3 choices: 1- Apple MLX 2- NVIDIA CUDA 3-AMD ROCm: Choosing the Best AI Platform
Apple MLX vs NVIDIA CUDA vs AMD ROCm: AI Platform Guide: Launching an AI-driven startup as a solo developer in 2026 means making pivotal technology […]

Apple MLX vs NVIDIA CUDA vs AMD ROCm: AI Platform Guide: Launching an AI-driven startup as a solo developer in 2026 means making pivotal technology […]
We discuss the transformative world of deep learning and the AI Academy Deep Learning app, which simplifies complex AI concepts like neural networks, convolutional neural […]

Solo Developer’s Guide to Building Competitive Language Model Applications A Solo Developer’s Guide to Building Competitive Language Model Applications With the explosion of large language […]
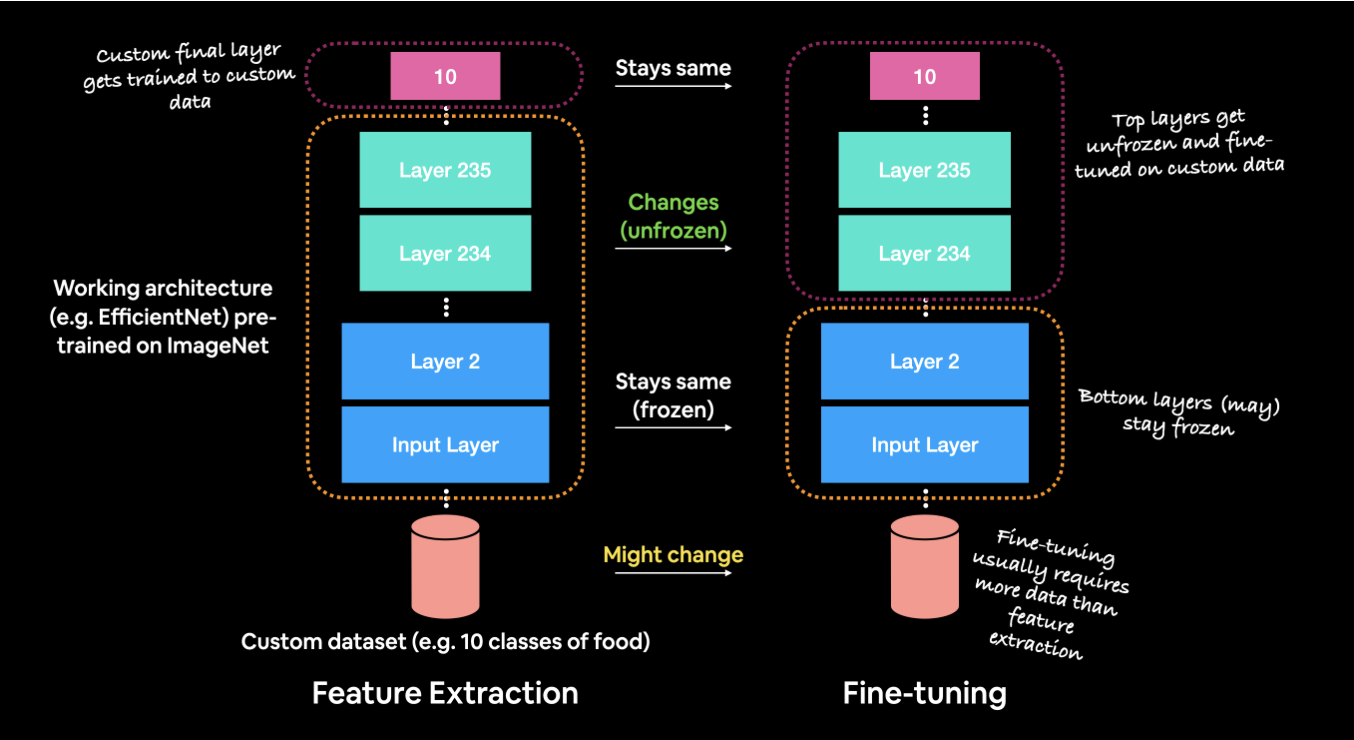
Understanding Fine-Tuning in Deep Learning Understanding Fine-Tuning in Deep Learning: A Comprehensive Overview Fine-tuning in deep learning has become a powerful technique, allowing developers to […]

What is NLP and the Math Behind It? Understanding Transformers and Deep Learning in NLP Introduction to NLP Natural Language Processing (NLP) is a crucial subfield of artificial intelligence (AI) that focuses on enabling machines to process and understand human language. Whether it’s machine translation, chatbots, or text analysis, NLP helps bridge the gap between human communication and machine understanding. But what’s behind NLP’s ability to understand and generate language? Underneath it all lies sophisticated mathematics and cutting-edge models like deep learning and transformers. This post will delve into the fundamentals of NLP, the mathematical principles that power it, and...
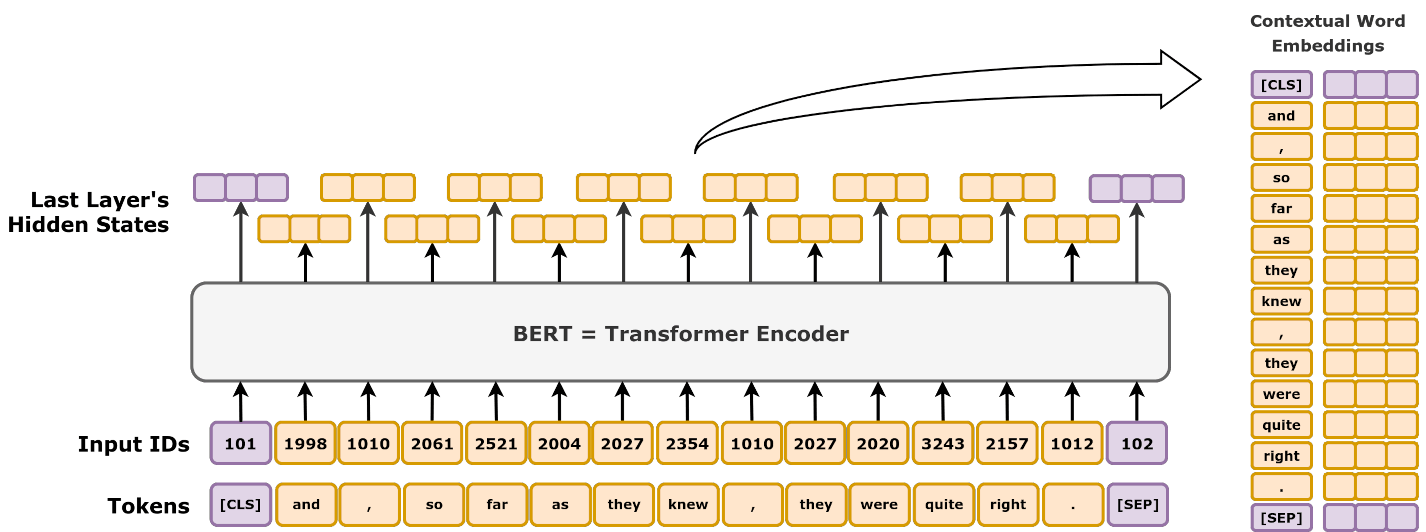
Transformer Models Comparison Feature BERT GPT BART DeepSeek Full Transformer Uses Encoder? ✅ Yes ❌ No ✅ Yes ❌ No ✅ Yes Uses Decoder? ❌ No ✅ Yes ✅ Yes ✅ Yes ✅ Yes Training Objective Masked Language Modeling (MLM) Autoregressive (Predict Next Word) Denoising Autoencoding Mixture-of-Experts (MoE) with Multi-head Latent Attention (MLA) Sequence-to-Sequence (Seq2Seq) Bidirectional? ✅ Yes ❌ No ✅ Yes (Encoder) ❌ No Can be both Application NLP tasks (classification, Q&A, search) Text generation (chatbots, summarization) Text generation and comprehension (summarization, translation) Advanced reasoning tasks (mathematics, coding) Machine translation, speech-to-text Understanding BERT: How It Works and Why...
Transformer Models Comparison Feature BERT GPT BART DeepSeek Full Transformer Uses Encoder? ✅ Yes ❌ No ✅ Yes ❌ No ✅ Yes Uses Decoder? ❌ No ✅ Yes ✅ Yes ✅ Yes ✅ Yes Training Objective Masked Language Modeling (MLM) Autoregressive (Predict Next Word) Denoising Autoencoding Mixture-of-Experts (MoE) with Multi-head Latent Attention (MLA) Sequence-to-Sequence (Seq2Seq) Bidirectional? ✅ Yes ❌ No ✅ Yes (Encoder) ❌ No Can be both Application NLP tasks (classification, Q&A, search) Text generation (chatbots, summarization) Text generation and comprehension (summarization, translation) Advanced reasoning tasks (mathematics, coding) Machine translation, speech-to-text Table 1: Comparison of Transformers, RNNs, and...
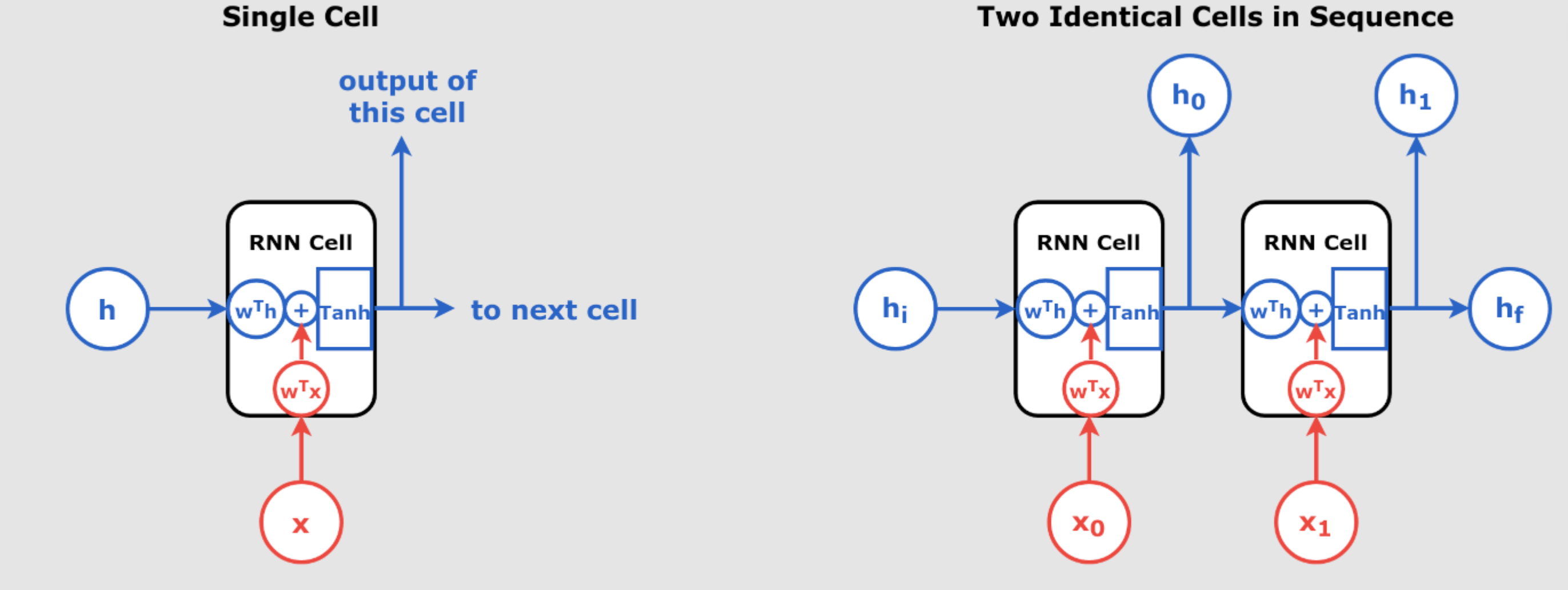
Mastering Time Series Forecasting with RNNs and Seq2Seq Models: Detailed Iterations with Calculations, Tables, and Method-Specific Features Time series forecasting is a crucial task in various domains such as finance, weather prediction, and energy management. Recurrent Neural Networks (RNNs) and Sequence-to-Sequence (Seq2Seq) models are powerful tools for handling sequential data. In this guide, we will provide step-by-step calculations, including forward passes, loss computations, and backpropagation for two iterations across three forecasting methods: Assumptions and Initial Parameters For consistency across all methods, we’ll use the following initial parameters: 1. Iterative Forecasting: Predicting One Step at a Time In iterative forecasting, the...
Step-by-Step Explanation of RNN for Time Series Forecasting Step 1: Simple RNN for Univariate Time Series Forecasting Explanation: An RNN processes sequences of data, where the output at any time step depends on both the current input and the hidden state (which stores information about previous inputs). In this case, we use a Simple RNN with only one recurrent neuron. TensorFlow Code: Numerical Example: Let’s say we have a sequence of three time steps: . 1. Input and Hidden State Initialization: The RNN starts with an initial hidden state , typically initialized to 0. Each step processes the input and...
For best results, phrase your question similar to our FAQ examples.
