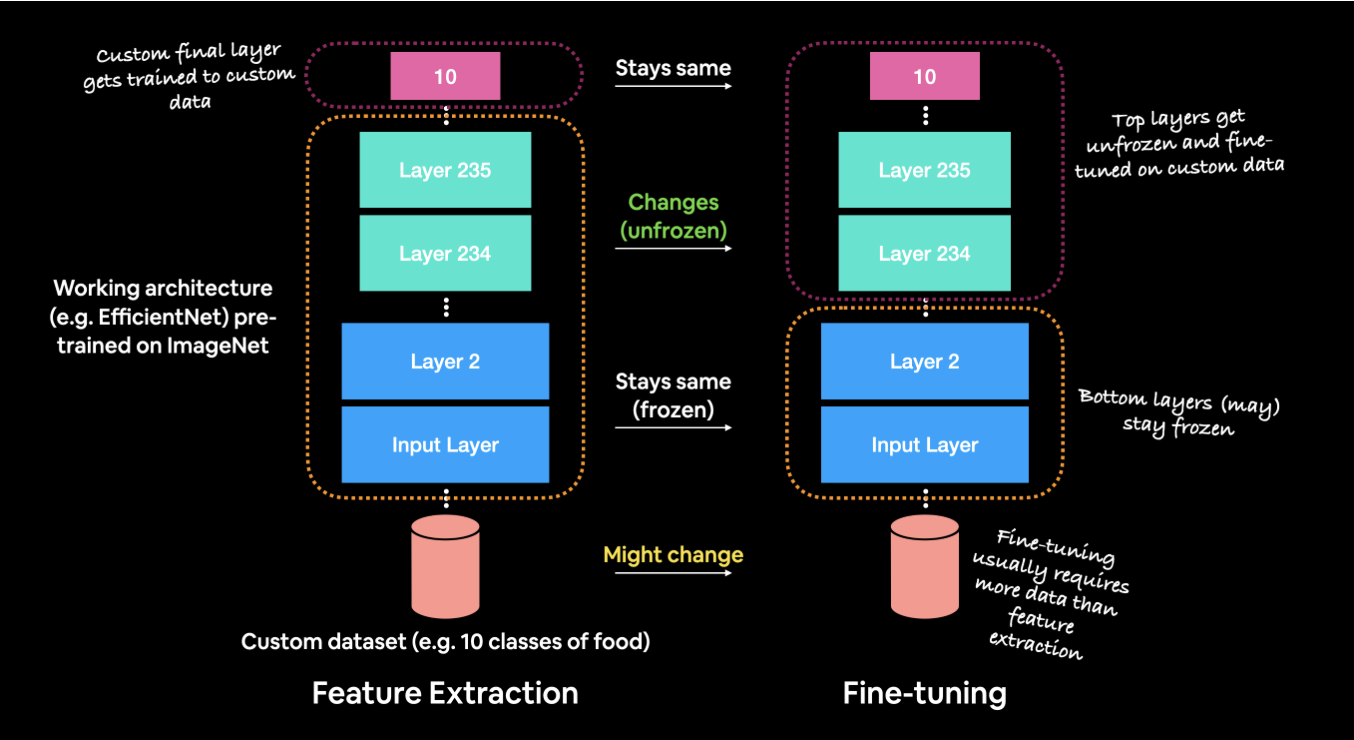
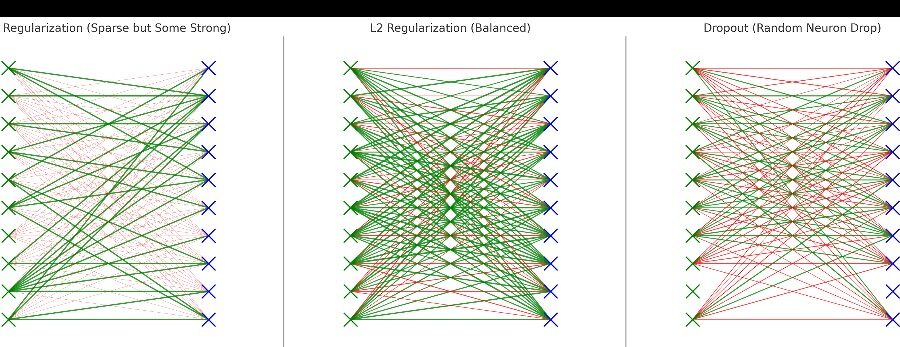
Understanding Fine-Tuning in Deep Learning Understanding Fine-Tuning in Deep Learning: A Comprehensive Overview Fine-tuning in deep learning has become a powerful technique, allowing developers to adapt pre-trained models to specific tasks without training from scratch. This approach is especially valuable in areas like natural language processing, computer vision, and voice cloning. In this article, we’ll explore what fine-tuning is, why it’s used, how it works from mathematical and neural perspectives, and provide a practical implementation as well. What is Fine-Tuning in Deep Learning? Fine-tuning is the process of taking a pre-trained model (a model trained on a large, general dataset) and adapting it to a specific, smaller dataset. This allows the model to retain its general knowledge and refine it to fit a new, task-specific context. For example, a voice synthesis model can be fine-tuned to replicate a specific person’s voice. Why Fine-Tuning? Fine-tuning is beneficial for several reasons: Benefit Description Efficiency Saves time and computational power by leveraging pre-trained models. Knowledge Transfer Retains general patterns learned from large datasets and applies them to a new context. Transfer Learning Uses insights from one task (e.g., general speech synthesis) to perform related tasks (e.g., mimicking a new voice). How Does Fine-Tuning Work? The fine-tuning process can be broken down into several steps: 1. Selecting a Pre-Trained Model Choose a model pre-trained on a large, general dataset relevant to the target domain. Examples include Tacotron 2 or WaveGlow for speech synthesis tasks. 2. Modify the Model Architecture Adjust the final layers to fit the new task. For instance, add a new layer to adapt a general model to a specific speaker in voice cloning. 3. Freeze Layers Freezing lower layers prevents overwriting general features. This keeps early layers that capture basic features (like phonemes) intact, focusing fine-tuning on task-specific features. 4. Training on Task-Specific Data Only a portion of the model’s layers are trainable, which means the model only learns new patterns relevant to the new dataset, preserving pre-trained knowledge. 5. Evaluation and Optimization After training, evaluate the model’s performance and adjust hyperparameters as needed. Benefits and Challenges of Fine-Tuning Benefits Benefit Explanation Efficient Training Faster and less resource-intensive than training from scratch. Specialization Can adapt a general-purpose model to perform highly specialized tasks. Robustness Combines the pre-trained model’s generalization with task-specific learning for better performance. Challenges Challenge Explanation Data Scarcity Limited data in certain domains can make fine-tuning difficult. Overfitting Risk of overfitting to a small, specific dataset. Quality Retention Fine-tuning must ensure that the model’s general capabilities are not degraded in the process. Mathematical Foundations of Fine-Tuning: Why It Works Fine-tuning is effective due to mathematical principles around parameter optimization and regularization. Below are key mathematical concepts that underpin why fine-tuning works: 1. Parameter Space and Loss Function Fine-tuning works by optimizing a loss function that measures the difference between the model’s predictions and the target outputs. The parameters in a pre-trained model are already close to a minimum for the general task (e.g., speech synthesis), making fine-tuning computationally efficient. Objective in Fine-Tuning: where . This formula shows that fine-tuning involves adjusting (the changes to the original pre-trained parameters) to minimize the task-specific loss . 2. Optimization Landscape In deep learning, training from scratch requires navigating a large optimization landscape to find an optimal minimum. Fine-tuning, however, begins with parameters already near a good local minimum because they were optimized for a similar task, such as general speech synthesis. Training Approach Optimization Requirement From Scratch Find an optimal point in a large parameter space. Fine-Tuning Start near a minimum and make small adjustments for the new task. 3. Regularization through Constrained Optimization Fine-tuning can be viewed as a form of regularization that constrains the model from deviating too far from the pre-trained parameters. Mathematically, this is often achieved by adding a regularization term to the loss function: This regularization ensures that fine-tuning doesn’t drastically alter the model, which helps prevent overfitting to the smaller task-specific dataset. 4. Transfer Learning Theory and Generalization Fine-tuning is effective because it leverages transfer learning principles. The pre-trained model contains useful features learned from a large, diverse dataset. By adjusting the higher layers during fine-tuning, these generalized features are adapted to a new, more specific task without needing to retrain the entire network. Transfer Learning Assumption: If the source and target tasks share underlying structures, then: — Neural Network Perspective on Fine-Tuning From a neural network perspective, fine-tuning works due to the hierarchical feature structure within the layers: 1. Feature Hierarchies Lower layers capture general features, like edges in images or phonemes in speech, which are transferable across tasks. These are often “frozen” during fine-tuning to retain their general knowledge. Higher layers are “trainable” during fine-tuning to adapt to the target task. 2. Representational Knowledge Transfer The pre-trained model contains rich representations from its initial training, which can be adapted to the specific characteristics of the new task. Fine-tuning then modifies only the necessary parameters, allowing the model to specialize in the target task without sacrificing the general knowledge it has acquired. 3. Fine-Tuning in Transformers In Transformers, fine-tuning involves adjusting the self-attention layers to focus on task-specific relationships and adding task-specific heads, like classification heads for sentiment analysis. Fine-Tuning a Voice Cloning Model Using PyTorch Fine-Tuning a Voice Cloning Model Using PyTorch: Step-by-Step Guide Overview of Voice Cloning and Required Data Voice cloning involves generating synthetic speech that mimics the characteristics of a target speaker’s voice. For this, you need: Audio recordings of the target speaker: The data should cover a wide range of sounds and tones, ideally with high audio quality. Transcriptions: Accurate transcriptions are essential to match the spoken content with the audio for model training. Data Sources for Voice Cloning There are several ways to source data for voice cloning: Public Datasets: Datasets like LibriSpeech and VCTK provide extensive recordings of various speakers. Custom Data Collection: If the target speaker is someone specific, such as a client or public figure, you may need to collect custom recordings in a quiet environment with high-quality recording devices. Purpose of Data: The data provides the model with examples of how the target speaker pronounces words, uses tone, and varies pitch. This information is crucial for the model to understand and replicate the…
Fine-Tuning in Deep Learning with a practical example – day 6