How to Build a Solo-SaaS AI Marketing Engine on Google Colab
Most founders should stop asking how to train “an LLM that makes posts go viral” and start asking how to build a product-aware marketing system. Google’s own Gemma tuning guides for Colab focus on fine-tuning existing open models with QLoRA or lightweight full fine-tuning on a T4-class GPU, while Hugging Face[1] explicitly positions PEFT and TRL as the practical stack for adapting pretrained models without retraining every weight. That is the right mental model for a solo SaaS team: adapt a compact open model, connect it to your product knowledge, and use it to research channels, draft platform-native content, score ideas before publishing, and learn from results. No model can guarantee virality, because platforms increasingly reward relevance and authenticity while suppressing automated or manipulative behavior. [2]
Why most founders should not train from scratch
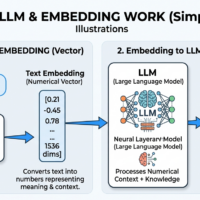
At the technical level, an LLM is still a token-prediction system built on the Transformer architecture. Google’s own machine learning material describes LLMs as models that predict a token or sequence of tokens, and Hugging Face’s language-modeling documentation says causal language modeling predicts the next token from the tokens to its left. That matters because it clarifies what you are actually buying when you fine-tune: not “marketing instinct” in the human sense, but a text engine whose behavior can be bent toward your product, audience, and style. [3]
For a solo founder, full pretraining is usually the wrong goal. PEFT exists precisely because full fine-tuning of large pretrained models is expensive; LoRA and QLoRA reduce the amount of trainable state and memory required, while bitsandbytes lowers the memory footprint further with 4-bit and 8-bit quantization. Google’s Gemma QLoRA guide for Colab says the workflow was created to run on a T4 GPU with 16 GB of memory, and the LoRA paper as well as the QLoRA paper both argue that large quality gains are possible without retraining the entire base model. [4]
In practical terms, that means a founder should choose a model family that fits the hardware and the job. Google’s guides show Gemma checkpoints running on T4-class Colab hardware; Colab’s local-runtime documentation says its Docker runtime has been tested with NVIDIA T4, L4, and A100 GPUs; and current open model cards show that Qwen2.5 Instruct, Llama 3.1 Instruct, and Mistral 7B Instruct are all realistic candidates when you have enough VRAM or a paid/local runtime. The right question is not “What is the biggest model I can brag about?” but “What is the smallest model that can reliably draft useful, grounded marketing assets for my niche?” [5]
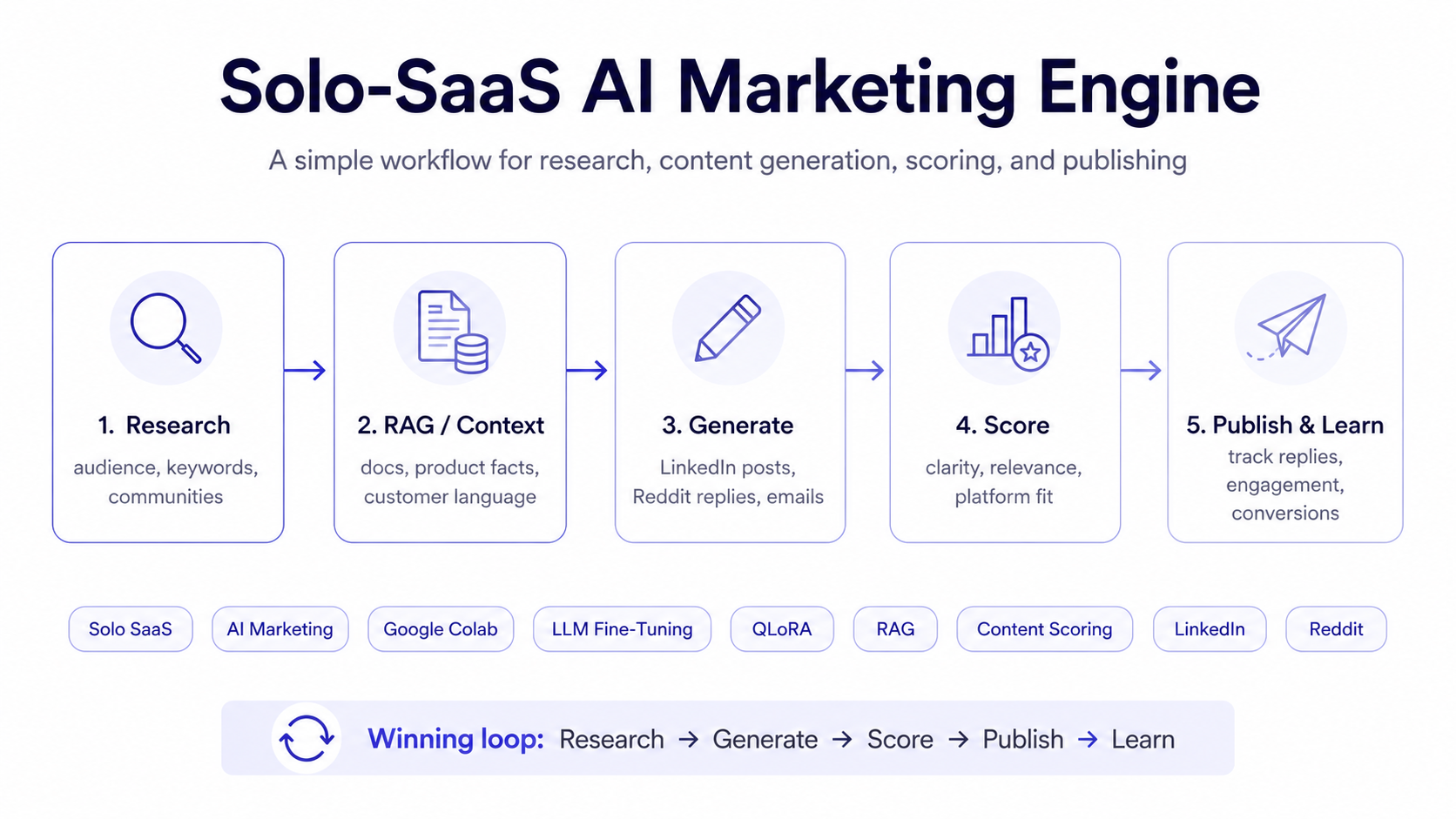
The system you should build instead
The useful version of a marketing LLM is not a chatbot that spits out generic slogans. It is a small operating system with several parts working together. First, it needs audience discovery so it can locate where the buyers already spend attention. Second, it needs retrieval so it can ground outputs in your product docs, changelogs, positioning, objections, and customer language instead of hallucinating. Third, it needs generation so it can turn the same source material into platform-native drafts for LinkedIn, Reddit, launch posts, founder updates, emails, and landing pages. Fourth, it needs scoring so it can rank multiple versions before you publish. Fifth, it needs orchestration and measurement so it can learn from results rather than produce infinite content sludge. [6]
When a marketing agency design the system this way, “where should I post?” becomes as important as “what should I write?” Audience-research and community-discovery tools now surface preferred networks, websites, subreddits, keywords, and rising conversations; retrieval-augmented generation remains the cleanest way to give the model fresh, company-specific facts; and performance-scoring products show that modern AI marketing platforms are moving toward ranking outputs before launch instead of merely generating more text. In other words, the winning architecture is research → draft → score → ship → learn, not prompt → post → pray. [7]
The most valuable training corpus for this system is usually your own material: homepage copy, onboarding emails, support tickets, demo transcripts, customer interviews, objection notes, founder stories, product comparisons, changelogs, and examples of posts that created qualified replies. That is not just a branding preference; it follows directly from the way RAG improves grounding and from the way today’s major platforms are de-emphasizing generic, low-substance, over-automated content. Your moat is not the base model. Your moat is proprietary context plus a sharp point of view. [8]
How to build it on Google Colab or one GPU
Google Colab already gives you the basic scaffolding. The official FAQ says Colab offers optional accelerated environments including GPU and TPU, and the local-runtime docs explain how to connect Colab to your own machine or remote box, including GPU-backed Docker runtimes tested on T4, L4, and A100 hardware. Google’s current Gemma examples add the most useful practical constraint: on Colab, start small enough that the notebook is stable, then scale up only after the workflow is proven. [9]
A minimal notebook skeleton example can looks like this:
!pip -q install transformers datasets accelerate bitsandbytes peft trl sentencepiece
import torch
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig
from trl import SFTTrainer, SFTConfig
BASE_MODEL = "Qwen/Qwen2.5-7B-Instruct" # swap to a smaller Gemma checkpoint on lower-VRAM Colab
bnb = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
quantization_config=bnb,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
tokenizer.pad_token = tokenizer.eos_token
examples = [
{
"messages": [
{
"role": "system",
"content": (
"You are a SaaS marketing strategist. "
"Be specific, truthful, and platform-native. "
"Never invent metrics, testimonials, or customer quotes."
),
},
{
"role": "user",
"content": (
"Product: SQL monitoring for startups\n"
"Audience: solo CTOs\n"
"Platform: LinkedIn\n"
"Goal: start qualified conversations\n"
"Assets: catches slow queries, 5-minute setup, built after founder got paged at 2am"
),
},
{
"role": "assistant",
"content": (
"Hook: I built this after getting paged at 2am for a query I should have caught earlier...\n\n"
"Body: ...\n\n"
"CTA: If you're still debugging query slowdowns manually, tell me what stack you're on."
),
},
]
}
]
dataset = Dataset.from_list(examples)
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)
train_args = SFTConfig(
output_dir="/content/marketing-llm",
learning_rate=2e-4,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=1,
logging_steps=10,
save_steps=50,
max_length=1024,
packing=False,
report_to="none",
)
trainer = SFTTrainer(
model=model,
args=train_args,
train_dataset=dataset,
peft_config=peft_config,
processing_class=tokenizer,
)
trainer.train()
trainer.model.save_pretrained("/content/marketing-llm")
tokenizer.save_pretrained("/content/marketing-llm")This notebook structure reflects the exact stack the current documentation points toward: supervised fine-tuning with SFTTrainer, parameter-efficient adapters with PEFT/LoRA, and 4-bit quantization through bitsandbytes. The key implementation detail is not the code itself; it is the training data format. Each example should encode the product, audience, platform, constraints, and the desired quality of the final asset. The model should not just learn “write a post.” It should learn “write a truthful Reddit comment for this community,” “write a LinkedIn founder post with one concrete insight,” or “write a product-launch email that sounds like us.” [10]
The other non-negotiable layer is evaluation. Pre-publish scoring is now a core product idea in AI marketing, not a side feature, and research on AI adoption keeps pointing to the importance of human validation in high-performing organizations. So a marketing model should generate several variants, score them against a rubric, and then send the top draft to a human reviewer. A good rubric should test platform fit, specificity, proof density, novelty, clarity of CTA, compliance with community norms, and whether the post teaches anything real before asking for attention. [11]
How to teach it to win distribution
If the founder audience lives on LinkedIn, the system should optimize for insight and authenticity, not tricks. LinkedIn said in March 2026 that it is upgrading feed ranking with generative recommenders and LLMs to better understand what posts are about, while also reducing generic content, engagement bait, and automated or inauthentic commenting behavior. That means any model should generate posts that feel specific to a real operator with real experience: one sharp hook, one non-obvious lesson, one concrete example, and one conversational close. What it should not do is manufacture fake debates, engagement-pod behavior, or templated “agree?” bait. [12]
If the audience lives on Reddit, the LLM must behave more like a community member than a content machine. Reddit’s own help pages say self-promotion is generally frowned upon, warn against vote manipulation and link spam, recommend that only a small minority of the participation point to the own content, and emphasize transparency about affiliation. Reddit Pro, meanwhile, now gives businesses keyword tracking, audience discovery, engagement features, and post/comment measurement for free. So the correct “Reddit marketing LLM” is not a bot that dumps links. It is a research assistant that finds relevant communities, drafts thoughtful replies in the language of each subreddit, flags when to disclose affiliation, and helps marketer participate before their promote. [13]
The broader strategic shift is toward zero-click, platform-native marketing. The logic is simple: as platforms reduce the value of outbound links and feed users more native content, standalone insight posted directly on-platform becomes more effective than teaser copy that asks people to click away. One leading 2026 marketing report makes the same point from another angle, arguing that AI is already table stakes and that brands without a clear point of view are getting lost in a flood of average AI content. For a solo founder, that means the model should prioritize native value first and traffic second. Give the best idea away in the post, then let profile clicks, replies, searches, and remembered brand affinity do the rest. [14]
Reddit Pro Trends can show where a keyword is rising in real time on Reddit. Octolens-style social listening can monitor mentions across Reddit, X, LinkedIn, GitHub, newsletters, and news. Taplio-style LinkedIn tools can surface what hooks and formats are already working in your niche. And if you read older founder advice pointing you toward GummySearch, note that GummySearch’s own site says it shut down on November 30, 2025. The lesson is that channel discovery is no longer “pick a platform and post daily.” It is a continuous intelligence loop. [15]
The companies, agencies, and marketers worth studying
Among the software platforms, Jasper[16], Copy.ai[17], and HubSpot[18] are useful because they all frame AI marketing as a workflow problem, not a prompt problem. Jasper describes itself as AI built to execute marketing end to end. Copy.ai positions its product as a GTM AI platform that codifies best practices and automates multi-step go-to-market work. HubSpot’s Breeze pitches AI tools and agents across marketing, sales, and service, including prospecting, content, and data research. The common pattern is clear: the category leaders are selling systems, governance, reuse, and distribution logic rather than isolated text generation. [19]
On the data and performance side, Clay[20], Common Room[21], Anyword[22], Taplio[23], Omneky[24], SparkToro[25], and Octolens[26] each model a piece of the stack you would want to copy into your own custom agent. Clay is about enrichment, intent, and timely action. Common Room is about buyer signals. Anyword is about scoring copy before launch. Taplio is about LinkedIn ideation, drafting, and analytics. Omneky is about generating and launching high-volume, on-brand ad creative across channels. SparkToro is about finding where an audience pays attention. Octolens is about filtering the noise out of multi-platform brand mentions. If you want your in-house model to outperform generic AI, it should imitate this modularity. [27]
On the services side, NoGood[28], Single Grain[29], and WPP[30] show how agencies are retooling around AI-native delivery. NoGood explicitly markets an AI marketing agency offering rapid experimentation, competitor analysis, SEO, content strategy, and performance branding for AI companies. Single Grain now describes itself as a modern AI-driven agency that implements AI systems and agents inside marketing operations. At the enterprise end, WPP’s Open platform and Open Pro product are aimed at helping brands plan, create, and publish campaigns with AI at scale, and Reuters reports that WPP Open Pro is being extended to smaller brands as well. [31]
This is not a toy market. Jasper announced a $125 million Series A at a $1.5 billion valuation in 2022. Reuters reported that Clay reached a $3.1 billion valuation in 2025. WPP says it is investing £250 million annually in AI, data, and technology and has embedded AI production and planning into its operating system. Reuters also reported that Klarna said generative AI was cutting its marketing costs by about $10 million annually while increasing campaign output. Those are different kinds of examples, but together they prove the same point: AI-assisted marketing is already creating billion-dollar software categories and multi-million-dollar operating leverage. [32]
If you want the famous operators behind these ideas, start with Rand Fishkin[33] and Amanda Natividad[34] for zero-click and audience-first thinking. Fishkin’s bio identifies him as the cofounder and CEO of SparkToro, and Natividad’s site says she runs Zero Click Marketing while serving as Chief Evangelist at SparkToro. For demand capture and search-driven distribution, study Neil Patel[35], whose own site says he grows Ubersuggest and his agency while using education as a distribution engine. And for the agency-operator model, study Eric Siu[36], whose company says he bought Single Grain for $2 in 2014 and turned it into a larger AI-forward growth business. These people matter not because they discovered a magic prompt, but because they built repeatable distribution systems around research, education, and execution. [37]
What will work best over the next few years
The likely winners from here are not the teams producing the most AI content. They are the teams combining proprietary product knowledge, human point of view, signal-based distribution, and controlled automation. That is the direction implied by LinkedIn’s push toward authentic professional content, Reddit’s long-standing anti-spam norms, the growing emphasis on zero-click value, and recent marketing reports arguing that AI is already the baseline while trust, distinctiveness, and good human judgment are becoming the differentiators. Inference: the next wave of winning “AI agencies” and solo-founder stacks will look less like content mills and more like compact, data-backed editorial systems. [38]
Google now offers Meridian as an open-source marketing mix model, says it is built to answer core business questions around measurement and budget actionability, and introduced a Scenario Planner in 2026 to make MMM outputs easier for marketers to use. Meta’s Robyn remains another open-source, AI/ML-powered MMM package for in-house modelers. For a small founder usually when a posts, ads, partnerships, and content channels begin to generate measurable volume, then this is how to stop a LLM from being just a copywriter and turn it into a real marketing copilot. [39]
The solo SaaS founder who wins with AI marketing will not be the one with the biggest model. It will be the one who trains a compact, grounded system on real customer language, uses retrieval for current facts, respects community rules, publishes native insight instead of generic bait, and measures what actually creates pipeline. The technology stack for that is already here on Colab and single-GPU setups. The real edge now is taste, truthfulness, audience understanding, and the discipline to turn every post into a learning loop. [40]
[1] [6] [8] [18] [33] [34] https://arxiv.org/abs/2005.11401
https://arxiv.org/abs/2005.11401
[2] [5] [23] [30] [40] https://ai.google.dev/gemma/docs/core/huggingface_text_finetune_qlora
https://ai.google.dev/gemma/docs/core/huggingface_text_finetune_qlora
[3] [26] https://developers.google.com/machine-learning/crash-course/llm/transformers
https://developers.google.com/machine-learning/crash-course/llm/transformers
[4] [20] https://huggingface.co/docs/peft/index
https://huggingface.co/docs/peft/index
[7] [15] [16] [29] https://sparktoro.com/
[9] [24] [36] https://research.google.com/colaboratory/faq.html
https://research.google.com/colaboratory/faq.html
[10] [25] https://huggingface.co/docs/trl/sft_trainer
https://huggingface.co/docs/trl/sft_trainer
[11] https://support.anyword.com/what-is-the-predictive-performance-score
https://support.anyword.com/what-is-the-predictive-performance-score
[12] [17] [22] [28] [38] How LinkedIn Is Improving the Feed to Show More Relevant, Authentic Professional Content
https://news.linkedin.com/2026/ImprovingTheFeed
[13] Reddiquette – Reddit Help
https://support.reddithelp.com/hc/en-us/articles/205926439-Reddiquette
[14] https://sparktoro.com/blog/zero-click-content-the-counterintuitive-way-to-succeed-in-a-platform-native-world/
[19] https://www.jasper.ai/
[21] [31] https://nogood.io/ai-marketing-agency/
https://nogood.io/ai-marketing-agency
[27] https://www.clay.com/
[32] https://www.jasper.ai/blog/jasper-announces-125m-series-a-funding
https://www.jasper.ai/blog/jasper-announces-125m-series-a-funding
[35] [39] https://developers.google.com/meridian
https://developers.google.com/meridian
[37] https://sparktoro.com/team/rand