In machine learning and deep learning, the concepts of Model vs Instance Models and Train-Test Split are closely intertwined. A model serves as the blueprint for learning patterns from data, while an instance model represents the specific realization of that blueprint after training. The train-test split, on the other hand, plays a critical role in the creation and evaluation of these instance models by dividing the dataset into subsets for training and testing.
This blog post will delve into the relationship between these concepts, first we explain model vs instance based and then we explain train- test spilt and provide two great examples to understand all we have explained better. These basics is mandatory to understand machine learning better:
Understanding Model-Based & Instance-Based Learning in Machine Learning
Machine learning is a transformative technology that relies on various methods to teach computers how to learn from data and make predictions. Two fundamental approaches in this domain are model-based learning and instance-based learning. This blog post delves into these two learning paradigms, their differences, and how they relate to common issues like overfitting and underfitting. We will also explore how deep learning fits into this framework.
Model-Based Learning
Definition:
Model-based learning involves creating a model that represents the underlying relationship between the features and the target variable in the training data. This model is then used to make predictions on new, unseen data.
Process:
- Training Data: The dataset containing input-output pairs.
- Model Building: The model learns from the training data by finding patterns and establishing relationships between the input features and the target variable.
- Prediction: Once the model is trained, it can predict outcomes for new data based on the learned relationships.
Example: Predicting house prices using linear regression.
- Training Data: Data about houses, including features like size, number of bedrooms, location, and their corresponding prices.
- Model Building: Using linear regression, the model finds the best-fit line that minimizes the difference between predicted prices and actual prices.
- Prediction: For a new house, the model uses the learned coefficients to predict its price based on its features.
Training Data -----> Model Training -----> Learned Model
| Size, Bedrooms, (e.g., Linear (e.g., coefficients a, b, c, d)
Location, Price | Regression) |
Advantages:
- Efficiency: Once trained, model-based approaches can make predictions quickly.
- Memory Usage: Generally requires less memory compared to instance-based methods.
Challenges:
- Overfitting: If the model is too complex, it may capture noise in the training data, leading to poor generalization on new data.
- Underfitting: If the model is too simple, it may fail to capture the underlying patterns in the data.
Instance-Based Learning
Definition:
Instance-based learning, also known as memory-based learning, uses specific instances from the training data to make predictions. It does not create a generalized model but instead relies on storing and comparing new instances to the stored examples.
Process:
- Training Data: The dataset containing input-output pairs.
- Storing Instances: All training data instances are stored without creating a model.
- Prediction: For a new instance, the algorithm compares it to stored instances using a similarity measure and makes a prediction based on the closest matches.
Example: Predicting house prices using k-Nearest Neighbors (k-NN).
- Training Data: Data about houses, including features like size, number of bedrooms, location, and their corresponding prices.
- Storing Instances: All training data is stored.
- Prediction: For a new house, k-NN finds the k most similar houses in the training data and predicts the price based on the average price of these neighbors.
Training Data -----> Store Instances -----> Query New Instance -----> Compare to Stored Instances -----> Predict Based on Nearest Neighbors
| Size, Bedrooms, (e.g., k-NN) (Find nearest neighbors, average prices)
Location, Price |
Advantages:
- Flexibility: Can capture complex relationships in the data without assuming a specific functional form.
- Simplicity: Easy to implement and understand.
Challenges:
- Efficiency: Making predictions can be slow because it involves comparing the new instance to all stored instances.
- Memory Usage: Requires storing the entire training dataset, which can be memory-intensive.
Relationship with Overfitting and Underfitting
Overfitting:
- Model-Based Learning: Overfitting occurs when the model is too complex and captures noise along with the underlying data patterns. This can be mitigated by techniques like regularization, cross-validation, and early stopping.
- Example: A polynomial regression model with too many terms fitting the training data perfectly but performing poorly on new data.
- Instance-Based Learning: Overfitting can occur if the parameter k in k-NN is too small, making the model too sensitive to the training data.
- Example: k-NN with k=1 perfectly matching training instances but failing to generalize to new instances.
Underfitting:
- Model-Based Learning: Underfitting happens when the model is too simple and fails to capture the underlying patterns in the data. Increasing model complexity or adding more features can help mitigate this issue.
- Example: A linear regression model trying to fit a complex, nonlinear dataset.
- Instance-Based Learning: Underfitting occurs when k is too large, causing the model to average out important details and fail to capture the data’s structure.
- Example: k-NN with k set too high, resulting in predictions that are overly generalized.
| Learning Type | Overfitting | Prevention Methods | Underfitting | Prevention Methods |
|---|---|---|---|---|
| Model-Based Learning | Model too complex, captures noise | Regularization, Cross-Validation, Early Stopping | Model too simple, misses patterns | Increase Complexity, Feature Engineering, Longer Training |
| Instance-Based Learning | Model too sensitive to training data | Choose appropriate k, Cross-Validation, Data Augmentation | Model too simplistic, averages out details | Choose appropriate k, Feature Scaling, Weighted Voting |
Deep Learning: A Model-Based Approach
Definition and Process:
In deep learning, model-based learning involves using neural networks, which are highly complex models that can capture intricate patterns in data. These models are trained on large datasets to learn the relationships between input features and outputs.
- Training: The neural network adjusts its weights through a process called backpropagation, where the error between the predicted and actual outputs is minimized by iteratively updating the weights.
- Prediction: Once trained, the model can make predictions on new data by passing the inputs through the network and computing the outputs based on the learned weights.
Examples:
- Image Recognition: Convolutional Neural Networks (CNNs) are trained on large datasets of labeled images. The model learns to identify features such as edges, textures, and objects at different layers.
- Natural Language Processing: Recurrent Neural Networks (RNNs) and Transformers are used for tasks like language translation and text generation. The models learn to understand and generate language by capturing the relationships between words and sentences.
Why Model-Based in Deep Learning:
- Scalability: Model-based approaches in deep learning can handle very large and complex datasets.
- Generalization: Well-regularized deep learning models can generalize well to new data, making them powerful for a variety of tasks.
- Performance: Deep learning models often achieve state-of-the-art performance in many domains, such as image recognition, natural language processing, and speech recognition.
Conclusion
In summary, deep learning predominantly relies on model-based learning due to its ability to handle large and complex datasets, learn intricate patterns, and generalize well to new data. While instance-based learning plays a lesser role, it can complement deep learning models in specific hybrid approaches. Understanding the strengths and limitations of each approach helps in designing robust and efficient machine learning systems.
By exploring these concepts and examples, you should now have a clearer understanding of model-based and instance-based learning, how they differ, and how to address common issues such as overfitting and underfitting.
Comparison Table
| Aspect | Model-Based Learning | Instance-Based Learning |
|---|---|---|
| Definition | Builds a general model by learning patterns in the training data. | Stores the training data and uses it directly for predictions. |
| Approach | Learns parameters \( \theta \) to generalize to unseen data. | Relies on similarity or distance measures to make predictions. |
| Training Phase | Computationally intensive; involves optimization algorithms. | Minimal or none; “lazy” learning. |
| Prediction Phase | Fast; uses the trained model for direct computation. | Slower; compares new data to stored instances. |
| Mathematical Basis |
Optimization-based: Finds parameters by minimizing a loss function \( L(y, \hat{y}) \):
|
Similarity-based: Computes closeness between instances using metrics like:
|
| Examples | Linear Regression, Logistic Regression, Neural Networks, Decision Trees | k-Nearest Neighbors (k-NN), Case-Based Reasoning |
| Flexibility | Fixed after training; needs retraining to adapt to new data. | Highly flexible; adapts to new data without retraining. |
| Use Cases | Image classification, Time-series forecasting, Sentiment analysis | Recommendation systems, Dynamic, rapidly changing datasets |
As Next, Lets Understand Train-Test Split in Machine Learning
The train-test split is a fundamental concept in machine learning that ensures models are evaluated effectively and can generalize well to new, unseen data. This technique is used in both model-based and instance-based learning approaches. Here’s a comprehensive guide to understanding this process, including detailed examples.
What is a Train-Test Split?
Train-Test Split:
- Training Set: Typically 70-80% of the dataset used to train the model.
- Test Set: The remaining 20-30% of the dataset used to evaluate the model’s performance.
Purpose:
- Training Set: Allows the model to learn patterns from the data.
- Test Set: Evaluates how well the model performs on unseen data, ensuring it generalizes well.
How to Create the Train-Test Split
- Prepare the Data: Start with your complete dataset.
- Randomly Shuffle: Shuffle the dataset to ensure it’s randomly distributed. This prevents any inherent order from influencing the split.
- Split the Data:Training Set: Select 80% of the data for training.
- Test Set: Select the remaining 20% for testing.
Example:
Imagine you have a dataset with 1000 samples.
- Training Set: 800 samples (80% of 1000)
- Test Set: 200 samples (20% of 1000)
Python Code Example:
Here’s how you can perform the split using Python’s Scikit-Learn library:
from sklearn.model_selection import train_test_split
# Example dataset
X = [[size1, bedrooms1, location1], [size2, bedrooms2, location2], ...]
y = [price1, price2, ...]
# Split the data into training and test sets (80-20 split)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Applying the Split to Model-Based Learning
Model-Based Learning:
- Training Phase: The model (e.g., linear regression) is trained on the training set. It learns the relationship between the input features and the target variable.
- Evaluation Phase: The trained model is evaluated on the test set to measure its performance and generalization ability.
Detailed Example:
Consider a linear regression model for predicting house prices:
- Dataset: 1000 samples with features (size, bedrooms, location) and target (price).
- Shuffle: Randomly shuffle the dataset.
- Split:Training Set: 800 samples
- Test Set: 200 samples
- Train the Model: Fit the linear regression model on the training set.
- Evaluate the Model: Use the test set to evaluate the model’s performance by comparing predicted prices to actual prices.
Python Code:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Sample data
X = [[size1, bedrooms1, location1], [size2, bedrooms2, location2], ...]
y = [price1, price2, ...]
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
Evaluation:
Mean Squared Error (MSE): Measures the average squared difference between predicted and actual values. Lower MSE indicates better performance.
Applying the Split to Instance-Based Learning
Instance-Based Learning:
- Training Phase: Store the training instances without creating a generalized model.
- Evaluation Phase: For each test instance, the model compares it to the stored training instances using a similarity measure to make a prediction.
Detailed Example:
Consider a k-Nearest Neighbors (k-NN) model for predicting house prices:
- Dataset: 1000 samples with features (size, bedrooms, location) and target (price).
- Shuffle: Randomly shuffle the dataset.
- Split:Training Set: 800 samples
- Test Set: 200 samples
- Store Instances: Store the training data instances.
- Evaluate the Model: For each test instance, find the k-nearest neighbors in the training set and predict the price based on their average price.
Python Code:
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Sample data
X = [[size1, bedrooms1, location1], [size2, bedrooms2, location2], ...]
y = [price1, price2, ...]
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model (storing instances)
model = KNeighborsRegressor(n_neighbors=3)
model.fit(X_train, y_train)
# Predict and evaluate
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
Evaluation:
Mean Squared Error (MSE): Measures the average squared difference between predicted and actual values. Lower MSE indicates better performance.
Why Use an 80-20 Split?
Reasons for the 80-20 Split:
- Balance: The 80-20 split provides a good balance between having enough data to train the model effectively and having enough data to evaluate the model’s performance reliably.
- Sufficient Training Data: Ensures the model has enough examples to learn the patterns in the data.
- Reliable Evaluation: Provides a substantial test set to assess the model’s generalization capability.
Flexibility:
The split ratio can be adjusted (e.g., 70-30, 90-10) based on the dataset size and specific needs of the task. Larger datasets might allow for smaller test sets, while smaller datasets might require larger test sets for robust evaluation.
Conclusion
The train-test split is a crucial step in both model-based and instance-based learning. It ensures that the model is trained on a substantial portion of the data and evaluated on a separate set to assess its performance on unseen data. By understanding and implementing this technique, you can build more reliable and generalizable machine learning models.
Let’s see this explanation in code based models :
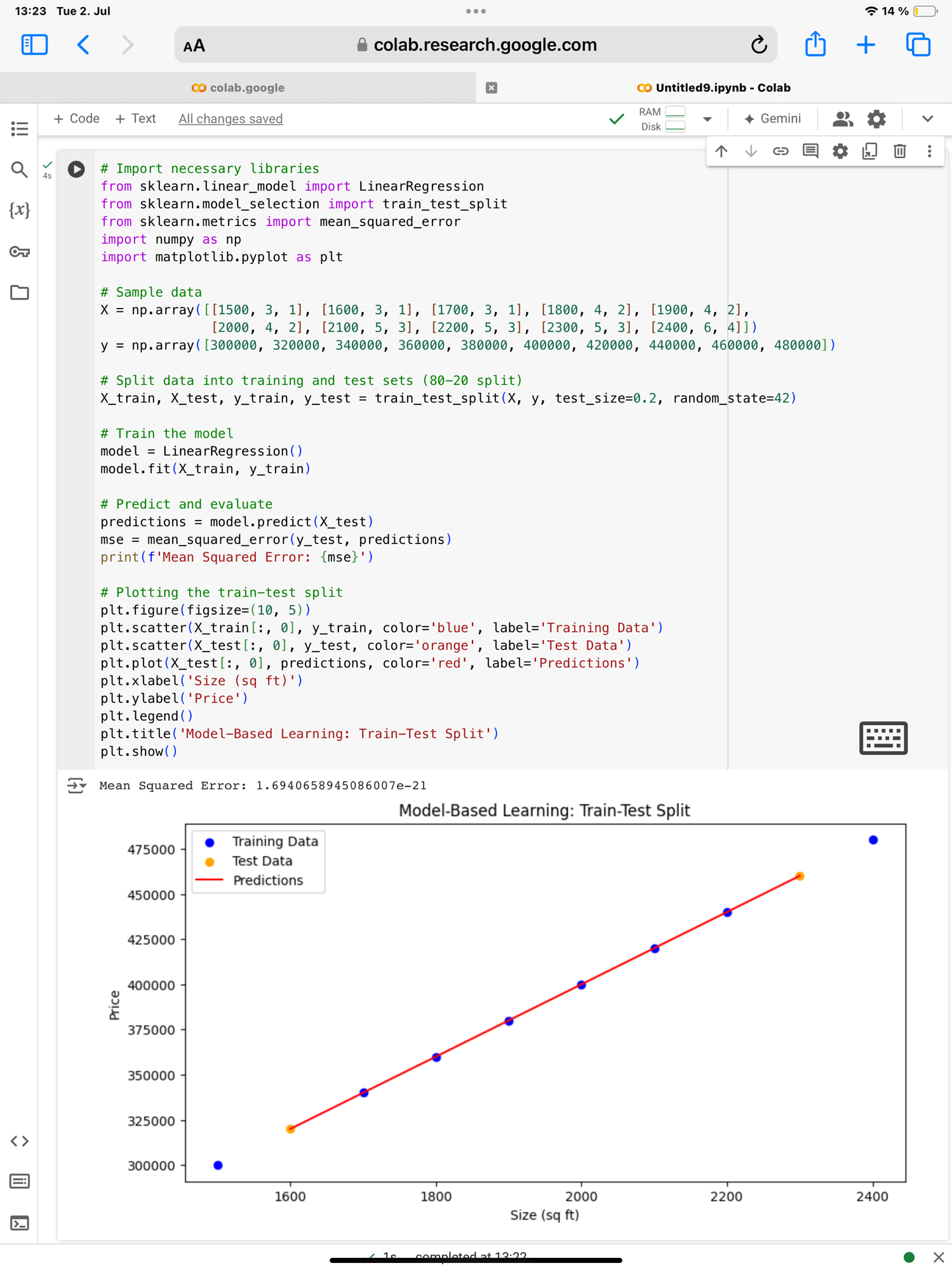
Image 1: This plot represents the results of a model-based learning approach using linear regression on a dataset of house prices.
1. Train-Test Split Rule:
• The data is split into training and test sets using the train_test_split function with an 80-20 split (test_size=0.2). This means 80% of the data is used to train the model, and 20% is used to test the model’s performance on unseen data.
• random_state=42 ensures that the data is split the same way every time the code is run, making the results reproducible.
2. Data Points:
• Blue Dots: Represent the training data used to train the linear regression model. Each dot corresponds to a house with specific features (size in sq ft, number of bedrooms, and bathrooms) and its price.
• Orange Dots: Represent the test data, which is not used in training but is used to evaluate the model’s performance. Each dot corresponds to a house with specific features and its actual price.
• Red Line: Represents the predicted house prices for the test data based on the linear regression model. This line is generated by the model using the relationship it learned from the training data.
3. Interpreting the Plot:
• The red line indicates the model’s predictions for house prices based on the test data features.
• The proximity of the orange dots to the red line shows how well the model is predicting the house prices. If an orange dot is close to the red line, the model’s prediction is close to the actual price.
• The blue dots that are far from the red line are outliers or high-leverage points in the training data. These indicate that the model did not fit these training points well, possibly due to noise or errors in the data, or because the linear model is too simple to capture the complexity of the data.
4. Mean Squared Error (MSE):
• The MSE value is printed (Mean Squared Error: 1.6940658945086007e-21), indicating the average squared difference between the actual and predicted prices. A lower MSE suggests better model performance.
Summary:
• The train-test split helps in evaluating the model’s performance by providing a separate dataset for testing. The visualization shows that the model predictions (red line) closely follow the test data (orange dots), indicating good performance except for the outliers in the training data.
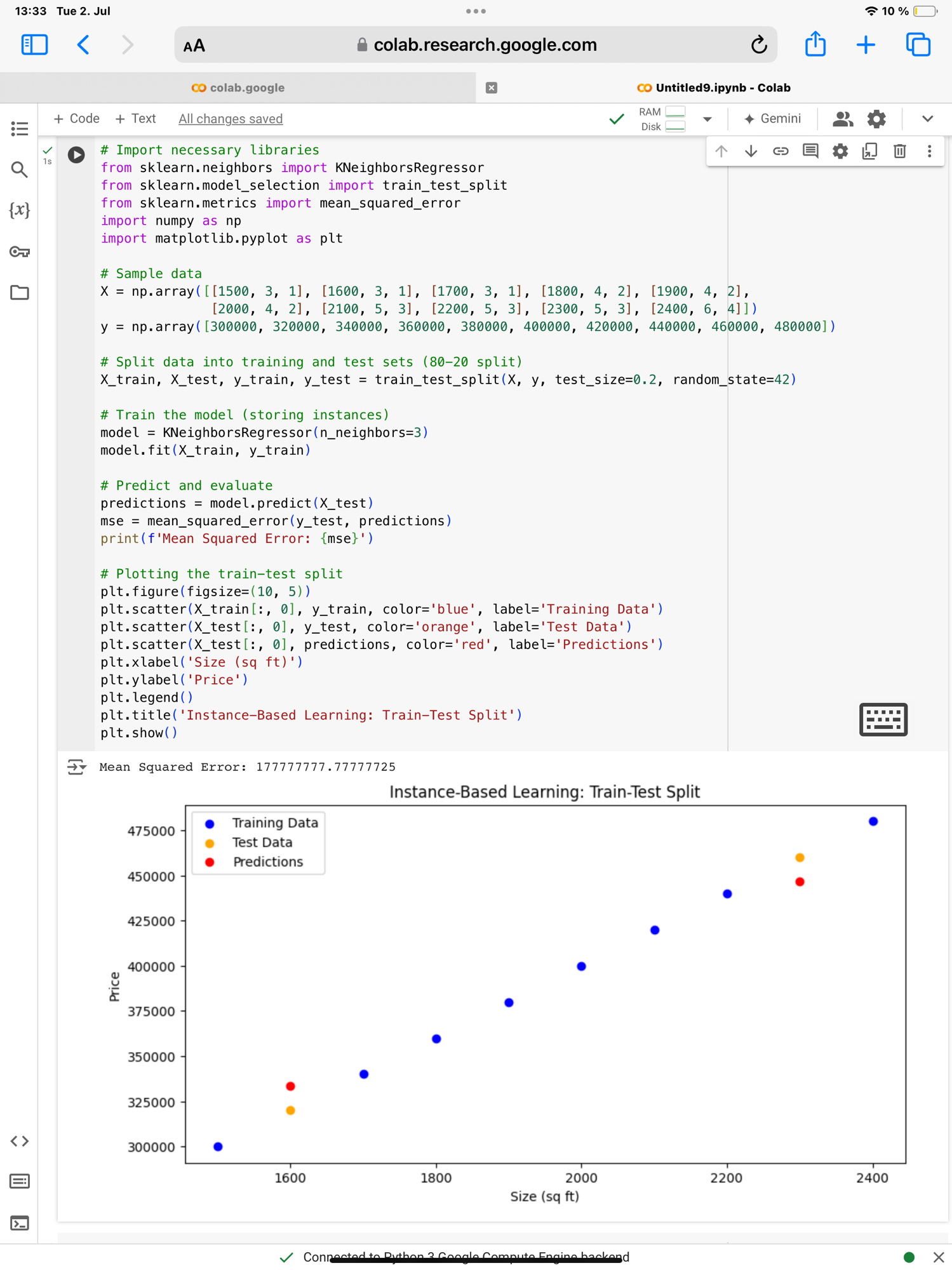
Image 2: This plot represents the results of an instance-based learning approach using k-Nearest Neighbors (k-NN) on a dataset of house prices.
1. Train-Test Split Rule:
• The data is split into training and test sets using the train_test_split function with an 80-20 split (test_size=0.2). This means 80% of the data is used to store instances for the model, and 20% is used to test the model’s performance on unseen data.
• random_state=42 ensures that the data is split the same way every time the code is run, making the results reproducible.
2. Data Points:
• Blue Dots: Represent the training data used to store instances in the k-NN model. Each dot corresponds to a house with specific features (size in sq ft, number of bedrooms, and bathrooms) and its price.
• Orange Dots: Represent the test data, which is not used in training but is used to evaluate the model’s performance. Each dot corresponds to a house with specific features and its actual price.
• Red Dots: Represent the predicted house prices for the test data based on the k-NN model. These predictions are generated by finding the k nearest neighbors in the training data and averaging their prices.
3. Interpreting the Plot:
• The red dots indicate the model’s predictions for house prices based on the test data features.
• The proximity of the red dots to the orange dots shows how well the model is predicting the house prices. If a red dot is close to an orange dot, the model’s prediction is close to the actual price.
• The blue dots that are far from the red dots indicate training points that the k-NN model used for prediction. The distance between the red and orange dots shows the prediction error.
4. Mean Squared Error (MSE):
• The MSE value is printed (Mean Squared Error: 177777777.77777775), indicating the average squared difference between the actual and predicted prices. A higher MSE suggests worse model performance compared to the linear regression model.
Summary of the two examples:
From the two examples you could learn that, The train-test split helps in evaluating the model’s performance by providing a separate dataset for testing. The visualization shows that the model predictions (red dots) generally follow the trend of the test data (orange dots), but the higher MSE indicates that the k-NN model’s predictions are less accurate than those of the linear regression model. The large gaps between some red and orange dots highlight areas where the model’s predictions are significantly off. By Comparing the two images in these 2 examples you can understand the Molde based and instance based models better. This comparison highlights that:
Model-based learning is more effective in cases where the dataset has a clear, linear relationship or when generalization is essential for unseen data.
Instance-based learning can perform better in datasets with complex, nonlinear relationships or when the data dynamically changes, but its accuracy heavily depends on the density and quality of the training data.
Thus, these examples show that while model-based approaches like linear regression may often produce lower errors, it is not always the case, as the choice between model-based and instance-based learning depends on the nature of the data, the problem being solved, and the model’s ability to generalize effectively.