Transformers in Deep Learning (2024): Types, Advances, and Mathematical Foundations
Transformers have transformed the landscape of deep learning, becoming a fundamental architecture for tasks in natural language processing (NLP), computer vision, and beyond. Since their inception in the 2017 paper “Attention is All You Need” by Vaswani et al., transformer architectures have continuously evolved, resulting in a variety of specialized models optimized for different applications. This article reviews the essential types of transformers, their core mathematical principles, and their applications in 2024, supplemented by recent scientific insights.

1. Understanding the Standard Transformer
Purpose
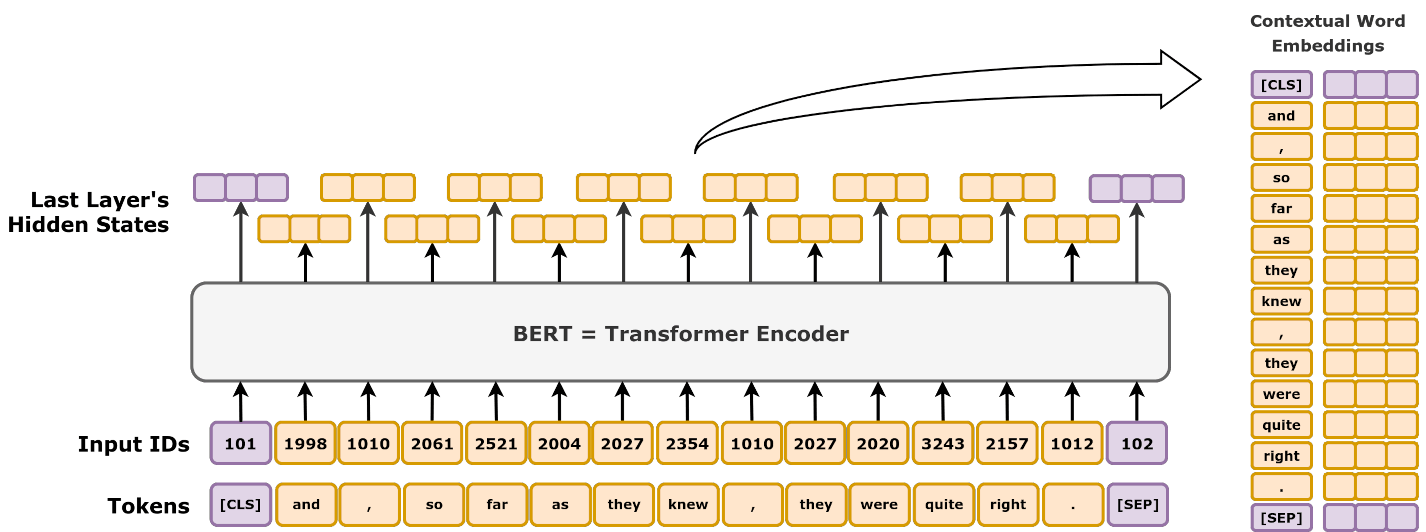
The standard transformer, introduced by Vaswani et al., set the stage for modern transformer architectures. It employs a unique self-attention mechanism, allowing it to process sequences in parallel without relying on recurrence, unlike RNNs and LSTMs.
Use Case
The original transformer design is suited for a broad range of tasks, including machine translation, summarization, and sequence modeling.
Mathematics Behind It
The standard transformer utilizes key components:
- Self-Attention Mechanism: The self-attention layer calculates attention scores by processing query (Q), key (K), and value (V) matrices for each token:
Q = XW_Q, K = XW_K, V = XW_V
Attention(Q, K, V) = softmax(QK^T / √d_k)V
where W_Q, W_K, and W_V are learned weight matrices, and d_k is the key dimension. - Multi-Head Attention: This component enables the model to attend to information from different representation subspaces:
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W_O
Each head i is calculated ashead_i = Attention(QW_Q_i, KW_K_i, VW_V_i), where W_Q_i, W_K_i, and W_V_i are projections for each attention head.
Example:
import torch import torch.nn as nn model = nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048) src = torch.rand((10, 32, 512)) tgt = torch.rand((20, 32, 512)) output = model(src, tgt)
2. Vision Transformer (ViT)
The Vision Transformer (ViT), introduced by Dosovitskiy et al. in “An Image is Worth 16×16 Words”, adapted the transformer architecture for computer vision tasks. ViTs have shown competitive performance in image classification, object detection, and segmentation by treating image patches as tokens, similar to words in NLP.
Mathematics Behind ViT
ViT divides an image into fixed-size patches, flattens each into a vector, and applies the transformer mechanism. The positional encodings are added to retain spatial information.
- Patch Embedding:
Number of patches = (H x W) / P^2
Example:
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, dim=768):
super(VisionTransformer, self).__init__()
num_patches = (img_size // patch_size) ** 2
patch_dim = 3 * patch_size ** 2
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.transformer = nn.Transformer(d_model=dim, nhead=12, num_encoder_layers=12)
def forward(self, img):
# Patch embedding and transformer steps
pass
3. Hybrid SSM-Transformer (Jamba)
Purpose: Jamba is a large-scale language model introduced by AI21 Labs. It combines state space models (SSMs) with transformers, allowing extended context handling (up to 256,000 tokens). The integration of SSMs helps capture temporal dependencies effectively, while the transformer layers maintain parallel processing power.
For further reading, see “Jamba: A Large Language Model with Hybrid SSM-Transformer Architecture”.
Example (Conceptual):
class HybridSSMTransformer(nn.Module):
def __init__(self, d_model=512, ssm_dim=256):
super(HybridSSMTransformer, self).__init__()
self.ssm = nn.Linear(ssm_dim, ssm_dim)
self.transformer = nn.Transformer(d_model=d_model, nhead=8)
def forward(self, src, tgt):
ssm_output = self.ssm(src)
transformer_output = self.transformer(ssm_output, tgt)
return transformer_output
4. Convolutional Transformer (Hyena)
Hyena introduces a unique twist by using convolutional layers instead of traditional self-attention, which allows it to process long contexts with linear rather than quadratic complexity. It was designed to efficiently handle long-context processing without the resource demands of traditional transformers. See “Efficient Long-Context Processing with Hyena”.
Example:
class HyenaModel(nn.Module):
def __init__(self, input_dim=512, hidden_dim=2048, kernel_size=3):
super(HyenaModel, self).__init__()
self.conv1 = nn.Conv1d(input_dim, hidden_dim, kernel_size, padding=1)
self.conv2 = nn.Conv1d(hidden_dim, input_dim, kernel_size, padding=1)
def forward(self, x):
x = x.transpose(1, 2)
x = self.conv1(x).relu()
return self.conv2(x).transpose(1, 2)
5. GLU-Based Vision Transformer (Activator)
Activator, a vision transformer using Gated Linear Units (GLUs), is tailored for image processing. GLUs act as gates within layers to control information flow, reducing computational costs while retaining accuracy. For a comprehensive understanding, refer to “Activator: A Vision Transformer with GLU”.
Example:
class GLUTransformerLayer(nn.Module):
def __init__(self, d_model=512, dim_feedforward=2048):
super(GLUTransformerLayer, self).__init__()
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
gate = self.sigmoid(self.linear1(x))
return self.linear2(x * gate)
Lets go through each again with more explanation
1. Standard Transformer (Vaswani et al., 2017)
Purpose
The standard transformer, introduced by Vaswani et al., was designed to handle sequences without recurrence, making it highly efficient for tasks such as translation, summarization, and sequence modeling.
Mathematics
Self-Attention Mechanism: The self-attention layer calculates relationships between tokens using query (Q), key (K), and value (V) matrices:
Attention(Q, K, V) = softmax(QKT / √d_k) V
Multi-Head Attention: Multiple attention heads allow the model to focus on different representation subspaces:
Pre-training & Use Case
This general-purpose model is pre-trained on large datasets for translation tasks, then fine-tuned for specific purposes like summarization or question answering.
Example
In machine translation, transformers capture context by self-attending to words across the sentence, translating complex phrases without relying on sequence order.
2. Vision Transformer (ViT) by Dosovitskiy et al., 2020
Purpose
ViT adapts the transformer for computer vision, treating image patches as tokens, challenging CNNs by offering a globally attentive model for image processing tasks like classification, detection, and segmentation.
Mathematics
Patch Embedding: Images are divided into patches (e.g., 16×16 pixels), flattened, and embedded:
Self-Attention: Each patch (token) interacts with other patches, capturing global spatial relationships.
Pre-training & Use Case
ViT models are pre-trained on large image datasets (e.g., ImageNet) and fine-tuned on specific visual tasks, such as object recognition.
Example
In image classification, ViT attends to global features across the image, distinguishing objects more effectively than traditional CNNs.
3. Hybrid SSM-Transformer (Jamba by AI21 Labs)
Purpose
Jamba integrates State Space Models (SSMs) with transformers, allowing better temporal modeling for language tasks needing extensive context (up to 256,000 tokens).
Mathematics
SSM Component: An SSM layer models temporal relationships, acting as a recurrent component.
Pre-training & Use Case
Pre-trained on extensive language corpora, Jamba is ideal for tasks like long-form document analysis or summarization where context from distant tokens is essential.
Example
Jamba might be used for summarizing lengthy legal documents, where early text informs later understanding.
4. Convolutional Transformer (Hyena)
Purpose
Hyena uses convolutional layers instead of self-attention, enabling linear complexity suitable for tasks needing efficient long-context processing, such as audio modeling.
Mathematics
Convolutional Layers: Hyena replaces self-attention with convolutions, reducing computational complexity:
Output = Conv1D(x)
Pre-training & Use Case
Pre-trained on audio data, Hyena excels in real-time audio tasks where efficiency and long-range dependencies are key.
Example
Hyena processes long audio files, focusing on local and global patterns without high memory demands.
5. GLU-Based Vision Transformer (Activator)
Purpose
Activator is a vision transformer optimized with Gated Linear Units (GLUs), reducing computational costs while retaining accuracy.
Mathematics
Gated Linear Units (GLUs): GLUs use a gating mechanism to modulate information flow, improving efficiency:
Pre-training & Use Case
Pre-trained on image datasets with GLU layers, Activator is ideal for image recognition tasks that require efficient computation.
Example
Activator could be used in medical imaging, focusing on critical features in X-rays or MRIs for efficient diagnosis.
Conclusion: Choosing the Right Transformer Model
1. Are All These Models Transformers, and Why?
Yes, all these models are variations of the transformer architecture because they use the core components of transformers, particularly self-attention and layered encoders/decoders. However, each model introduces specific modifications to adapt the transformer structure to different tasks or domains, like vision or long-context processing. These changes enhance the model’s suitability for its target domain and often result in a new model name that reflects its specific function or innovation.
2. Are All These Models Pre-Trained?
Yes, these models are typically pre-trained on large datasets related to their respective domains. For example, the Standard Transformer is pre-trained on large text datasets for general language tasks, while Vision Transformers (ViTs) are pre-trained on image datasets. Pre-training allows each model to learn foundational features in its domain, which makes it easier to fine-tune the model for specific tasks.
3. Can We Use These Models by Fine-Tuning?
Fine-tuning is commonly used to adapt a pre-trained model to specific tasks by further training on a smaller, specialized dataset. For instance:
- Text and Language Tasks: A pre-trained transformer like BERT can be fine-tuned for tasks such as sentiment analysis or translation.
- Vision Tasks: ViTs can be fine-tuned on specific image datasets, such as medical or satellite imagery.
- Long-Context Tasks: Models like Jamba can be fine-tuned on data requiring extensive context, such as legal documents or academic papers.
4. How Do We Know Which Model to Use?
The choice of model depends on the type of data and the task requirements:
- Text and Language Tasks: The Standard Transformer is versatile for most language tasks, but for tasks requiring extensive context, a hybrid model like Jamba may be more effective.
- Image Processing: Vision Transformers (ViT) or GLU-based Vision Transformers like Activator are better suited for visual tasks such as object recognition.
- Long-Context Processing: Hyena or Jamba, which are optimized for long sequences, are useful for applications needing efficient processing of long documents or audio streams.
5. Why Are the Mathematical Changes Important for Each Model?
Each model includes unique mathematical or architectural modifications that make it more effective for specific tasks:
- Standard Transformer: The original transformer’s multi-head self-attention and positional encoding are ideal for text sequences where understanding relationships between words and the order of tokens is crucial. This approach allows for simultaneous attention across all parts of a sequence, making it highly effective for language tasks.
- Vision Transformer (ViT): ViT’s use of patch embedding and modified positional encoding makes it effective for vision tasks. Images don’t follow a sequential pattern like text; instead, they require spatial recognition. By dividing an image into patches, ViT treats each patch as a token, allowing it to focus on spatial patterns across the whole image, which is more effective for tasks like classification or segmentation.
- Hybrid SSM-Transformer (Jamba): Jamba incorporates state space models (SSMs) to capture long-term temporal dependencies, which is valuable for tasks that require extensive context, such as summarizing long documents. SSMs provide recurrent properties to help the model retain information over long input sequences, making it more effective for processing large text spans without losing context.
- Convolutional Transformer (Hyena): Hyena replaces self-attention with convolutional layers to achieve linear complexity. Traditional self-attention scales quadratically with input size, making it costly for long-context tasks. By using convolutions, Hyena efficiently handles long sequences without high memory costs, making it ideal for audio or time-series processing.
- GLU-Based Vision Transformer (Activator): Activator’s use of Gated Linear Units (GLUs) allows the model to selectively control the information flow, reducing noise and computational costs. This is useful for vision tasks where focusing on key features without excessive computation is beneficial, such as in medical imaging, where the model can focus on important areas of an image.
Each model’s unique mathematical and algorithmic structure is optimized to handle specific data types and achieve computational efficiency. These targeted changes improve model performance for domain-specific tasks, justifying their unique names and specialized applications.
