CNN – Convolutional Neural Networks explained by INGOAMPT – DAY 53
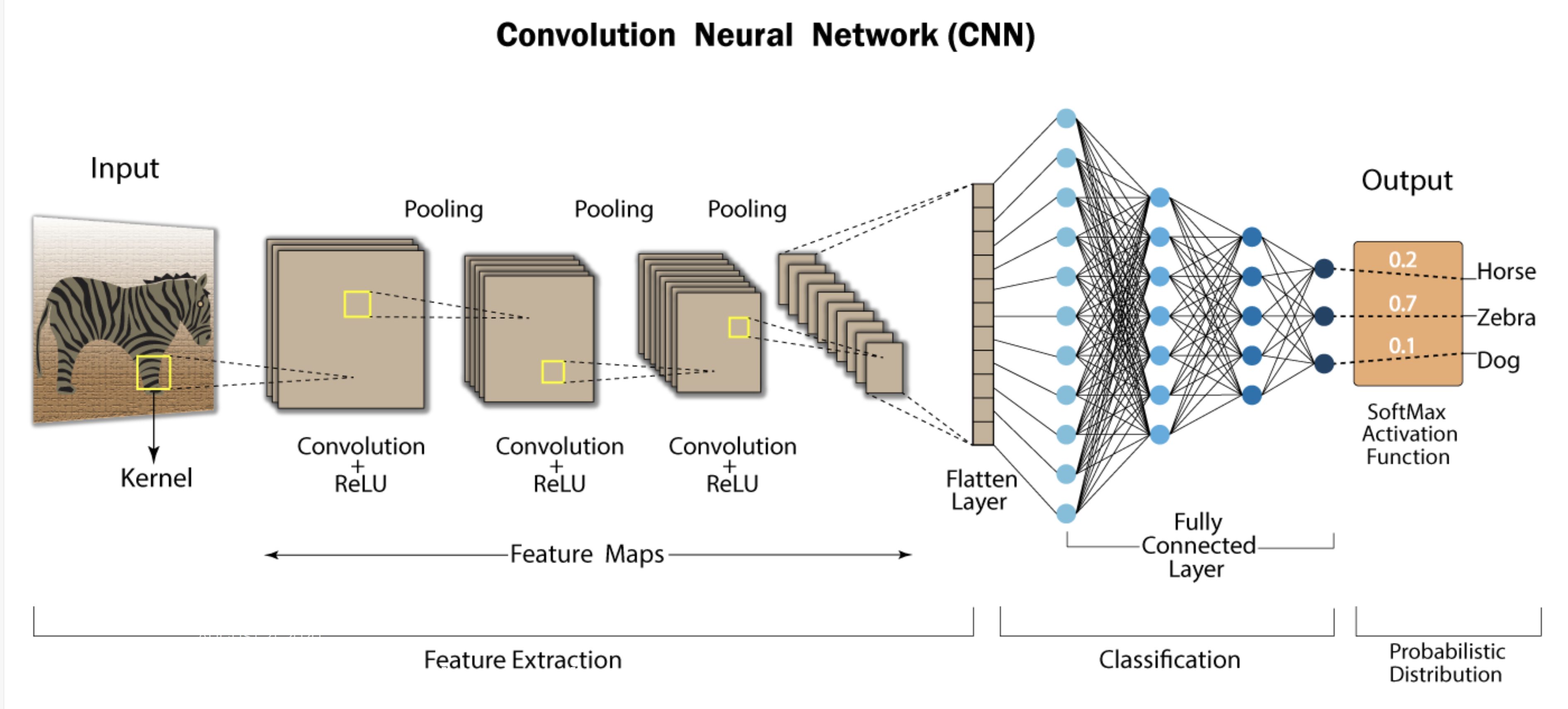
Understanding Convolutional Neural Networks (CNNs): A Step-by-Step Breakdown Convolutional Neural Networks (CNNs) are widely used in deep learning due to their ability to efficiently process image data. They perform complex operations on input images, enabling tasks like image classification, object detection, and segmentation. This step-by-step guide explains each stage of a CNN’s process, along with an example to clarify the concepts. 1. Input Image Representation The first step is providing an image to the network as input. Typically, the image is represented as a 3D matrix where the dimensions are: Example: A 32×32 RGB image is represented with the shape:...