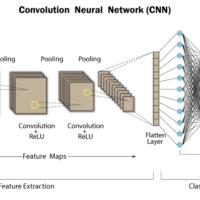
Can we make prediction without need of going through iteration ? yes with the Normal Equation _ Day 6
Understanding Linear Regression: The Normal Equation and Matrix Multiplications Explained Understanding Linear Regression: The Normal Equation and Matrix Multiplications Explained Linear regression is a fundamental concept in machine learning and statistics, used to predict a target variable based on one or more input features. While gradient descent is a popular method for finding the best-fitting line, the normal equation offers a direct, analytical approach that doesn’t require iterations. This blog post will walk you through the normal equation step-by-step, explaining why and how it works, and why using matrices simplifies the process. Table of Contents Introduction to Linear Regression Gradient...