Understanding Computation Graphs in Pytorch vs Tensorflow
Understanding Computation Graphs Understanding Computation Graphs in Deep Learning Part 1: Theoretical Explanation What Is a Computation Graph? A computation graph is a core concept […]
Understanding Computation Graphs Understanding Computation Graphs in Deep Learning Part 1: Theoretical Explanation What Is a Computation Graph? A computation graph is a core concept […]
Ipad pro – 2024 with m4 chips : Aspect Details Considerations CPU and GPU Multi-core CPU, 10-core GPU Efficient for basic processing and on-device inference […]

Solo Developer’s Guide to Building Competitive Language Model Applications A Solo Developer’s Guide to Building Competitive Language Model Applications With the explosion of large language […]
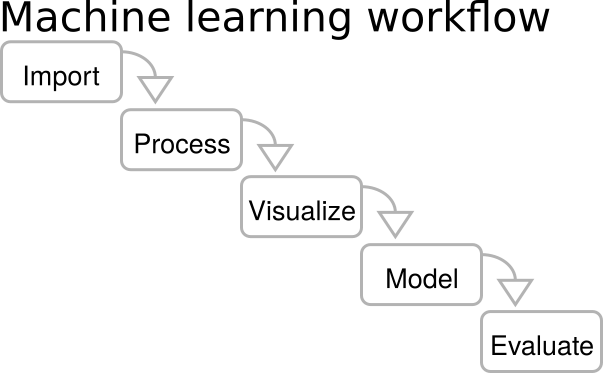
Where to Get Data for Machine Learning and Deep Learning Model Creation Where to Get Data for Machine Learning and Deep Learning Model Creation 1. […]

GPU and Computing Technology Comparison 2024 Exploring the Latest in GPU and Computing Technology: NVIDIA, Google Colab, Apple M4 Chip, and More In the rapidly […]
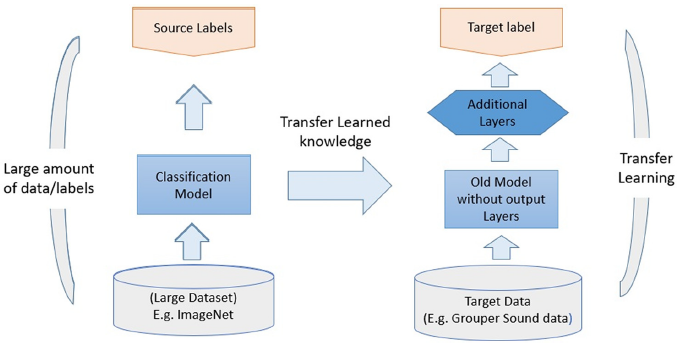
Fine-Tuning vs. Transfer Learning: Adapting Voice Synthesis Models Introduction In the world of deep learning, transfer learning and fine-tuning are essential techniques that enable pre-trained […]
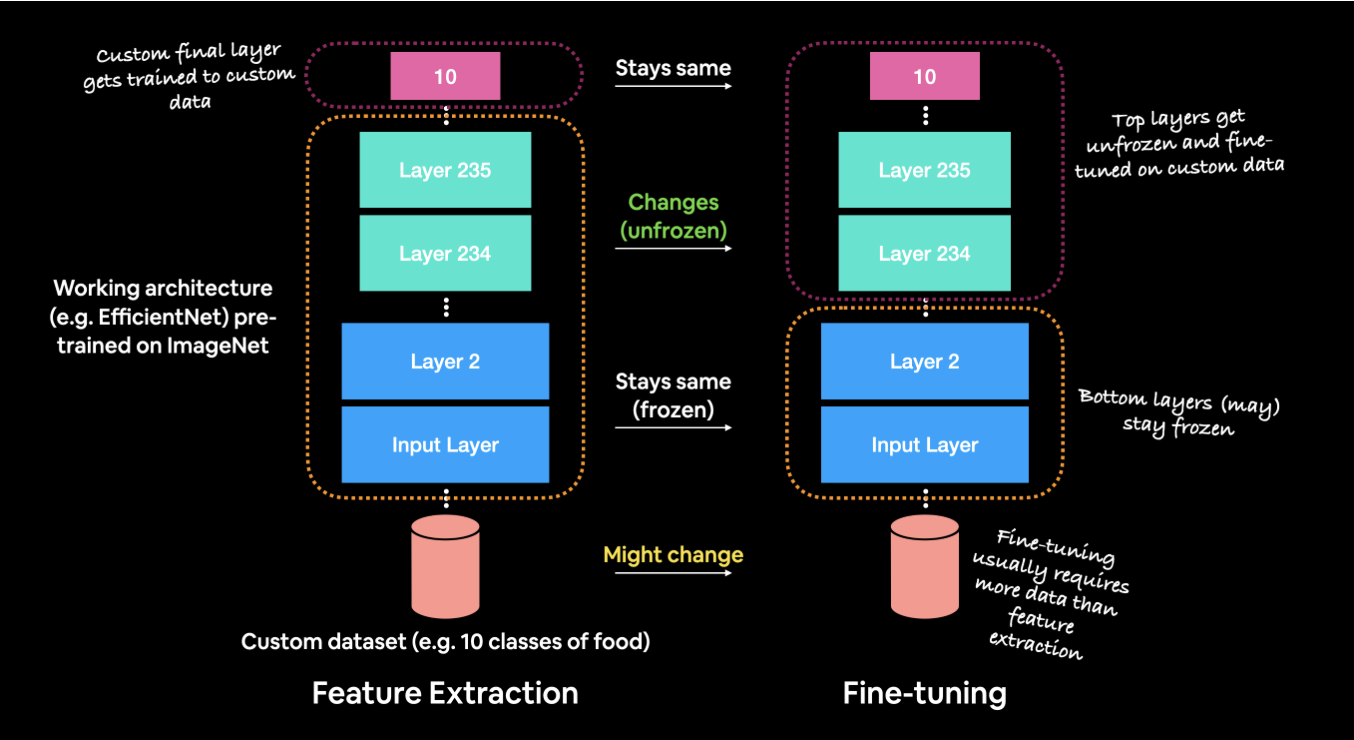
Understanding Fine-Tuning in Deep Learning Understanding Fine-Tuning in Deep Learning: A Comprehensive Overview Fine-tuning in deep learning has become a powerful technique, allowing developers to […]

DeepNet – Scaling Transformers to 1,000 Layers: The Next Frontier in Deep Learning Introduction In recent years, Transformers have become the backbone of state-of-the-art models in both NLP and computer vision, powering systems like BERT, GPT, and LLaMA. However, as these models grow deeper, stability becomes a significant hurdle. Traditional Transformers struggle to remain stable beyond a few dozen layers. DeepNet, a new Transformer architecture, addresses this challenge by using a technique called DeepNorm, which stabilizes training up to 1,000 layers. To address this, DeepNet introduced the DeepNorm technique, which modifies residual connections to stabilize training for Transformers up to...
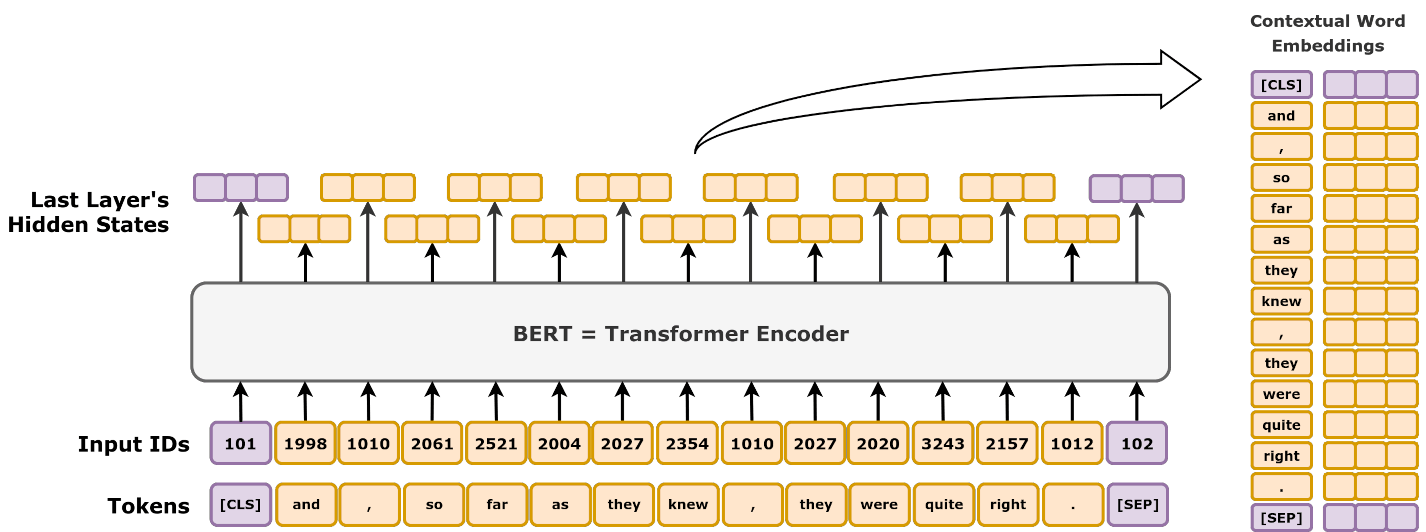
Transformers in Deep Learning (2024): Types, Advances, and Mathematical Foundations Transformers have transformed the landscape of deep learning, becoming a fundamental architecture for tasks in […]
New on 2024 – 2025 are MLX and Transofermers so lets compare Custom Deep Learning Models for iOS with MLX on Apple Silicon vs. PyTorch […]

For best results, phrase your question similar to our FAQ examples.