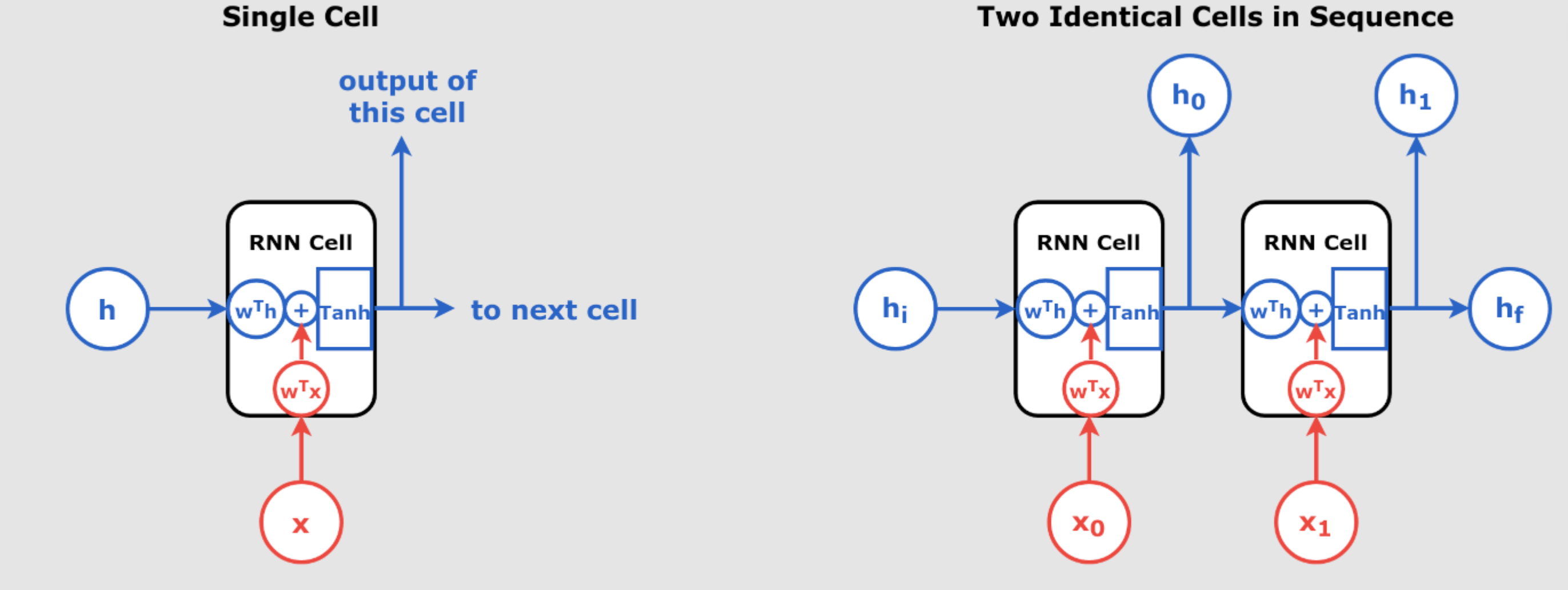
A Deep Dive into Recurrent Neural Networks, Layer Normalization, and LSTMs So far we have explained in pervious days articles a lot about RNN. We have explained, Recurrent Neural Networks (RNNs) are a cornerstone in handling sequential data, ranging from time series analysis to natural language processing. However, training RNNs comes with challenges, particularly when dealing with long sequences and issues like unstable gradients. This post will cover how Layer Normalization (LN) addresses these challenges and how Long Short-Term Memory (LSTM) networks provide a more robust solution to memory retention in sequence models. The Challenges of RNNs: Long Sequences and Unstable Gradients When training an RNN over long sequences, the network can experience the unstable gradient problem—where gradients either explode or vanish during backpropagation. This makes training unstable and inefficient. Additionally, RNNs may start to “forget” earlier inputs as they move forward through the sequence, leading to poor retention of important data points, a phenomenon referred to as the short-term memory problem. Addressing Unstable Gradients: Gradient Clipping: Limits the maximum value of gradients, ensuring they don’t grow excessively large. Smaller Learning Rates: Using a smaller learning rate helps prevent gradients from overshooting during updates. Activation Functions: Saturating activation functions like the hyperbolic tangent (tanh) help control gradients better than ReLU in RNNs. Layer Normalization: As we’ll explore further, layer normalization is particularly well-suited to address this issue in RNNs. Why Batch Normalization Doesn’t Work Well with RNNs As we have explain in our pervious articles , Batch Normalization (BN) is a technique designed to improve the training of deep neural networks by normalizing the inputs of each layer so that they have a mean of zero and a variance of one. This process addresses the issue of internal covariate shift, where the distribution of each layer’s inputs changes during training, potentially slowing down the training process. By stabilizing these input distributions, BN allows for higher learning rates and accelerates convergence. However, BN does not work as effectively in RNNs for several reasons: Temporal Dependence: In RNNs, hidden states evolve over time, making it difficult to normalize across mini-batches at each time step. Small Batches in Sequential Data: BN requires large batch sizes to compute meaningful statistics, which is often impractical for RNNs that operate on smaller batch sizes or variable-length sequences. Sequence Variation: Since BN operates across mini-batches, it struggles to accommodate variable sequence lengths common in sequential tasks like text processing. In contrast, Layer Normalization (LN) normalizes across features within each time step, allowing it to handle sequences efficiently. Layer Normalization: The Solution for RNNs Layer Normalization was introduced to solve some of the limitations of BN in RNNs. It operates by normalizing across the features within a layer, rather than across the mini-batch. This approach is particularly useful in RNNs because it: Layer Normalization (LN): Introduced by Ba et al., LN normalizes the inputs across the features within a single data sample rather than across the batch. This approach makes LN more suitable for RNNs, as it maintains the sequential dependencies and is effective even with small batch sizes.arXiv Assorted-Time Normalization (ATN): Proposed by Pospisil et al., ATN preserves information from multiple consecutive time steps and normalizes using them. This setup introduces longer time dependencies into the normalization process without adding new trainable parameters, enhancing the performance of RNNs on various tasks.arXiv Batch Layer Normalization (BLN): Ziaee and Çano introduced BLN as a combined version of batch and layer normalization. BLN adaptively weights mini-batch and feature normalization based on the inverse size of mini-batches, making it effective for both Convolutional and Recurrent Neural Networks.arXiv Code Example for Layer Normalization : class LNSimpleRNNCell(tf.keras.layers.Layer): def __init__(self, units, activation="tanh", **kwargs): super().__init__(**kwargs) self.state_size = units self.output_size = units self.simple_rnn_cell = tf.keras.layers.SimpleRNNCell(units, activation=None) self.layer_norm = tf.keras.layers.LayerNormalization() self.activation = tf.keras.activations.get(activation) def call(self, inputs, states): outputs, new_states = self.simple_rnn_cell(inputs, states) norm_outputs = self.activation(self.layer_norm(outputs)) return norm_outputs, [norm_outputs] How to Use It in a Model: custom_ln_model = tf.keras.Sequential([ tf.keras.layers.RNN(LNSimpleRNNCell(32), return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ]) Explanation: Initialization (__init__ method): units: Specifies the number of units in the RNN cell. activation: The activation function to apply after normalization. simple_rnn_cell: An instance of SimpleRNNCell without an activation function. layer_norm: An instance of LayerNormalization to normalize the outputs. activation: Retrieves the activation function specified (default is “tanh”). Forward Pass (call method): inputs: The input tensor at the current time step. states: The state tensor(s) from the previous time step. The simple_rnn_cell processes the inputs and previous states to produce outputs and new_states. outputs are then normalized using layer_norm. The specified activation function is applied to the normalized outputs. The method returns the activated, normalized outputs and the new state wrapped in a list. custom_ln_model in the code is a model integrates the custom LNSimpleRNNCell into a sequential model, followed by a dense layer with 14 units. Where Is Layer Normalization Applied? Inside the call method: norm_outputs = self.activation(self.layer_norm(outputs))<br><br> The outputs of the RNN cell (outputs) are normalized using self.layer_norm. After normalization, the activation function (e.g., tanh) is applied to the normalized outputs. Why Layer Normalization Works Well Here? Layer Normalization (LN) normalizes the inputs across features within a single data sample, maintaining sequential dependencies inherent in RNNs. Unlike Batch Normalization, which computes statistics across batches, LN is effective for small batch sizes and sequences of varying lengths. Layer Normalization vs. Batch Normalization: Layer Normalization (LN): Normalizes the inputs across the features within a single data sample. Particularly effective for RNNs as it maintains sequential dependencies and performs consistently regardless of batch size. Applied independently at each time step, making it suitable for sequence modeling tasks. Batch Normalization (BN): Normalizes the inputs across the batch dimension for each feature. Relies on batch statistics, which can be less effective for RNNs due to varying sequence lengths and dependencies. More suited for feedforward neural networks and convolutional networks. Lets Explain Deeper the Math Behind Layer Normalization vs Batch Normalization: Layer Normalization (LN) Normalization Scope: LN normalizes across all the features (dimensions) of a single sample (or layer). Key Idea: Treats the entire feature vector of a sample as a unit and calculates the mean and standard deviation for the features within that sample. Analogy: Think of LN as looking at a single row of data (sample) and balancing all its feature values. Example: For a batch of samples: [ [1, 2, 6], [4, 5, 8] ] LN computes the mean and standard deviation for each row independently: For Row 1: [1, 2, 6] → Mean = 3, Variance = 4.67 → Normalized: [-1.0, -0.5, 1.5]. For Row 2: [4, 5, 8] → Mean = 5.67, Variance = 2.89 → Normalized: [-1.0, -0.39, 1.39]. Batch Normalization (BN) Normalization Scope: BN normalizes each feature independently, but across all samples in a batch. Key Idea: Treats each feature (column) as a unit and calculates the mean and standard deviation across the batch. Analogy: Think of BN as balancing each column of data (feature) across multiple rows (samples). Example: For the same batch of samples: [ [1, 2, 6], [4, 5, 8] ] BN computes the mean and standard deviation for each column: Column 1: [1, 4] → Mean = 2.5, Variance = 2.25 → Normalized: [-1.0, 1.0]. Column 2: [2, 5] → Mean = 3.5, Variance = 2.25 → Normalized: [-1.0, 1.0]. Column 3: [6, 8] → Mean = 7, Variance = 1 → Normalized: [-1.0, 1.0]. Comparison Summary: AspectLayer Normalization (LN)Batch Normalization (BN)ScopeNormalizes across features of a single sample.Normalizes across samples for each feature.Dependence on BatchIndependent of batch size.Dependent on batch size.Best ForSequential models (RNNs, Transformers).Feedforward/CNN models.Key OperationConsiders a row (entire layer or sample).Considers a column (feature across batch). Visualization (Simplified Concept): Layer Normalization (LN): Balances each row independently: Row 1: [1, 2, 6] → Normalize → [-1.0, -0.5, 1.5] Row 2: [4, 5, 8] → Normalize → [-1.0, -0.39, 1.39] Batch Normalization (BN): Balances each column independently: Feature 1: [1, 4] → Normalize → [-1.0, 1.0] Feature 2: [2, 5] → Normalize → [-1.0, 1.0] Feature 3: [6, 8] → Normalize → [-1.0, 1.0] As you can see in the provided example, LN works on the entire feature vector (row) within a sample. BN does not operate row by row. Instead, it normalizes each feature (column) across the batch. All in all, LN is great for sequential models (like RNNs), while BN is typically better for convolutional or dense architectures. Final Key Note to understand RNN better and why LN is better for RNN: RNNs are fundamentally affected by rows rather than columns, and that is why Layer Normalization (LN), which normalizes rows, is better suited for RNNs than Batch Normalization (BN), which normalizes columns: RNNs process data sequentially, focusing on one time step at a time, where each time step corresponds to a single row of features. This fundamental row-wise operation makes Layer Normalization (LN) more compatible with RNNs than Batch Normalization (BN). Here’s why: 1. RNNs Process Rows, Not Columns At each time step, the RNN processes one row of features representing the input at that moment. The RNN computes the hidden state for that time step using the current row and the hidden state from the previous time step. This means that each row is treated as a distinct unit, and its features directly influence the hidden state. Consequently, ensuring that the features within each row are well-normalized is critical for stable and effective training. 2. LN Normalizes Rows Layer Normalization (LN) operates at the row level: It computes the mean and variance across the features (columns) within a single row. The normalization ensures that the input features at each time step are centered and scaled consistently. This aligns perfectly with RNNs because: Each row (time step) is processed independently. LN ensures that the features of the current row do not depend on other rows, maintaining consistency. 3. BN Normalizes Columns Batch Normalization (BN) operates at the column level: It computes the mean and variance of each feature (column) across all rows in the batch. This batch-wide dependency introduces two key issues for RNNs: Temporal Instability: The batch statistics can change significantly between time steps, disrupting the temporal dependencies that RNNs rely on. Dependency on Batch Size: RNNs often work with small batch sizes (or even single samples) due to memory constraints, making BN’s batch-wide statistics unreliable or inconsistent. 4. Temporal Dependencies in RNNs RNNs rely heavily on the stability of inputs across time steps to learn meaningful sequential patterns. LN ensures stable normalization for each time step because it normalizes independently for each row. BN, by contrast, introduces variability due to its reliance on batch-wide statistics, which may differ from one time step to another. So I hope you could understand deeply why LN is better for RNN. We have fully explained that RNNs process data row by row (time step by time step), making them fundamentally affected by rows rather than columns. LN’s row-based normalization aligns naturally with this structure, ensuring consistency and stability across time steps. In contrast, BN’s column-based normalization disrupts this temporal consistency, making LN the better choice for RNNs. The Short-Term Memory Problem and LSTMs Even with Layer Normalization (LN), standard RNNs often fail to retain important information over long sequences, which brings us to Long Short-Term Memory (LSTM) networks. LSTMs are specifically designed to address the short-term memory problem by maintaining two key states: Short-Term State (hₜ): Captures the most recent information at the current time step. Long-Term State (cₜ): Stores information over longer sequences, allowing the network to retain useful context for more extended periods. Let’s simplify the explanation! LSTMs are like improved versions of RNNs. Both process data one row at a time, but LSTMs add a “memory system” that helps them remember important information from earlier rows while deciding what to forget or update at each step. RNNs: Row-by-Row Basics RNNs handle sequential data (like sentences or time series) one row (or time step) at a time. At each time step: RNNs take the current row (e.g., words in a sentence or data at a time step). Combine it with what they remembered from the previous row (the “hidden state”). Use this to calculate a new hidden state for the current row. Problem: RNNs can’t decide what to forget or remember, and over long sequences, they often forget earlier rows (this is called the vanishing gradient problem). LSTMs Improve RNNs LSTMs work like RNNs but add extra features to fix these problems: Memory Cell (A Notebook): Think of this as a notebook that keeps track of important information across rows (time steps). Gates (Decision Makers): LSTMs use gates to decide: What to forget from the memory. What new information to add to the memory. What to output for the current row. These gates let LSTMs dynamically adjust how they process each row based on the current input and past information. How LSTMs Process Rows (Step-by-Step) At each row t t: Forget Gate: Looks at the current row (xt xt) and the hidden state from the previous row ( ht−1 ht−1). Decides how much of the previous memory to forget. Input Gate: Decides what new information from the current row (xt xt) to add to the memory. Update Memory: Combines the forgotten information with the new information to update the memory. Output Gate: Decides what part of the updated memory to output as the hidden state for this row (ht ht). Why LSTMs Are Related to Row-by-Row Processing LSTMs, like RNNs, process one row at a time. The difference is: RNNs just pass information forward without control, often losing important details. LSTMs use the memory cell and gates to control the flow of information row by row. Example to Clarify Imagine you’re reading a story: RNNs: You read each line, but you don’t take notes. By the time you get to the last line, you forget what happened earlier. LSTMs: You read each line and take notes (memory cell). You decide: What parts of the story to forget (e.g., unimportant details). What new information to write down. What to focus on for the next part of the story. Key Takeaway LSTMs are built on the row-by-row structure of RNNs but add a memory system and decision-making gates. This allows them to remember important information over long sequences and avoid forgetting or losing details like RNNs often do. LSTM Structure: LSTMs introduce three gates—forget, input, and output—that control the flow of information, deciding which information to retain, which to discard, and what to output at each step. LSTM Code Example: model = tf.keras.Sequential([ tf.keras.layers.LSTM(32, return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ]) LSTMs use these gates to manage memory and retain long-term dependencies in the data, solving one of the most critical challenges in sequence modeling. How Layer Normalization and LSTMs Improve RNNs By combining Layer Normalization and LSTMs, we can build models that effectively handle long sequences and mitigate unstable gradients: Layer Normalization: Stabilizes the training process and ensures smooth gradient flow, preventing exploding or vanishing gradients. LSTMs: Allow the network to maintain long-term memory, enabling it to better understand long-range dependencies in the sequence data. Both techniques work in harmony to tackle the primary weaknesses of traditional RNNs, making them essential tools for anyone working with sequential data like time series, language models, or any application requiring memory retention over time. Detailed Comparison Table AspectLayer Normalization (LN)Long Short-Term Memory (LSTM)PurposeNormalizes across features (columns) within each row (time step) to stabilize training by controlling feature-level variability.Introduces memory cells and gates to retain, forget, or update information dynamically over long sequences.Row-by-Row MechanismOperates on a per-row basis, normalizing all features in a single time step independently of other rows.Processes each row sequentially in time order, relying on memory cells to manage temporal dependencies across time steps.Handling Long SequencesStabilizes input features for each time step but does not inherently solve the issue of retaining information across long sequences.Designed specifically to handle long-term dependencies by mitigating vanishing gradient problems with memory cells and gated updates.Gating MechanismsDoes not include gates; solely focuses on normalizing the input features within each row.Includes three gates: Forget Gate (removes irrelevant past information), Input Gate (adds new relevant information), and Output Gate (determines the output for the current time step).Dependency on Batch SizeCompletely independent of batch size, making it robust for small or variable-sized batches and single-sample cases.Processes…
UNLOCKING RNN, Layer Normalization, and LSTMs – Mastering the Depth of RNNs in Deep Learning – Part 8 of RNN Series by INGOAMPT – Day 62