddings, feature tables, logs, audit records and retrieval indexes. That is why feature and model stores matter so much in production AI. A system like Feast distinguishes offline historical features from low-latency online serving, while MLflow standardises model packaging and delivery. Both are exactly the kind of value-added data service a data-centre operator can package commercially.
The edge-versus-cloud decision is fundamentally a latency, bandwidth and governance decision. AWS’s explanation is crisp: edge workloads run closer to devices and end users, while cloud workloads run in provider data centres. Edge or on-prem deployments make most sense where you need very low latency, process large volumes of local data, or keep data inside a jurisdiction or facility. Hybrid offerings such as AWS Outposts racks exist precisely to serve that middle ground.
A data-centre owner can therefore build and sell at least five product types. First, managed ML hosting, similar in spirit to Hugging Face Inference Endpoints. Second, private AI and private LLM environments, similar to VCF Private AI Services. Third, GPU rental and reserved capacity, as sold by Lambda Cloud Pricing and CoreWeave Cloud Pricing. Fourth, MLOps platforms, using building blocks such as Kubeflow, MLflow and Red Hat OpenShift AI. Fifth, data services such as feature stores, vector indexing, retrieval and model registry, which are now directly productised in private AI stacks.
Personal or colocated data centre versus Google Colab and cloud GPU
The comparison below is best understood through workload shape. If your usage is sporadic and exploratory, hosted notebooks and rented GPUs dominate because they eliminate setup and idle-capacity cost. If your usage is steady and privacy-sensitive, owned or colocated infrastructure becomes more compelling. If your needs are bursty, global or multi-GPU, cloud remains the operationally simplest option.
| Option | Cost profile | Scale ceiling | Performance profile | Security and data control | Reproducibility | Best fit |
|---|---|---|---|---|---|---|
| Google Colab | Lowest entry cost; pay-as-you-go credits available | Low to moderate | Good for notebooks, weak for guaranteed sustained throughput | Moderate; notebook outputs can live in Drive, local runtime has security risks | Moderate for notebooks, weaker for hardware consistency | Education, prototyping, proof of concept |
| Small self-owned or colocated data centre | Higher upfront capex, lower marginal cost at steady use | Moderate unless you add nodes | Strong if tuned well; best when hardware is fully utilised | Highest direct control, especially for sensitive data | High if hardware, containers and images are pinned | Internal tools, private AI, steady inference or fine-tuning |
| Public cloud or specialist GPU cloud | Highest variable cost, no capex | Highest, from single GPU to large clusters | Best for burst scale and multi-GPU jobs | Strong controls possible, but shared-provider model and egress still matter | High if you standardise on images and IaC | Production scale-out, batch training, global services |
The trade-off is easiest to see in four dimensions. Cost: Colab looks cheapest at the start because there is almost no setup cost; self-hosting looks expensive because the hardware is real capex; cloud looks cheap until you run it continuously. Scalability: Colab is fundamentally constrained, self-hosting scales only as far as your rack and budget, and cloud scales the furthest. Security: self-hosting wins on direct control, though only if you can operate it competently; cloud can be excellent but is still provider-mediated; Colab is weakest for sensitive or regulated workloads. Reproducibility: self-hosting and cloud both improve when you pin hardware, containers and model versions; Colab is weaker because resource availability and runtime characteristics can vary.
This chart is intentionally normalised and illustrative, not a benchmark. It reflects current signals rather than a single universal price sheet: Colab pay-as-you-go starts at $9.99 for 100 compute units and resources are not guaranteed; Google Cloud’s Colab pricing shows an L4 at about $0.67/hour and an A100 at about $3.52/hour; Lambda Instances shows A6000-class rental around $1.09 per GPU-hour; and a current RTX 5090 starts at $1,999 with a 575W graphics power figure. Self-owned infrastructure only wins cleanly if you keep it busy enough to amortise the hardware, and the chart does not include colocation rack fees or site-specific electricity tariffs.
Marketing models and real-world examples
For marketing, AI value clusters around five model families. Personalisation and recommendation models choose the next best product, message, asset or action. Content generation models produce copy, images, video and design variants. Ad optimisation models allocate bids and creative combinations. Customer segmentation models cluster or rank audiences. Lead scoring models estimate conversion probability. These are commercially attractive because each maps cleanly to a familiar KPI: conversion rate, CAC, ROAS, engagement, retention or pipeline velocity.
The clearest proof points are already in market. Amazon Personalize explicitly markets real-time recommendations across websites, apps, search engines and marketing channels; Jasper Personalization Agent connects directly to CRM data to generate segment-specific messaging; and Google Ads’ Smart Bidding uses machine learning to optimise bids at auction time for conversions or conversion value. Meanwhile, segmentation and lead scoring are now standard AI features inside CRM suites rather than niche data-science projects.
Virality in AI products usually comes from one of three mechanisms. The first is instant personal utility, as with chatbots and copilots. The second is personal relevance, as with recommendation feeds. The third is content creation leverage, where one prompt generates campaign-ready output that users can immediately publish or share. Products that combine at least two of those mechanisms tend to spread fastest.
| Real-world product | What model family it uses | Why it matters commercially |
|---|---|---|
| ChatGPT | GPT-4o, a multimodal transformer model for text and vision, delivered in chat and API form. | Breakout evidence that a general-purpose assistant can monetise via freemium, subscription and API usage; Reuters reported 100 million monthly active users only two months after launch. |
| GitHub Copilot | Generative code models with contextual prompting; enterprise tiers add codebase indexing and access to fine-tuned private models. | A strong example of seat-based monetisation for a workflow-native LLM product. |
| Duolingo Max | GPT-4-powered conversational tutoring features such as roleplay and video call. | Shows how a domain-specific LLM can be packaged as a premium subscription tier rather than a generic chatbot. |
| Canva AI 2.0 | A design-focused foundation model that generates fully layered, editable outputs and orchestrates creative tools. | Important for marketing because it compresses campaign ideation, asset generation and editing into one product. |
| Adobe Firefly | Family of creative generative AI models trained on licensed and public-domain content. | A leading example of how copyright provenance becomes a commercial differentiator for enterprise generative media. |
| ElevenLabs Voice Cloning | Speech synthesis and voice-cloning models, with instant and professional modes. | Demonstrates a strong per-minute, subscription and API model in creator, dubbing and media workflows. |
| Spotify Discover Weekly | Large-scale recommendation and personalisation models. | Shows how recommendations monetise indirectly through engagement, retention and subscription propensity. |
| TikTok For You | Feed ranking and recommendation system tailored to each user. | Perhaps the clearest example of recommendation systems becoming the product itself, not just a supporting feature. |
| Stripe Radar | Machine-learning risk scoring across transactions and accounts. | Shows how anomaly detection and fraud models monetise directly through per-transaction pricing and loss reduction. |
The strategic lesson is that marketing-friendly AI products do best when they combine generation with decisioning. A copywriter alone is nice to have; a system that segments the audience, generates the message, ranks the channel, adjusts the bid and scores the lead is much harder to replace. That is why recommendation, optimisation and scoring layers often end up being more defensible than raw generation.
Final Note:
Artificial intelligence and deep learning are no longer only research topics. They have become practical business tools that developers, startups, and companies can turn into real products. The most important point is that most developers do not need to build a huge AI model from zero. Instead, they can use existing foundation models, fine-tune them, connect them with useful data, and package them into software, apps, APIs, or business tools that solve a clear problem.
Developers can create and sell many types of AI models. Some of the most useful examples are chatbots, writing assistants, document summarizers, image recognition models, speech-to-text tools, voice generators, recommendation engines, fraud detection systems, marketing automation tools, and domain-specific assistants for industries such as education, finance, healthcare, ecommerce, law, and customer support. The strongest AI products are usually not just “a model,” but a complete system that includes data, user interface, automation, billing, monitoring, and a clear business result.
One of the biggest business opportunities is building AI tools around existing large language models. For example, a developer can build a customer support assistant, an app that summarizes long documents, an AI writing tool for websites, an AI tutor, a coding helper, or a private chatbot trained on company information. These products can be sold through monthly subscriptions, pay-per-use pricing, API access, enterprise contracts, or premium app purchases.
Deep learning models can also be used for computer vision. This means software that understands images or videos. Examples include tools for reading documents, detecting objects, checking product quality, removing backgrounds, recognizing products, moderating images, or helping businesses process visual data faster. These models can be especially valuable when they save time, reduce human work, or improve accuracy in a business workflow.
Speech and audio models are another strong product area. Developers can create transcription tools, subtitle generators, voice assistants, text-to-speech apps, dubbing tools, language learning apps, or voice-based customer support systems. These products are often sold per minute of audio, as monthly subscriptions, or as API services for other developers and businesses.
Recommendation models are one of the most powerful forms of AI for business. They help decide what product, video, article, course, app, message, or advertisement a user should see next. Platforms such as TikTok, Spotify, YouTube, Amazon, and Netflix became extremely powerful because of recommendation systems. A good recommendation model can increase engagement, sales, retention, and user satisfaction. For businesses, this can be more valuable than a simple chatbot because it directly affects revenue.
AI can also be used for anomaly detection, fraud detection, and risk scoring. These models look for unusual patterns in data. They can detect suspicious payments, fake accounts, system problems, security threats, or unusual customer behavior. These models are useful because companies are willing to pay for tools that reduce losses, prevent fraud, and protect their systems.
Data centres are important because AI needs strong computing power. A data centre provides the hardware, storage, networking, security, cooling, and infrastructure needed to train and run AI models. In simple words, a data centre is the physical and technical backbone behind many AI products. It allows companies to process large amounts of data, run GPUs, host models, serve users, and keep systems available all the time.
If someone owns or controls a data centre, they can build many AI-related products. They can rent GPU power to developers, host private AI models for companies, offer managed machine learning services, provide secure AI infrastructure, run private chatbots for businesses, sell model deployment services, or create a platform where other companies can train and use AI models. In this case, the data centre itself becomes a business asset, not just a technical facility.
The difference between using Google Colab and owning infrastructure is mainly about control, scale, cost, and reliability. Google Colab is very good for learning, testing, and building prototypes. It is easy to start, does not require expensive hardware, and is useful for students, developers, and small experiments. However, Colab is not always reliable for serious production work because resources can be limited, sessions can stop, and hardware availability is not guaranteed.
Owning or renting serious GPU infrastructure gives more control. It is better for companies that need stable performance, private data, repeated training, or production-level AI services. A cloud GPU service is useful when a company needs flexible power and wants to scale quickly without buying hardware. A private or colocated data centre is better when the workload is steady, privacy is important, and the company wants long-term control over infrastructure.
For marketing, AI models can be especially profitable. Developers can build models that generate ad copy, write social media posts, create email campaigns, score leads, segment customers, recommend products, personalize landing pages, analyze competitors, predict customer behavior, and optimize advertising campaigns. These tools are valuable because businesses always want more sales, better content, lower advertising costs, and higher conversion rates.
A strong marketing AI product should not only generate text. The best marketing models combine generation with decision-making. For example, a simple AI copywriter can write a post, but a stronger system can choose the best audience, write different versions, predict which version will perform better, recommend the best time to post, and score which leads are most likely to buy. This kind of AI product is much harder to replace and can be sold for a higher price.
Many viral AI products became popular because they solved a clear problem in a simple and impressive way. ChatGPT became viral because people could immediately use it for writing, learning, coding, planning, and answering questions. GitHub Copilot became popular because it helps developers write code faster inside their normal workflow. Canva’s AI tools became useful because they help people create designs quickly. ElevenLabs became known for high-quality AI voices. TikTok and Spotify use recommendation models to keep users engaged by showing them content they are likely to enjoy.
The lesson from these products is that AI becomes powerful when it is easy to use, gives fast results, and fits into something people already want to do. A model alone is not enough. The product must solve a real problem, feel simple, and create value quickly. The best AI businesses are built around useful workflows, not only around impressive technology.
Another important point is that data is a major advantage. A developer who has unique data, clean data, or domain-specific data can create a stronger AI product than someone who only uses a general model. For example, an AI tool trained or connected to legal documents, medical information, ecommerce behavior, customer support chats, or marketing performance data can become more valuable than a generic chatbot.
However, AI businesses also need to think about responsibility, privacy, copyright, and regulation. In Europe, AI regulation is becoming more important, especially for products that affect people’s rights, decisions, jobs, health, money, or personal data. Developers should think carefully about where their data comes from, how the model is used, whether users know they are interacting with AI, and whether the system can make harmful or unfair decisions.
In conclusion, the best opportunity for developers is not always to create the biggest AI model. A better strategy is to create a useful AI product around a real customer need. This can be done by using existing models, fine-tuning them, adding private or domain data, building a clean interface, and selling the result as a service, app, API, or business platform. AI models, data centres, cloud GPUs, and marketing automation are all part of the same bigger picture: turning intelligence, data, and infrastructure into products that people and businesses are willing to pay for.
Sources and further reading
- Hugging Face Transformers: Fine-tuning
- Hugging Face PEFT
- Attention Is All You Need
- OpenAI Whisper
- OpenAI API Pricing
- GitHub Copilot Plans
- Jasper Pricing
- Stripe Radar
- NVIDIA Data Center Deep Learning Performance Hub
- Ray Serve
- Kubeflow
- MLflow Model Serving
- Feast Feature Store
- Hugging Face Inference Endpoints
- Lambda Cloud Pricing
- CoreWeave Cloud Pricing
- Google Colab FAQ
- Google Cloud Colab Pricing
- AWS Outposts Rack
- Amazon Personalize
- Google Ads Smart Bidding
- HubSpot Predictive Lead Scoring
- ChatGPT
- Reuters: ChatGPT fastest-growing user base
- Duolingo Max
- Canva AI 2.0
- Adobe Firefly
- ElevenLabs Voice Cloning
- Spotify Engineering: Personalization
- TikTok: How For You Recommendations Work
- European Commission: AI Act
- ICO Guidance on AI and Data Protection
- NIST AI Risk Management Framework
- OECD: Generative AI