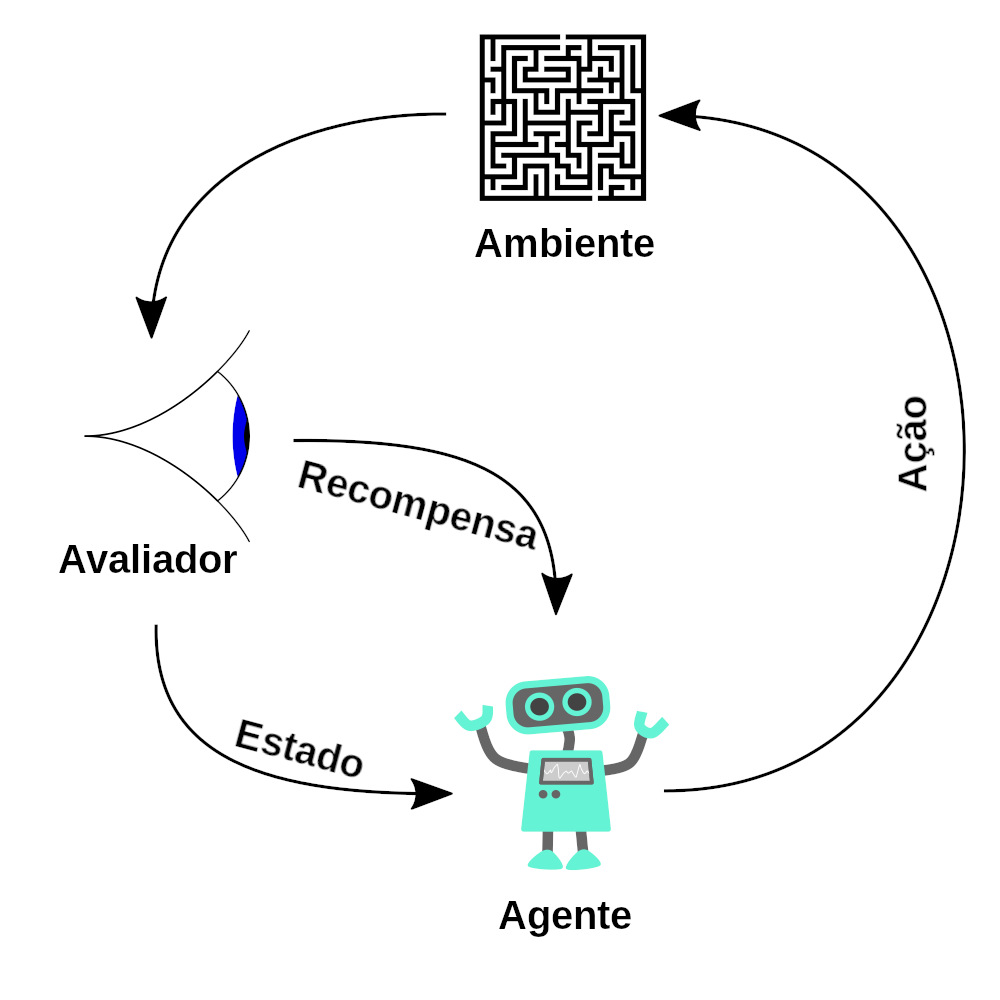
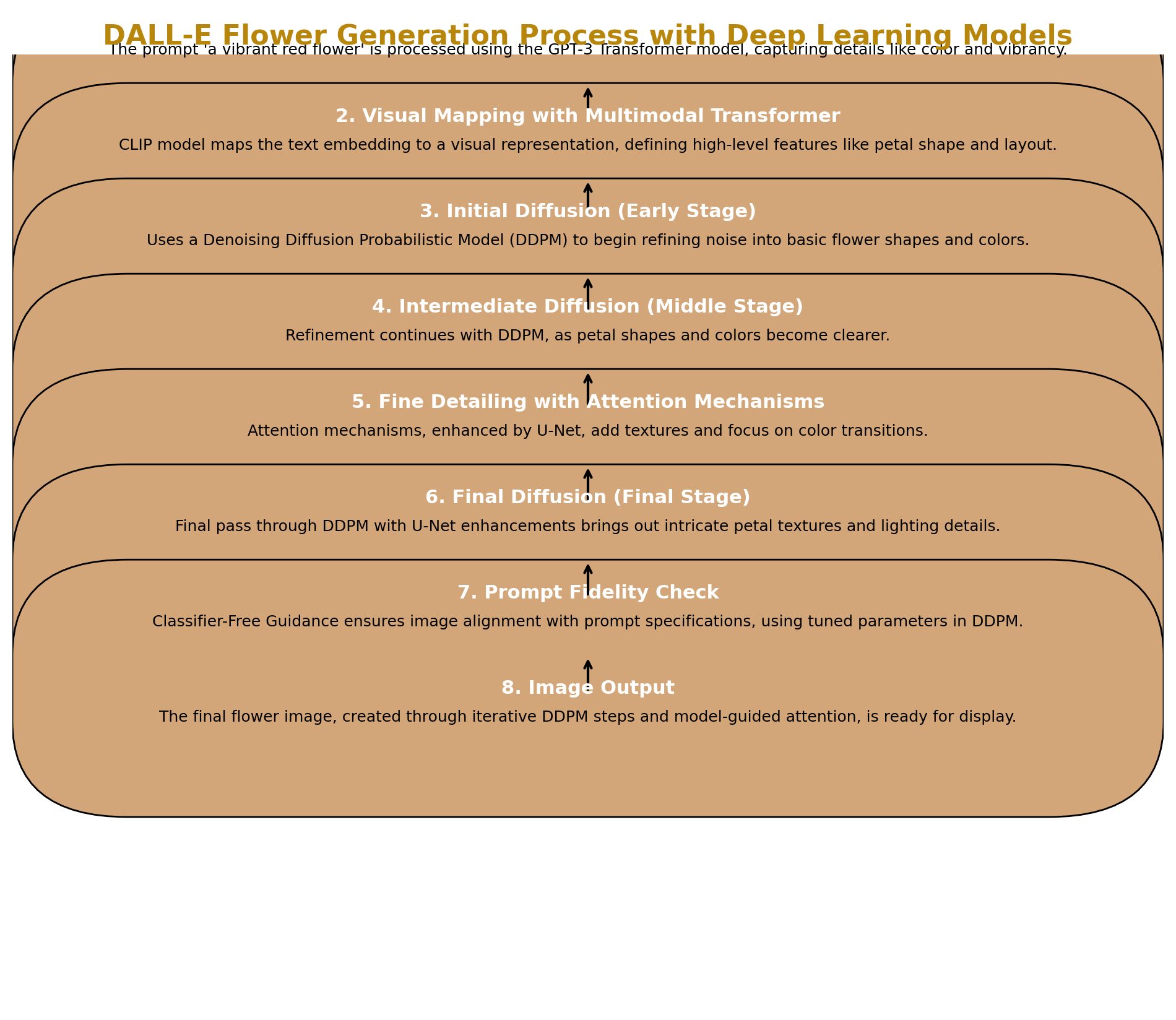
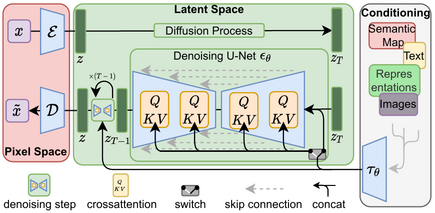
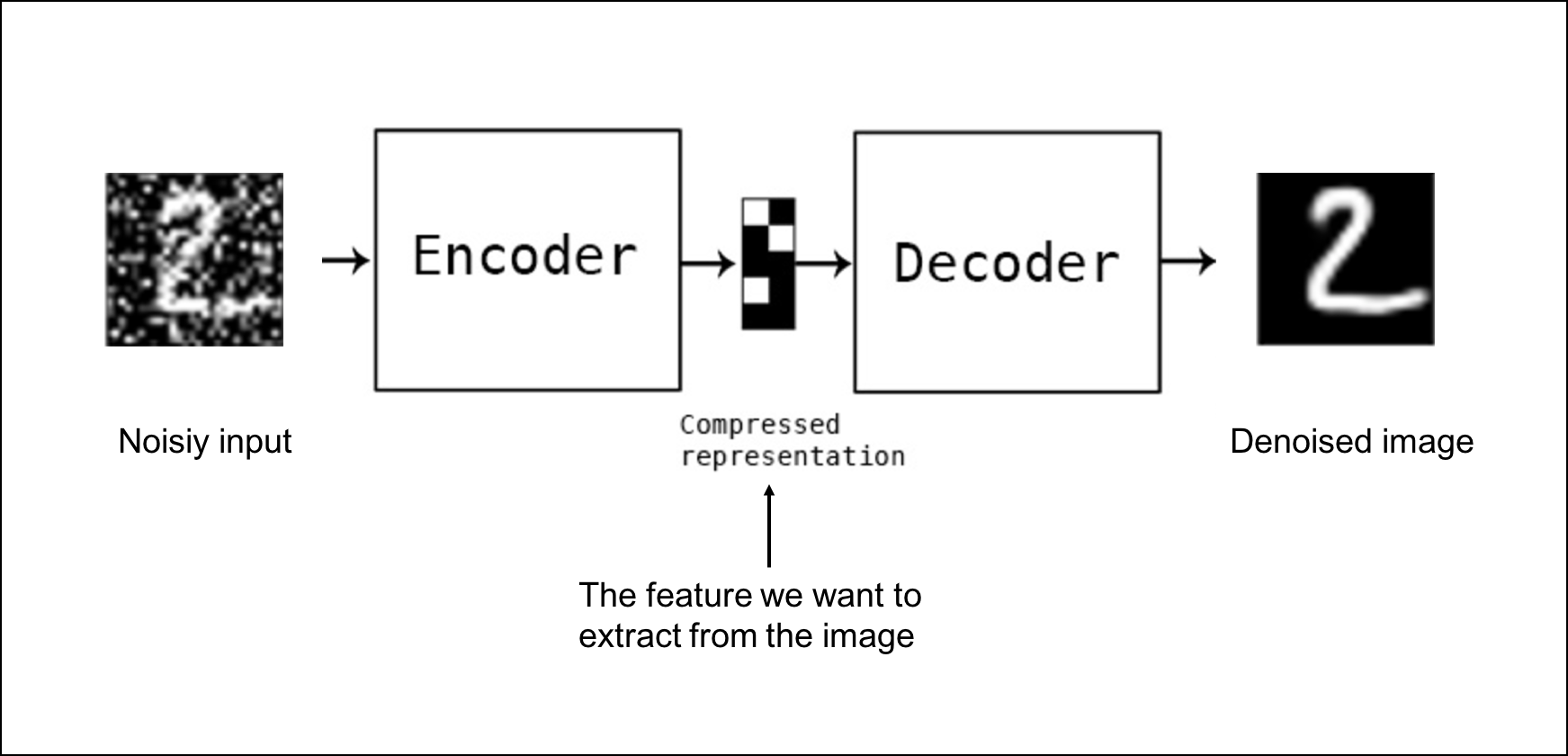
Deep Learning in 2024: Continued Insights and Strategies
Deep Learning in 2024: Latest Models, Applications, and Monetization Strategies Deep Learning in 2024: Latest Models, Applications, and Monetization Strategies In 2024, deep learning continues […]