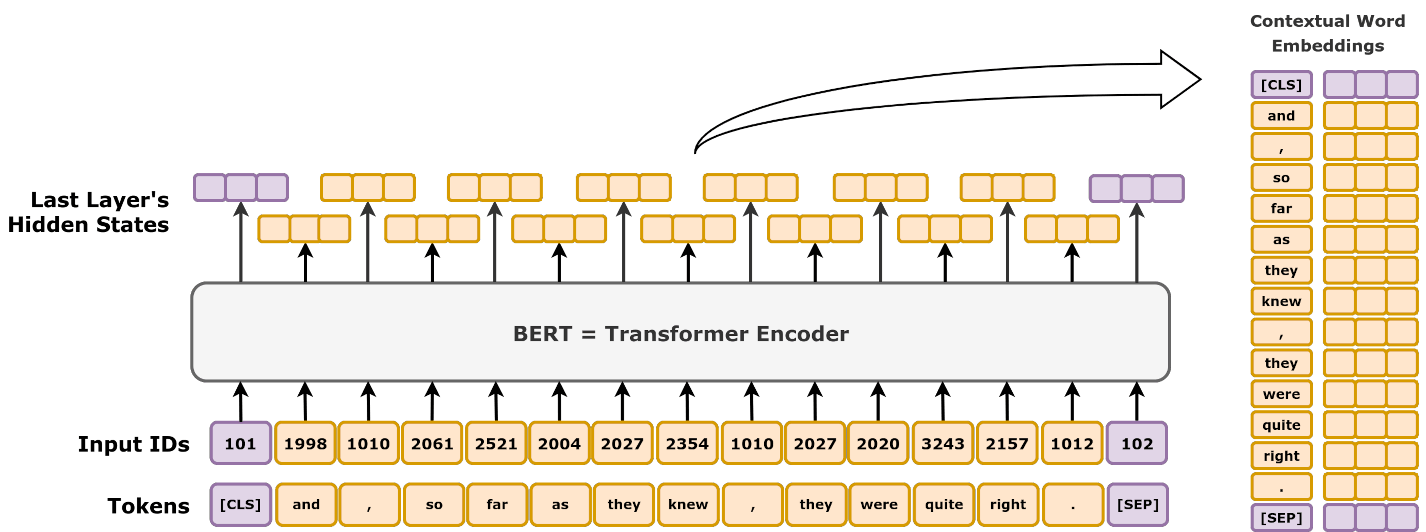
Transformer Models Comparison FeatureBERTGPTBARTDeepSeekFull TransformerUses Encoder?✅ Yes❌ No✅ Yes❌ No✅ YesUses Decoder?❌ No✅ Yes✅ Yes✅ Yes✅ YesTraining ObjectiveMasked Language Modeling (MLM)Autoregressive (Predict Next Word)Denoising AutoencodingMixture-of-Experts (MoE) with Multi-head Latent Attention (MLA)Sequence-to-Sequence (Seq2Seq)Bidirectional?✅ Yes❌ No✅ Yes (Encoder)❌ NoCan be bothApplicationNLP tasks (classification, Q&A, search)Text generation (chatbots, summarization)Text generation and comprehension (summarization, translation)Advanced reasoning tasks (mathematics, coding)Machine translation, speech-to-text Understanding BERT: How It Works and Why It’s Transformative in NLP BERT (Bidirectional Encoder Representations from Transformers) is a foundational model in Natural Language Processing (NLP) that has reshaped how machines understand language. Developed by Google in 2018, BERT brought significant improvements in language understanding tasks by introducing a bidirectional transformer-based architecture that reads text in both directions (left-to-right and right-to-left). This blog post will dive deep into how BERT works, its architecture, pretraining strategies, and its applications, complemented by tables and figures for better comprehension. BERT’s Architecture At its core, BERT is based on the transformer architecture, specifically utilizing the encoder part of the transformer model. Key Components: Self-Attention Mechanism: BERT uses multi-headed self-attention to focus on different parts of a sentence, learning which words are important relative to each other. Layers: BERT models come in two sizes—BERT-Base (12 layers) and BERT-Large (24 layers). These layers process the text at different levels of abstraction. Table 1: BERT-Base vs. BERT-Large ModelLayersHidden UnitsAttention HeadsParametersBERT-Base1276812110 millionBERT-Large24102416340 million Bidirectional Learning in BERT Previous models like GPT were unidirectional, meaning they processed text only from left to right. BERT, however, uses a bidirectional approach, allowing it to read the entire context of a word by looking at the words both before and after it. This improves BERT’s ability to understand the nuances of language, particularly for tasks like sentiment analysis and question answering. Figure 1: Unidirectional vs. Bidirectional Language Models Title of the image source : “深蓝学院第八节笔记 构建一个GPT模型” Author: weixin_46479223 on CSDN License: CC BY-SA 4.0 Pretraining Strategies: MLM and NSP BERT’s training involves two innovative pretraining objectives: Masked Language Model (MLM): BERT randomly masks 15% of the tokens in each sentence and trains to predict those masked words. This forces the model to learn context from both directions. Next Sentence Prediction (NSP): BERT is also trained to predict whether a given sentence follows another sentence. This task is crucial for understanding sentence relationships in tasks like question answering. Table 2: Pretraining Tasks in BERT TaskDescriptionExampleMasked Language Model (MLM)Predicts masked words in a sentence”The cat sat on the [MASK].”Next Sentence Prediction (NSP)Predicts whether two sentences follow each other”He went to the store. He bought milk.” Applications of BERT 1. Question Answering BERT is trained to understand the context of passages and answer questions based on them. It excels in SQuAD (Stanford Question Answering Dataset) by locating the exact span of text that answers a question. 2. Sentiment Analysis Fine-tuned BERT models can analyze the sentiment of a text (positive, negative, or neutral) by understanding how context affects the meaning of words. 3. Text Summarization BERT can be combined with abstractive summarization models to generate human-like summaries that rephrase and condense text, while extractive methods focus on pulling key sentences. As of January 2025, significant advancements have been made in Natural Language Processing (NLP), particularly with the introduction of ModernBERT. This new model series offers improvements over BERT and its successors in both speed and accuracy. lighton.ai Key Enhancements in ModernBERT: Extended Contextual Understanding: ModernBERT supports sequences of…
Do you want to read a summery of what is BERT in 2 min read? (Bidirectional Encoder Representations from Transformers) – day 67