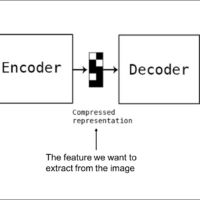
Activation function progress in deep learning, Relu, Elu, Selu, Geli , mish, etc – include table and graphs – day 24
Activation Function Formula Comparison Why (Problem and Solution) Mathematical Explanation and Proof Sigmoid σ(z) = 1 / (1 + e-z) – Non-zero-centered output – Saturates for large values, leading to vanishing gradients Problem: Vanishing gradients for large positive or negative inputs, slowing down learning in deep networks. Solution: ReLU was introduced to avoid the saturation issue by having a linear response for positive values. The gradient of the sigmoid function is σ'(z) = σ(z)(1 – σ(z)). As z moves far from zero (either positive or negative), σ(z) approaches 1 or 0, causing σ'(z) to approach 0, leading to very small...