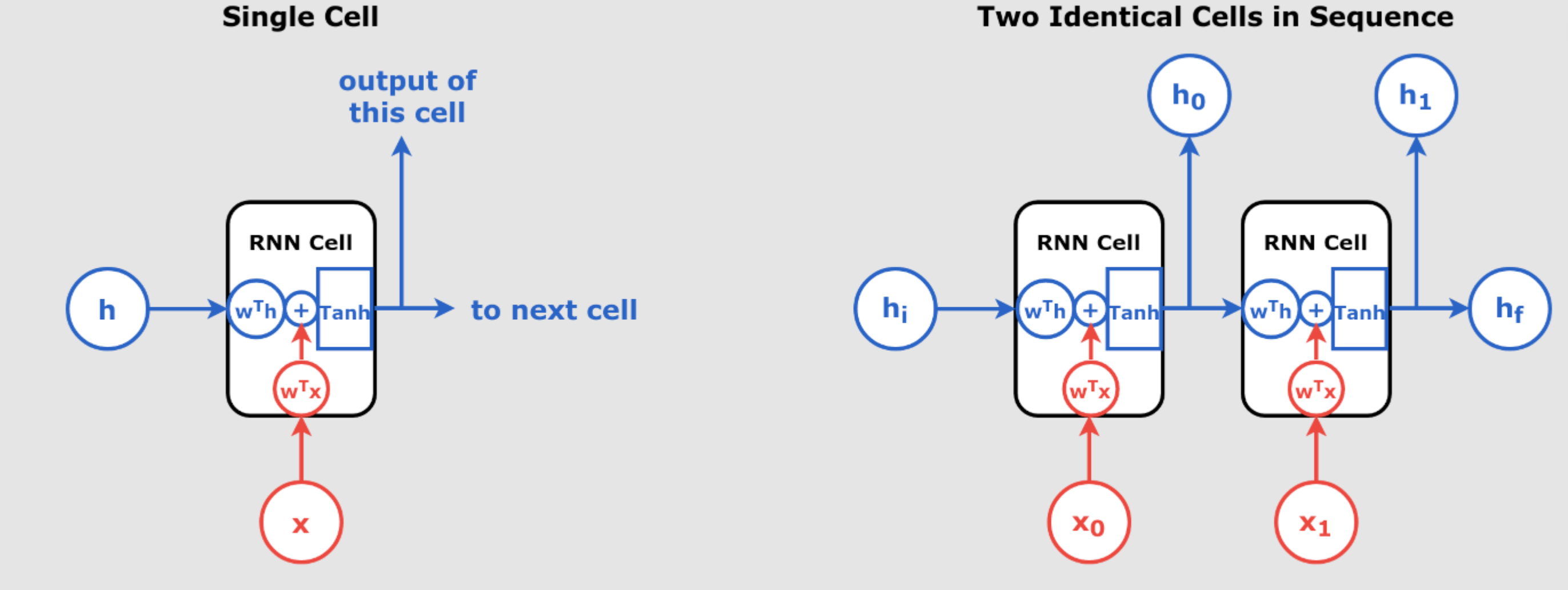
Understanding Recurrent Neural Networks (RNNs) Recurrent Neural Networks (RNNs) are a class of neural networks that excel in handling sequential data, such as time series, text, and speech. Unlike traditional feedforward networks, RNNs have the ability to retain information from previous inputs and use it to influence the current output, making them extremely powerful for tasks where the order of the input data matters. In day 55 article we have introduced RNN. In this article, we will explore the inner workings of RNNs, break down their key components, and understand how they process sequences of data through time. We’ll also dive into how they are trained using Backpropagation Through Time (BPTT) and explore different types of sequence processing architectures like Sequence-to-Sequence and Encoder-Decoder Networks. What is a Recurrent Neural Network (RNN)? At its core, an RNN is a type of neural network that introduces the concept of “memory” into the model. Each neuron in an RNN has a feedback loop that allows it to use both the current input and the previous output to make decisions. This creates a temporal dependency, enabling the network to learn from past information. Recurrent Neuron: The Foundation of RNNs A recurrent neuron processes sequences by not only considering the current input but also the output from the previous time step. This memory feature allows RNNs to preserve information over time, making them ideal for handling sequential data. In mathematical terms, a single recurrent neuron at time t receives: X(t), the input vector at time t ŷ(t-1), the output vector from the previous time step The output of a recurrent neuron at time t is computed as: Where: is the weight matrix applied to the input at time is the weight matrix applied to the previous output is an activation function (e.g., ReLU or sigmoid) is a bias term This equation illustrates how the output at any given time step depends not only on the current input but also on the outputs of previous time steps, allowing the network to “remember” past information. Unrolling Through Time To train an RNN, the recurrent neuron can be unrolled through time, meaning that we treat each time step as a separate layer in a neural network. Each layer passes its output to the next one. By unrolling the network, we can visualize how RNNs handle sequences step-by-step. For example, if a sequence is fed into the network, the recurrent neuron produces a sequence of outputs , with each output influenced by both the current input and previous outputs. Layers of Recurrent Neurons In practical applications, we often stack multiple recurrent neurons to form a layer. In this case, the inputs and outputs become vectors, and the network maintains two sets of weights: , connecting the inputs at time , connecting the previous outputs The output for a layer of recurrent neurons in a mini-batch is computed as: Where: is the input at time step is the output from the previous time step and are weight matrices is a bias vector Memory Cells: A Step Toward Long-Term Dependencies While simple RNNs are capable of learning short-term dependencies, they often struggle to capture longer-term patterns in data. To address this limitation, more advanced RNN architectures introduce Memory Cells like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs). In these architectures, the network maintains a hidden state at time step , which is a function of both the current input and the previous hidden state: This hidden state serves as a memory that can retain relevant information for many time steps, allowing the network to capture long-term dependencies in sequential data. Recent advancements have further enhanced LSTM capabilities. Innovations such as the Exponential Gating mechanism and enhanced memory structures have been introduced to address some of the traditional limitations of LSTMs, like limited storage capacity and adaptability. These developments have expanded the applicability of LSTMs, enabling them to handle more complex data patterns and longer sequences with greater efficiency. Cyber Sapient Sequence-to-Sequence and Encoder-Decoder Networks RNNs are highly versatile and can be used in various architectures to solve different tasks. Here are some common RNN architectures: Sequence-to-Sequence Networks In a Sequence-to-Sequence network, the model takes a sequence of inputs and produces a sequence of outputs. For example, this type of network could be used for machine translation, where the input is a sequence of words in one language, and the output is the translation in another language. Sequence-to-Vector Networks In a Sequence-to-Vector network, the model processes a sequence of inputs but only produces a single output at the end. This architecture is often used for sentiment analysis, where the network processes an entire sentence (a sequence) and outputs a single…
Understanding Recurrent Neural Networks (RNNs) – part 2 – Day 56