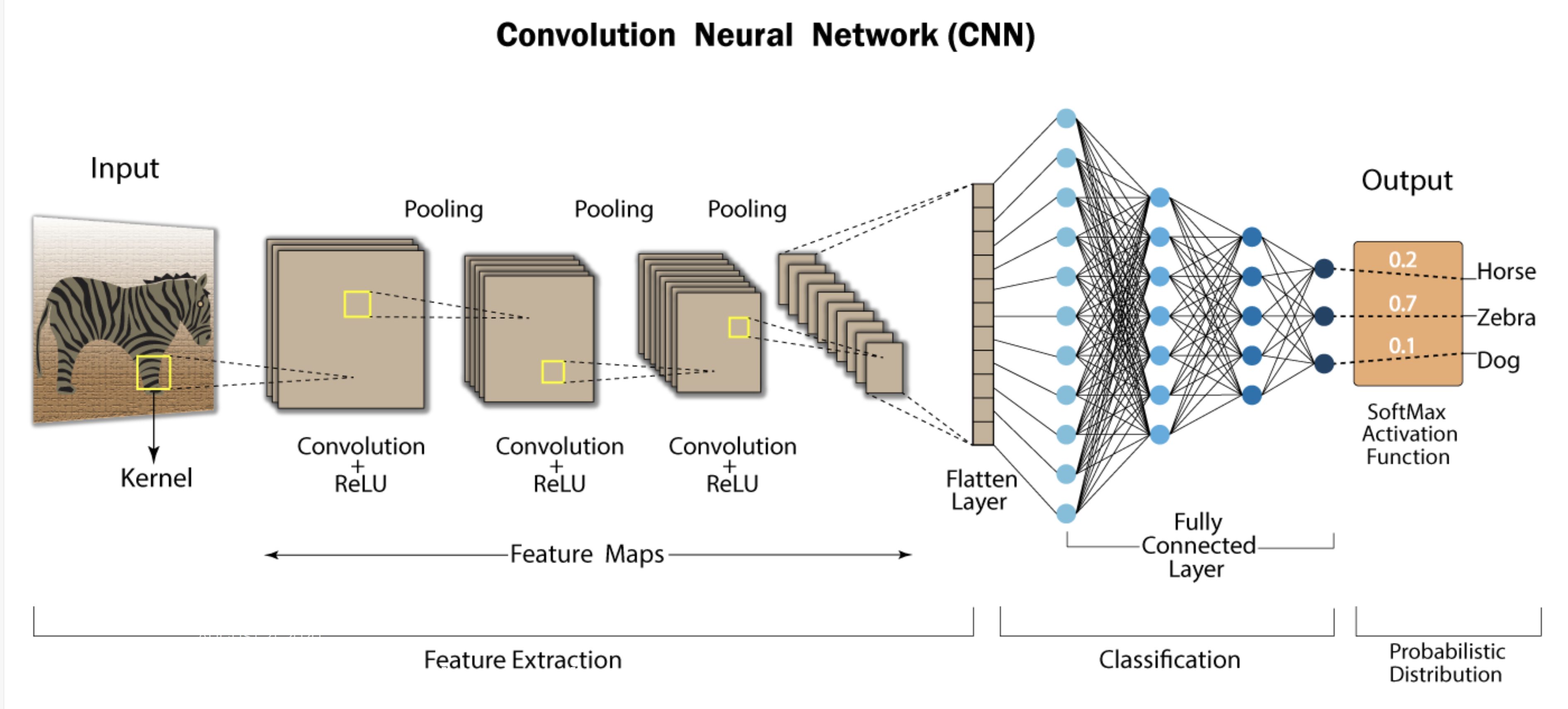
Understanding Convolutional Neural Networks (CNNs): A Step-by-Step Breakdown Convolutional Neural Networks (CNNs) are widely used in deep learning due to their ability to efficiently process image data. They perform complex operations on input images, enabling tasks like image classification, object detection, and segmentation. This step-by-step guide explains each stage of a CNN’s process, along with an example to clarify the concepts. 1. Input Image Representation The first step is providing an image to the network as input. Typically, the image is represented as a 3D matrix where the dimensions are: Height: Number of pixels vertically. Width: Number of pixels horizontally. Channels: Number of color channels (e.g., RGB for color images). Example: A 32×32 RGB image is represented with the shape: (32, 32, 3) 2. Convolutional Layer The Convolutional Layer applies filters to the image. Filters are small matrices that slide over the image, performing element-wise multiplication followed by summation. This produces feature maps. Each filter detects specific features like edges or textures. The network learns these filters during training. Mathematical Operation: 3. Activation Function (ReLU) After the convolutional layer, an Activation Function is applied. The most common activation function is ReLU (Rectified Linear Unit), which is mathematically expressed as: ReLU zeroes out all negative values and retains only positive values, introducing non-linearity into the network. 4. Pooling Layer (Downsampling) The Pooling Layer reduces the spatial dimensions of the feature maps. This helps reduce the computational complexity of the model and prevents overfitting. The most common pooling operation is Max Pooling. 5. Flattening Layer Before passing data to the fully connected layers, the 2D feature maps are flattened into a 1D vector. 6. Fully Connected Layer The Fully Connected Layer connects every input neuron to every output neuron, using learned features from earlier layers to make predictions. 7. Output Layer The final layer in the CNN produces probabilities using a Softmax Activation Function. 8. Backpropagation and Optimization During training, the model uses Backpropagation to calculate the error and update weights. This process ensures the model improves over time by reducing the loss function. Optimization algorithms: SGD (Stochastic Gradient Descent) or Adam Step-by-Step Summary of CNN Operations StepOperationOutput1. Input LayerReceives an image of size (32, 32, 3).(32, 32, 3)2. Convolutional LayerApplies filters to detect features like edges.(30, 30, 32) (after applying a 3×3 filter)3. Activation (ReLU)Applies ReLU to introduce non-linearity.(30, 30, 32) (negative values set to 0)4. Pooling LayerMax pooling reduces the feature map size.(15, 15, 32)5. Flattening LayerFlattens the 2D feature map into a 1D vector.(7200)6. Fully Connected LayerConnects all features to output neurons.(128)7. Output LayerSoftmax outputs probabilities for each class.[0.9, 0.1] (e.g., 90% cat, 10% dog)8. BackpropagationUpdates weights to minimize error.Weights updated across layers Key Note This breakdown explains how CNNs process images step-by-step, from input to classification. Each layer plays a specific role in extracting features, learning complex patterns, and improving through backpropagation. CNNs are widely used because of their ability to automatically learn important features and apply them efficiently. Below once more time we explain this steps with the image we have shared for better understanding of what we explained so far. source : https://developersbreach.com/convolution-neural-network-deep-learning/ Step-by-Step Comparison of CNN Operations and Image (Image on Top of Our Article) In the image on top of our article, we can visualize the entire flow of a typical CNN architecture, which aligns well with the step-by-step table we previously discussed. Here’s how the steps from the table compare to the components shown in the image: StepOperation (Table)Corresponding Component (Image)1. Input LayerReceives the image as input, such as a RGB image.The Input section in the image, showing the zebra image as input.2. Convolutional LayerApplies filters (kernels) to detect features like edges.The first Convolution + ReLU section in the image, where filters are applied to the input image.3. Activation (ReLU)Applies ReLU to introduce non-linearity and eliminate negative values.Part of the Convolution + ReLU layers, shown after the convolution step in the image.4. Pooling LayerApplies max pooling to downsample the feature maps and reduce the size of the data.The Pooling layers in the image, reducing the size of the feature maps.5. Flattening LayerFlattens the 2D feature maps into a 1D vector to prepare for the fully connected layer.The Flatten Layer in the image, located between feature extraction and classification.6. Fully Connected LayerCombines all the features and connects them to the output neurons, learning complex representations.The Fully Connected Layer in the image, where the flattened feature maps are used for classification.7. Output LayerUses the Softmax function to convert logits to probabilities for classification.The Softmax Activation Function and the Output Layer in the image, showing final class probabilities (e.g., 0.7 for zebra).8. BackpropagationUpdates the weights based on the loss function during training.Not explicitly shown in the image, but occurs during training after generating output. Detailed Comparison: Image Breakdown and Table Alignment Let’s compare the steps more thoroughly: Input Layer: The zebra serves as the input in the image, which corresponds to the first step in the table. Here, the image is processed with dimensions like . Convolutional + ReLU Layers: The convolution layers in the image apply filters to detect simple features like edges. These layers are clearly labeled Convolution + ReLU, aligning with the convolution and activation steps in the table. Pooling Layers: The pooling layers in the image are responsible for downsampling the feature maps. This is a critical step in reducing the spatial dimensions, matching the pooling step in the table. Flatten Layer: The feature maps are flattened into a 1D vector, as shown in the image. This step prepares the data for classification in the fully connected layers. Fully Connected Layer: In the image, the fully connected layer learns from the extracted features and combines them for final decision-making. This corresponds to the step in the table where the network connects all features to the output neurons. Output Layer: The softmax activation function produces probabilistic outputs (e.g., zebra = 0.7). This matches the table’s output layer step, where softmax is applied to determine the class probabilities. Backpropagation: Although not shown in the image, backpropagation occurs after the output is generated, updating the network’s weights based on the error. This step is essential during training and is listed in the table as well. Now Is Time for Code Part Practice of the CNN which we explained the theory so far CNN in PyTorch Example The following example demonstrates a fully functional implementation of ResNet-18, a type of Convolutional Neural Network (CNN), in PyTorch. This model is used to classify images from the CIFAR-10 dataset into 10 categories. The code includes all necessary steps, such as data loading, model definition, training, and evaluation: import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms # Step 1: Define the Basic Block (Residual Block) used in ResNet # Residual blocks allow gradients to flow directly through skip connections, reducing the vanishing gradient problem. class BasicBlock(nn.Module): expansion = 1 def __init__(self, in_channels, out_channels, stride=1): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(out_channels) self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channels) self.shortcut = nn.Sequential() if stride != 1 or in_channels != out_channels: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(out_channels) ) def forward(self, x): out = torch.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) out += self.shortcut(x) # Skip connection out = torch.relu(out) return out # Step 2: Define the ResNet model # The ResNet architecture stacks multiple residual blocks for deep feature extraction. class ResNet(nn.Module): def __init__(self, block, num_blocks, num_classes=10): super(ResNet, self).__init__() self.in_channels = 64 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(64) self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) self.linear = nn.Linear(512 * block.expansion, num_classes) def _make_layer(self, block, out_channels, num_blocks, stride): strides = [stride] + [1] * (num_blocks – 1) layers = [] for stride in strides: layers.append(block(self.in_channels, out_channels, stride)) self.in_channels = out_channels * block.expansion return nn.Sequential(*layers) def forward(self, x): out = torch.relu(self.bn1(self.conv1(x))) out = self.layer1(out) out =…
CNN – Convolutional Neural Networks explained by INGOAMPT – DAY 53