Deep Learning Models integration for iOS Apps – briefly explained – Day 52
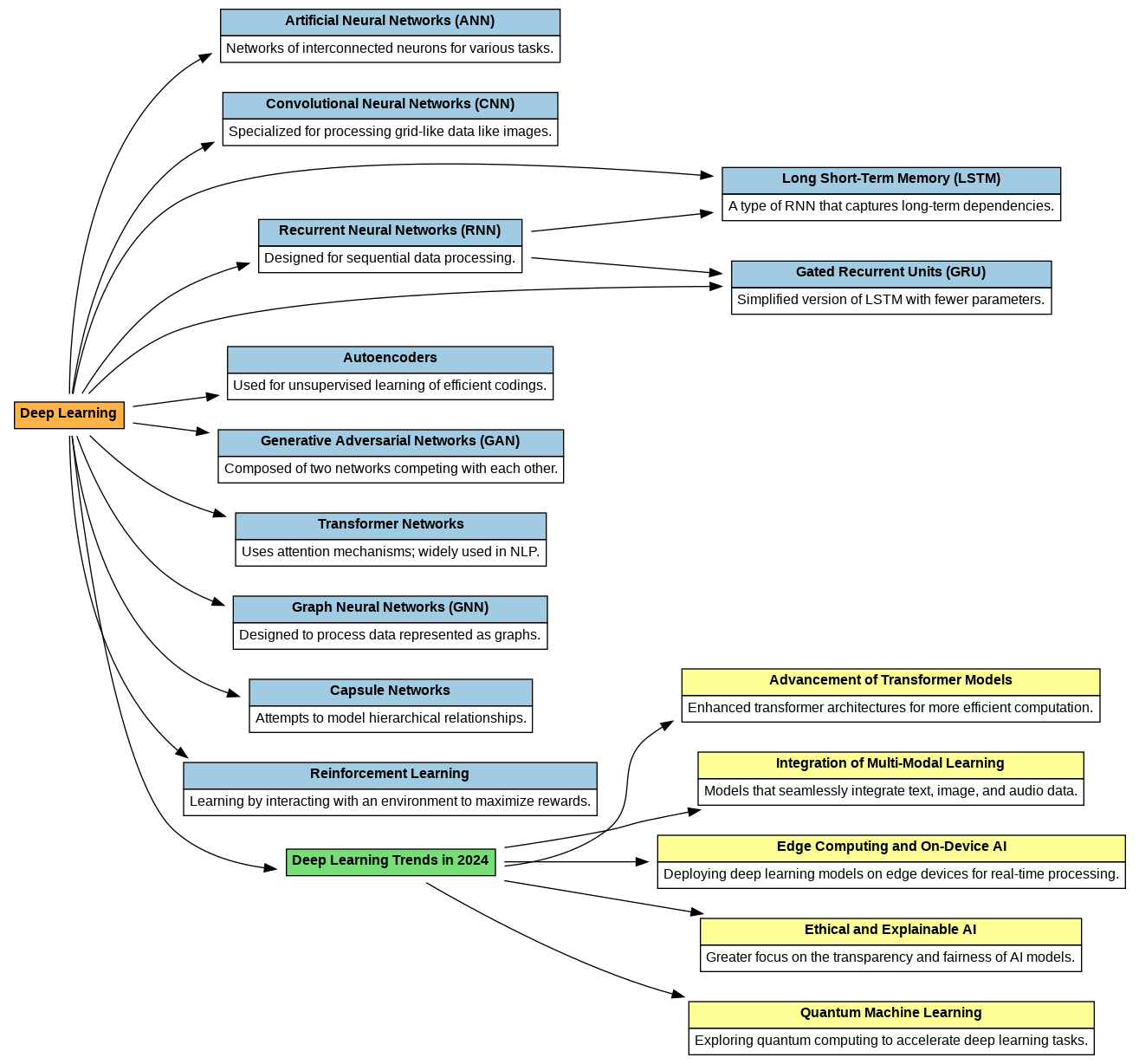
Key Deep Learning Models for iOS Apps Natural Language Processing (NLP) Models NLP models enable apps to understand and generate human-like text, supporting features like chatbots, sentiment analysis, and real-time translation. Top NLP Models for iOS: • Transformers (e.g., GPT, BERT, T5): Powerful for text generation, summarization, and answering queries. • Llama: A lightweight, open-source alternative to GPT, ideal for mobile apps due to its resource efficiency. Example Use Cases: • Building chatbots with real-time conversational capabilities. • Developing sentiment analysis tools for analyzing customer feedback. • Designing language translation apps for global users. Integration Tools: • Hugging Face: Access...