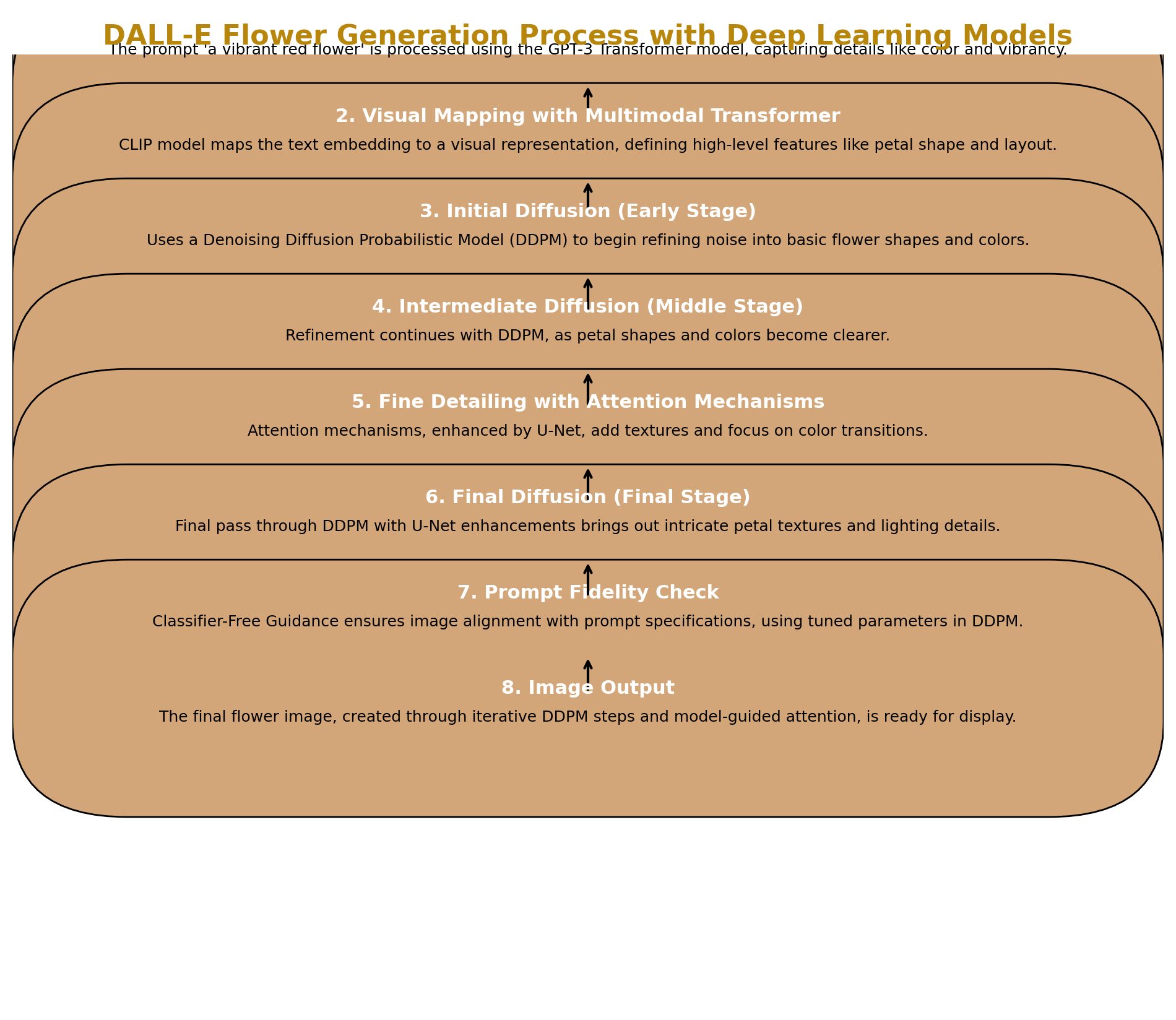
Understanding DALL-E 3: Advanced Text-to-Image Generation Understanding DALL-E 3: Advanced Text-to-Image Generation DALL-E, developed by OpenAI, is a groundbreaking model that translates text prompts into detailed images using a sophisticated, layered architecture. The latest version, DALL-E 3, introduces enhanced capabilities, such as improved image fidelity, prompt-specific adjustments, and a system to identify AI-generated images. This article explores DALL-E’s architecture and workflow, providing updated information to simplify the technical aspects. 1. Core Components of DALL-E DALL-E integrates multiple components to process text and generate images. Each part has a unique role, as shown in Table 1. Component Purpose Description Transformer Text Understanding Converts the text prompt into a numerical embedding, capturing the meaning and context. Multimodal Transformer Mapping Text to Image Transforms the text embedding into a visual representation, guiding the image’s layout and high-level features. Diffusion Model Image Generation Uses iterative denoising to convert random noise into an image that aligns with the prompt’s visual features. Attention Mechanisms Focus on Image Details Enhances fine details like textures, edges, and lighting by focusing on specific image areas during generation. Classifier-Free Guidance Prompt Fidelity Ensures adherence to the prompt by adjusting the influence of text conditions on the generated image. Recent Enhancements: DALL-E 3 features improved alignment between text and visual representations, enabling more accurate and intricate image generation. It can now handle complex details such as hands, faces, and embedded text in images, providing users with sharper, more lifelike results. 2. Step-by-Step Workflow of DALL-E DALL-E’s workflow translates a text prompt into an image through multiple stages: Interpreting the Prompt with Transformers: The text prompt is embedded using transformers, capturing context and meaning as a base for the image. Mapping Text to Visual Space: The embedding maps to visual space, defining high-level features. Image Generation through Diffusion: Iterative denoising brings the image closer to the prompt. Enhancing Detail with Attention Mechanisms: Focuses on textures and spatial details for enhanced realism. Ensuring Prompt Fidelity with Classifier-Free Guidance: Balances prompt influence for alignment with user descriptions. 3. Denoising Stages: A Visual Breakdown Denoising is central to DALL-E’s generation process, evolving from random noise into a coherent image: Early Stage: Shapes and colors emerge. Middle Stage: Structure becomes visible. Final Stage: Lighting, texture, and intricate edges finalize the image. 4. Recent Enhancements: Efficiency, Control, and Fidelity Recent updates have introduced several advancements that increase DALL-E’s…
How Dalle Image Generator works ? – Day 77