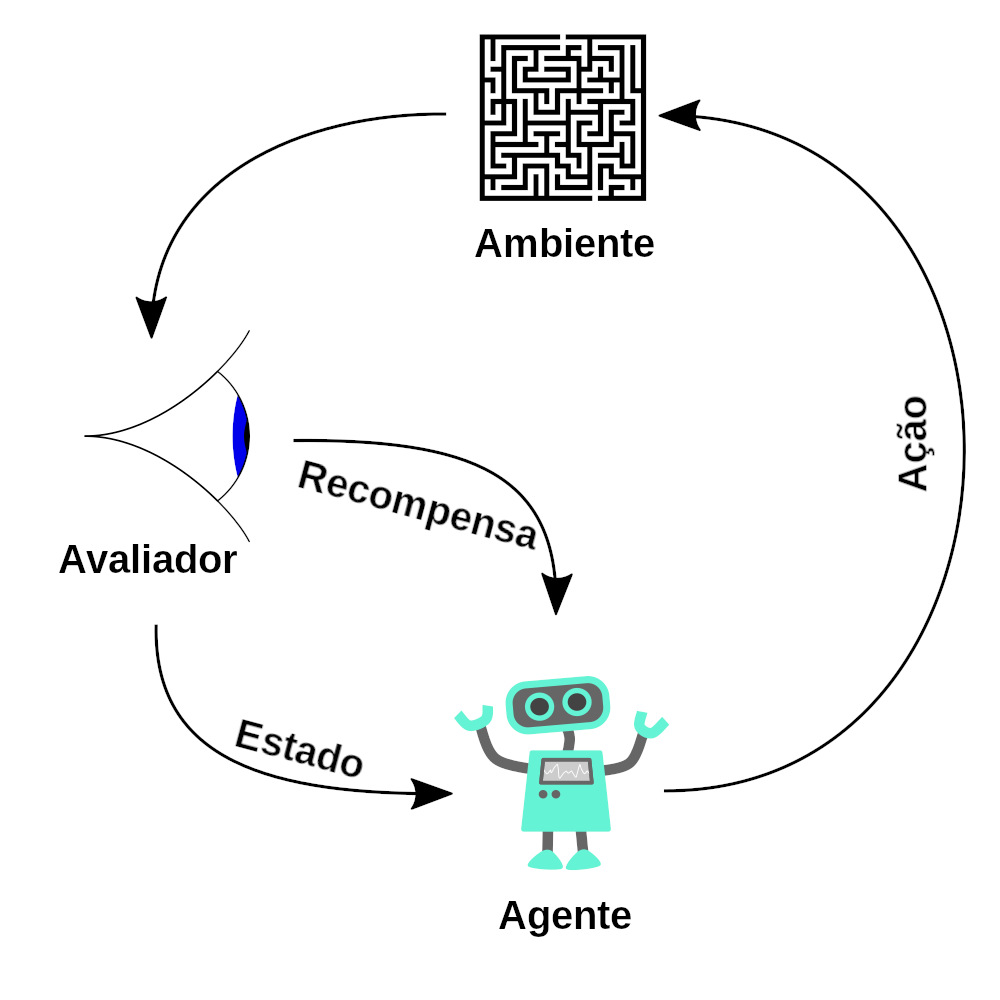
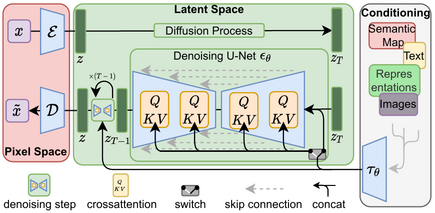
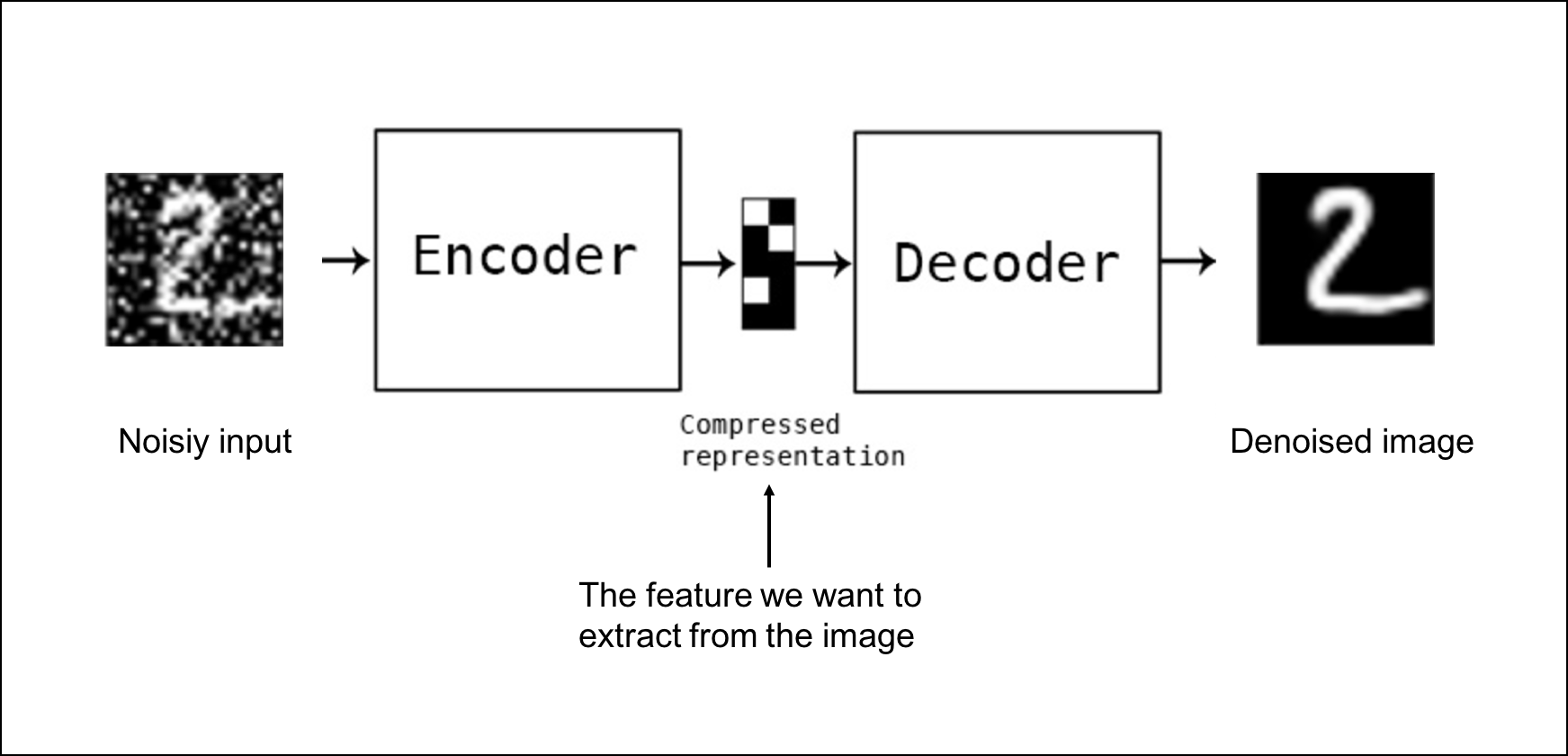
Lets go through Paper of DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning – Day 80
Lets First Go Through its official paper of : DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning What Is DeepSeek-R1? DeepSeek-R1 is a new method for training large language models (LLMs) so they can solvetough reasoning problems (like math and coding challenges) more reliably. It starts with a base model(“DeepSeek-V3”) and then applies Reinforcement Learning (RL) in a way thatmakes the model teach itself to reason step by step, without relying on a huge amount of labeled examples. In simpler terms: They take an existing language model. They let it practice solving problems on its own, rewarding it when...