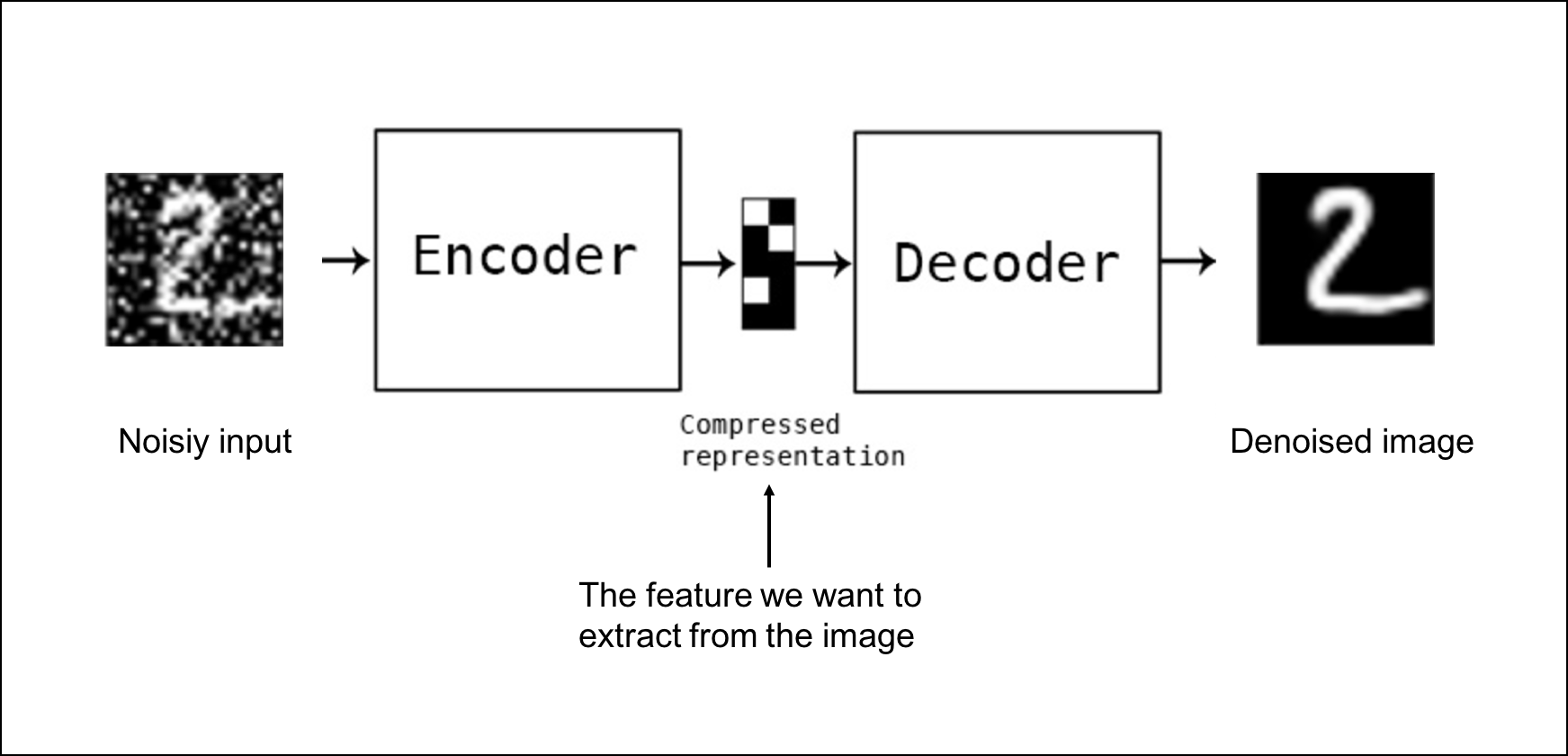
Understanding Autoencoders, GANs, and Diffusion Models – A Deep Dive In this post, we’ll explore three key models in machine learning: Autoencoders, GANs (Generative Adversarial Networks), and Diffusion Models. These models, used for unsupervised learning, play a crucial role in tasks such as dimensionality reduction, feature extraction, and generating realistic data. We’ll look at how each model works, their architecture, and practical examples. What Are Autoencoders? Autoencoders are neural networks designed to compress input data into dense representations (known as latent representations) and then reconstruct it back to the original form. The goal is to minimize the difference between the input and the reconstructed data. This technique is extremely useful for: Dimensionality Reduction: Autoencoders help in reducing the dimensionality of high-dimensional data, while preserving the important features. Feature Extraction: They can act as feature detectors, helping with tasks like unsupervised learning or as part of a larger model. Generative Models: Autoencoders can generate new data that closely resemble the training data. For example, an autoencoder trained on face images can generate new face-like images. Key Concepts in Autoencoders Component Description Encoder Compresses the input into a lower-dimensional representation. Decoder Reconstructs the original data from the compressed representation. Reconstruction Loss The difference between the original input and the output; minimized during training. Link to Autoencoder Image to Understand Better (Copy and paste the link if it doesn’t open directly: https://www.analyticsvidhya.com/wp-content/uploads/2020/01/autoencoders) In the image of the given above link , you can see the architecture of a simple autoencoder. The encoder compresses the input into a smaller representation, and the decoder tries to reconstruct it. The goal is to minimize the reconstruction loss. Generative Adversarial Networks (GANs) GANs take generative models to the next level. They consist of two neural networks: Generator: The network that generates new data (e.g., synthetic images). Discriminator: The network that evaluates the data, determining whether it is real or generated. The generator and discriminator are in a constant battle. The generator tries to fool the discriminator by producing fake data, while the discriminator gets better at spotting fake data. This adversarial relationship helps improve both networks over time, resulting in highly realistic synthetic data. How GANs Work: The generator creates synthetic data. The discriminator evaluates the data and determines if it’s real or fake. The networks improve as they continue to challenge each other during training. Component Role Generator Creates fake data based on the training set. Discriminator Classifies data as real or fake. Link to GAN Architecture Image to Understand Better (Copy and paste the link if it doesn’t open directly: https://developers.google.com/machine-learning/gan) In the figure of the above given link, you see the adversarial relationship between the generator and discriminator. As the generator gets better at producing realistic data, the discriminator becomes more skilled at identifying fake data. This adversarial process leads to the generation of highly realistic synthetic data, making GANs a popular tool in AI art, video game graphics, and even deepfake videos. Link to Explore GANs in Action (Generates Realistic Human Faces) (Copy and paste the link if it doesn’t open directly: https://thispersondoesnotexist.com) This website showcases GANs in action, generating highly realistic human faces that don’t exist in reality. Diffusion Models A newer addition to the generative model family is the diffusion model. Introduced in 2021, these models generate more diverse and higher-quality images compared to GANs, but they are slower to train. How Diffusion Models Work: Diffusion models gradually add noise to an image, and then learn to remove that noise bit by bit. Essentially, the model learns how to denoise images, which can generate new images with higher quality over time. Strength Weakness Produces higher-quality images Slower to train Easier to train than GANs Link to Diffusion Model Image to Understand Better (Copy and paste the link if it doesn’t open directly: https://www.google.com/url?sa=t&source=web&rct=j&opi=89978449&url=https://colab.research.google.com/drive/1sjy9odlSSy0RBVgMTgP7s99NXsqglsUL%3Fusp%3Dsharing&ved=2ahUKEwjet5eyh6KJAxXXSPEDHR1LC4IQFnoECBQQAQ&usg=AOvVaw2I3IGWlh5DKlkjsPV4D1N) This image demonstrates how noise is progressively added to an image during the diffusion process, and the model is trained to reverse this process, generating clean, high-quality images. Real-world Application: Super-resolution: Diffusion models are often used to enhance the resolution of images. Creative Industries: These models are also applied in generative art and animation. Comparison of Autoencoders, GANs, and Diffusion Models Feature Autoencoders GANs Diffusion Models Training Type Unsupervised Adversarial (Unsupervised) Unsupervised Generative Capabilities Limited (compared to GANs) High-quality data generation Higher quality than GANs but slower Common Use Cases Dimensionality reduction, noise removal Synthetic data, image generation Image denoising, super-resolution A Practical Example of Implementing Autoencoders in TensorFlow Autoencoders play a crucial role in machine learning for tasks like dimensionality reduction, data compression, and unsupervised pretraining. Let’s walk through an actual implementation in TensorFlow to illustrate their functionality. Building a Simple Autoencoder To begin, let’s construct a…
Unlock the Secrets of Autoencoders, GANs, and Diffusion Models – Why You Must Know Them? -Day 73