Autonomous AI Job Application Agents
Executive summary
AI systems that search for jobs and submit applications on behalf of users moved from “autofill helpers” to genuinely agentic products in 2025–2026. The sharpest distinction is between assistive application tools that speed up a user’s own clicks, and autonomous job-application agents that continuously discover openings, score fit, tailor materials, and either submit applications automatically or queue them for approval. Public vendor claims from Sonara, LoopCV, LazyApply, JobCopilot, AIApply, JobHire, and AutoApply.Jobs show that the market has converged on this end-to-end workflow, while large enterprise platforms have mostly remained on the employer-side API model rather than offering cross-platform “apply everywhere” agents for job seekers. [1]
From a technical standpoint, the safest and most durable architecture is hybrid: use official APIs where a platform or ATS explicitly permits them; use browser automation only on surfaces the user is authorized to access and whose terms do not prohibit the behavior; and escalate ambiguous steps, authentication challenges, and sensitive answers to a human-in-the-loop. LinkedIn, Indeed, and Glassdoor all publish constraints that matter here. LinkedIn’s public/open developer permissions are narrow, its talent APIs are partner-gated, and it explicitly prohibits third-party software that scrapes or automates website activity. Indeed offers partner APIs and OAuth-based integrations, but its terms explicitly prohibit automation of the Indeed Apply process outside official vendors and tooling. Glassdoor still exposes a public developer surface for job and employer search, but its current terms prohibit introducing automated agents, scraping, or impersonation without permission; Glassdoor job applications are now funneled through Indeed services. [2]
For researchers and developers, the most robust design pattern is an agentic pipeline with explicit state: profile ingestion, consent capture, retrieval across permitted sources, structured normalization, eligibility and risk filtering, retrieval-augmented application drafting, controlled submission, and post-application tracking via webhooks and status polling. On the model side, the strongest stack is not “one giant LLM,” but a layered system: layout-aware document parsing, named-entity and skill extraction, dual-encoder retrieval for broad recall, cross-encoder or LLM reranking for precision, and optional policy-learning or bandit/RL layers for submission timing and prioritization. Recent recruitment papers and adjacent agent/tool-use literature support this decomposition. [3]
Legally and ethically, the biggest risks are not abstract. They are concrete and immediate: violation of platform terms, impersonation, over-application, low-quality or misleading answers to custom questions, unfair ranking, mishandling of sensitive personal data, and opaque automated decision-making. Under the GDPR, controllers must have a lawful basis, provide notice, respect purpose limitation and data minimization, and handle profiling / solely automated decisions carefully; Article 22 and the EDPB guidance remain especially relevant where job decisions or significant filtering are automated. Under the CCPA/CPRA, notice at collection and consumer rights around access, deletion, and opt-out still matter for job-seeker data handling. In the EU, recruitment/selection systems are explicitly listed as high-risk use cases under Annex III of the AI Act, and official EU timeline pages accessed in July 2026 still state that Annex III high-risk rules enter into application on 2 August 2026. [4]
The practical conclusion is narrow but important. A compliant, high-quality AI job-application agent is possible, but only if it is designed as a consent-first orchestration system that prefers official APIs and employer-side surfaces, preserves user review rights, keeps cryptographic and audit controls around credentials and submissions, and treats anti-bot controls and CAPTCHAs as escalation points rather than obstacles to evade. [5]
Background and definitions
An AI job-application agent, in the rigorous sense relevant to this report, is a software system that does more than fill forms. It maintains a user model, retrieves or monitors openings, evaluates person–job fit, prepares or selects application materials, executes or stages the application transaction, and records the result for follow-up. That definition is consistent with how current vendors describe the category: Sonara says it “continuously finds and applies” to relevant openings, LoopCV says it “finds matching jobs, tailors your CV, and applies on your behalf,” JobCopilot says it “looks for new jobs,” filters them, and “automatically applies,” and AIApply says it matches users to jobs and applies to hundreds of roles for them. [6]
This definition excludes two adjacent categories. First, autofill assistants such as Simplify Copilot and Teal Autofill can be valuable but are not fully autonomous agents in the strict sense because their primary role is to help the user complete applications faster on supported pages, typically with on-page autofill and optional AI-generated answers. Second, employer-side recruiting APIs such as LinkedIn Talent APIs, Indeed Job Sync, Greenhouse, Lever, and SmartRecruiters are not job-seeker agents; they are infrastructure for employers, ATS vendors, job distributors, and approved partners. [7]
For research and systems design, it is useful to separate three operating modes:
| Operating mode | Core behavior | Example products / surfaces | Research relevance |
|---|---|---|---|
| Assistive | Autofills forms, suggests answers, tracks jobs, but the user still submits | Simplify Copilot, Teal Autofill [8] | Useful control group for studying autonomy vs. human oversight |
| Semi-autonomous | Agent discovers and prepares applications, but submits only after user approval | JobCopilot “auto-fill and save for review” mode; AutoApply.Jobs “Approve First” mode [9] | Often the safest production design |
| Autonomous | Agent continuously discovers, ranks, tailors, and submits applications on the user’s behalf | Sonara, LoopCV, LazyApply, AIApply, JobHire [10] | Main object of this report |
A second conceptual distinction is between platform-native application flows and off-platform redirection. LinkedIn Apply Connect, Indeed Apply, Greenhouse Job Board, Lever Postings, SmartRecruiters Application API, and Ashby application forms are actual application channels or structured application interfaces. By contrast, Google’s JobPosting structured data makes jobs discoverable in Google Search but does not itself provide an application transaction API; it points traffic to the publisher’s posting and application URL. [11]
For professors and researchers, the most defensible analytic definition is therefore:
An AI job-application agent is a consented software agent that performs at least four of five stages—discovery, matching, document adaptation, submission, outcome tracking—without requiring a new manual form interaction for every application. This is a synthesis from observed product behavior and official submission surfaces, not a statutory definition. [12]
Market timeline and survey
The 2025–2026 market appears to have two layers. The first layer is a set of consumer-facing vendors explicitly marketing “auto-apply” or “AI applies for you” experiences. The second layer is the employer/ATS infrastructure that these agents must either integrate with officially or navigate carefully. In public materials, I found strong evidence for a growing startup-heavy consumer market, but not for a large number of enterprise consumer products that autonomously apply across third-party sites on behalf of job seekers. The enterprise players remain mostly API and workflow providers to employers. [13]
The “size” labels in the following tables are analytical classifications, not audited headcounts. I label a vendor startup where the official footprint looks like an independent, venture-style or small-product company; SME where the official materials suggest a more established small/medium software business; and enterprise for large incumbent platforms or multinationals. When sources did not publish headcount, the label is an inference from founding information, user-scale claims, and product posture. [14]
Market survey for 2025
| Company | Size | Public 2025 evidence | What it offered in 2025 | Assessment |
|---|---|---|---|---|
| Sonara | Startup | Sonara’s 2025 materials describe AI-apply tools and workflows that automate finding jobs, tailoring, and submitting applications. [15] | Continuous job discovery and automated application submission. [16] | A clear example of a full autonomous application agent. |
| LazyApply | Startup | LazyApply’s official site and 2025-era pages describe automated job applications across platforms such as LinkedIn and Indeed. [17] | Browser-based auto-apply and form filling across multiple job sites. [18] | Strong automation, but it raises the highest platform-TOS exposure on restricted sites. |
| LoopCV | SME | LoopCV’s official guides and product pages in 2025 describe daily automatic applications across LinkedIn, Indeed, Glassdoor, and 30+ boards. [19] | Discovery, matching, CV tailoring, cover-letter generation, and auto-apply. [20] | Mature autonomous job-search platform with broad board coverage. |
| JobCopilot | Startup | JobCopilot published an “AI agent for job applications” page dated July 15, 2025 and official product pages describing automatic applications via verified company pages. [21] | Finds jobs, filters for relevance, and either auto-applies or stages for review. [22] | Notable for emphasizing official company career pages rather than job-board spraying. |
Market survey for 2026
| Company | Size | Public 2026 evidence | What it offered in 2026 | Assessment |
|---|---|---|---|---|
| Sonara | Startup | Sonara’s homepage and February 2026 guide explicitly say it continuously finds and applies to relevant jobs. [23] | Continuous autonomous job search and application. | One of the clearest “full agent” offerings. |
| LoopCV | SME | LoopCV says it auto-applies on LinkedIn, Indeed, Glassdoor, and 30+ boards; its about/careers pages say it was founded in 2019 and is used by 50,000+ job seekers. [24] | Broad autonomous multi-board application engine. | Probably the most explicit multi-board automation posture. |
| LazyApply | Startup | LazyApply’s 2026 site says its agent handles the entire application process and can automatically apply on multiple platforms. [25] | Browser extension driven auto-apply across supported platforms. | Technically simple distribution model; legally fragile on prohibited sites. |
| JobCopilot | Startup | JobCopilot’s homepage, about page, and responsible-AI page all position it as a job-application automation platform with configurable automation. [26] | Search, filter, auto-apply, track, with optional user review. | Strong semi-autonomous/autonomous design. |
| AIApply | Startup | AIApply’s official site says it auto-applies to thousands of jobs and pairs that with resume, letter, ATS scan, and interview tools. [27] | Full-stack “prepare + apply” workflow. | Broadest “application suite” positioning among consumer vendors. |
| JobHire.AI | Startup | JobHire says it searches and applies to hundreds of suitable jobs and offers auto-apply as a core feature. [28] | AI search plus automated submissions. | Relevant 2026 entrant, but less public integration detail than some rivals. |
| AutoApply.Jobs | Startup | AutoApply.Jobs says it blends AI and expert help for applications and offers “Approve First” or “Fully Auto.” [29] | Human-assisted or fully automated application execution. | Interesting hybrid between workflow automation and concierge service. |
Two broader market observations follow from these tables. First, the public consumer market is dominated by independent startups/SMEs, not by incumbent job boards or ATS providers. Second, the most legally conservative products increasingly position themselves around official company career pages or configurable review gates rather than indiscriminate cross-board spraying. That shift is plausibly a response to platform controls and terms, although that causal interpretation is an inference. [30]
Platform APIs and integration constraints
The platform landscape is asymmetric. Job-seeker agents want broad discovery and lawful submission; platforms usually expose employer-side APIs, not universal “submit a candidate anywhere” APIs. That means a serious implementation should treat every target as one of four integration classes: official application API, official posting/search API without submission, employer ATS API, or browser UI only. [31]
Official capabilities, scopes, and rate limits
| Platform / ATS | Official capabilities relevant to job agents | Auth / scopes | Rate limits / throttling | Important constraints |
|---|---|---|---|---|
Open permissions allow only OIDC profile/email and w_member_social; Talent partner programs cover Recruiter System Connect, Apply Connect, Apply with LinkedIn, and Premium Job Posting. Job Posting API is for authorized third parties such as ATSs/job distributors; Apply Connect lets approved partners manage jobs that members apply to on LinkedIn and receive applications via webhooks. [32] |
OAuth 2.0; member auth (3-legged) and app auth (2-legged). Public/open scopes visible in docs are profile, email, and w_member_social; talent access requires approval. [33] |
Standard rate limits are not published globally; LinkedIn says quotas vary by endpoint and app, visible in Developer Portal, and 429 is returned on overuse. [34] | No general public “apply to arbitrary LinkedIn job on behalf of member” API. Website scraping/automation is explicitly disallowed. [35] | |
| Indeed | Partner APIs for Job Sync, Sponsored Jobs, Hiring Lab, SCIM, and Direct Employer / Indeed Apply integrations. Job Sync keeps employer jobs fresh; direct employer integration can enable Indeed Apply metadata and screener questions. [36] | OAuth 2.0; 2-legged and 3-legged flows. employer_access is the base scope for employer account selection/access; many Sponsored Jobs endpoints need endpoint-specific scopes such as employer.advertising.campaign.read. Tokens expire in one hour. [37] |
Indeed assigns client-specific tiers and rate limits; Job Sync advises spreading requests over 10 minutes and returns HTTP 429 on excess volume. Indeed PLUS rate limiting is cost/tier based. [38] | Indeed’s terms explicitly prohibit automation, scripting, or bots for Indeed Apply outside official vendors and tooling. [39] |
| Glassdoor | Public developer APIs still expose job search and employer/company search; additional jobs APIs exist for API partners. Glassdoor job applications are submitted via Indeed services. [40] | Partner ID/key tied to Glassdoor account; public docs require userip and useragent in requests. [41] |
No current public rate-limit documentation was found in the reviewed official pages. | Terms prohibit automated agents, scraping/mining, multiple accounts, and impersonation without permission. [42] |
| Greenhouse | Job Board API exposes published jobs and supports POSTing applications; Candidate Ingestion API lets sourcing partners submit prospects/candidates; Harvest API exposes recruiting objects and updates. Webhooks support status/event tracking over HTTPS. [43] | Job Board POST uses Basic Auth with a Job Board API key; Harvest uses Basic Auth; Candidate Ingestion supports OAuth 2.0 or Basic Auth. [44] | Harvest requests are limited per 10 seconds by X-RateLimit-Limit; 429 on excess. Example header in docs shows 50 per 10 seconds. [45] |
Strong employer/partner surface. Better fit for explicit ATS integrations than generic browser automation. |
| Lever | Postings API can retrieve posting application questions and submit an application to a posting; Data API can create opportunities, but docs say to use the Postings API if you want to apply a candidate or build a custom job site. [46] | OAuth partner integration; offline_access yields refresh tokens; scopes include postings:read:admin, opportunities:write:admin, and many others. [47] |
Default 10 requests/second per API key, with bursts up to 20/second; token-bucket implementation. [48] | Applies only to postings in permitted states; file uploads require the upload endpoint before application submission. [49] |
| SmartRecruiters | Application API lets customers/partners integrate the application process into their own career site or job board and submit applications without sending the candidate to the SmartRecruiters ad. Posting API exposes public postings. [50] | Supports OAuth 2.0 Client Credentials and Authorization Code; candidate_applications_manage is required for Application API with OAuth. API keys are also supported on some surfaces. [51] |
Generally 10 requests/second and 8 concurrent requests, with lower limits on some endpoints; rate-limit headers are always returned. [52] | Posting API supports only API key auth, not OAuth. [53] |
| Ashby | Public Job Postings API lists published job postings; applicationForm.submit submits an application for a job posting; broader candidate/application endpoints exist for partner workflows. [54] |
API key with permissions; candidatesWrite required for application submission. Docs also expose fine-grained permissions for confidential jobs/private fields. [55] |
No official rate-limit page was captured in the reviewed sources. | Cleanest ATS-style surface for lawful application submission where a partnership or customer relationship exists. |
| Google Job Search | JobPosting structured data makes jobs eligible for Google’s job-search experience. It supports discovery and referral, not application submission. [56] | No end-user OAuth scope model here; this is search indexing/markup. | No submission rate-limit surface because it is not an application API. | Useful as a discovery layer, not a transaction layer. [57] |
Examples of permitted and forbidden actions
| Surface | Typically permitted by official docs / terms | Typically forbidden or unsupported |
|---|---|---|
| Sign in with LinkedIn via OIDC; approved talent-partner posting/integration flows; member-authorized posting/social actions under allowed scopes. [32] | Third-party software or extensions that scrape, modify appearance, or automate activity on LinkedIn’s website; false or non-authentic accounts. [58] | |
| Indeed | Official partner use of Job Sync, Sponsored Jobs, Indeed Apply, and employer OAuth flows. [59] | Automation, scripting, or bots to automate Indeed Apply outside official vendors/tooling. [39] |
| Glassdoor | Use of public job/employer search APIs with partner credentials and required attribution; partner-expanded APIs under agreement. [60] | Introducing automated agents, scraping/stripping/mining data, impersonating others, or creating multiple accounts without permission. [42] |
| Greenhouse / Lever / SmartRecruiters / Ashby | Official posting/application APIs, partner ingestion, and webhook-based status tracking. [61] | Using broader admin/data APIs where a narrower postings/application API is the intended integration; overbroad credentials or undocumented automation assumptions. [62] |
The practical implication is straightforward: if a developer wants a job-seeker agent that is durable, publishable, and defendable, the best target surfaces are ATS application APIs and explicit employer integrations, not brittle browser automation on platforms that explicitly ban it. [63]
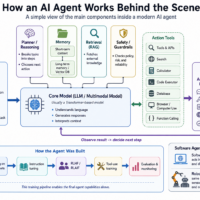
Technical architectures and implementation
A production-capable AI job-application agent should be structured as a stateful orchestration system, not as a single prompt calling a browser. The minimum viable architecture has six planes: identity/consent, user-profile memory, discovery/retrieval, matching/ranking, transaction execution, and observability/audit. Official platform and ATS docs strongly favor this decomposition because they separate authentication, job retrieval, application submission, and webhook/status events into distinct surfaces. [64]
Sample reference architecture

The identity and consent service should capture what the user authorizes the system to do, at what rate, on which surfaces, with which materials, and under what exceptions. This layer is not optional. It is the control point for lawful basis, notice, volume caps, employer blocklists, and “never answer these questions automatically” rules. That design is aligned with GDPR notice/profile requirements, CCPA notice-at-collection, and the practical need to avoid over-application or misrepresentation. [65]
The profile and document layer should produce a normalized candidate representation: skills, experience, locations, compensation constraints, work authorization, seniority, modality (remote/hybrid/on-site), language abilities, portfolio links, and negative preferences. For resumes and cover letters in PDF/DOCX, a layout-aware parser is important because naive text extraction destroys section order and tables; recent recruitment papers and parsing tools show why structured extraction matters. PyMuPDF can extract blocks and words with positional data; modern resume-parsing research uses layout-aware and multi-granularity extraction; spaCy or a domain model can then run NER / span extraction over normalized text. [66]
The retrieval layer should separate sources by trust and legality. Recommended ordering is: employer-provided ATS APIs and approved partner APIs first; structured search or feeds second; browser UI automation only as a constrained fallback. For semantic retrieval, sentence embeddings plus ANN indexing can provide high recall over normalized job postings, while richer models handle reranking later. [67]
The matching and ranking layer should be multi-stage. A good architecture uses a fast first-pass retriever (dual encoder / semantic search), then a higher-precision reranker (cross-encoder or LLM judge), then policy filters that reject jobs with low eligibility, visa mismatch, salary misfit, duplicate employers, or stale postings. Recent job-matching work supports encoder-retriever designs and LLM-enhanced reranking rather than direct end-to-end generation alone. [68]
The generation layer should be narrow and evidence-grounded. It can tailor resume bullets, synthesize cover letters, and draft answers, but it should ground every output in extracted profile facts and job-specific retrieval snippets. RAG is useful precisely because it gives the model non-parametric memory and provenance. Tool-using and reasoning-acting patterns such as ReAct and Toolformer are conceptually appropriate for orchestrating search, parsing, and submission tools, but in production they should be wrapped in deterministic policies and explicit guardrails. [69]
The execution layer is where session management matters most. Official APIs use OAuth, API keys, or Basic Auth, while browser workers use cookie/stateful sessions. Basic security practice here is to isolate one user per browser context, avoid credential reuse across workers, rotate/refresh tokens on their documented lifetimes, and never embed client secrets in client-side code. Indeed documents one-hour access tokens; Lever exposes refresh tokens with offline_access; LinkedIn separates member/app flows; Greenhouse and Job Board endpoints require different auth modes. OWASP and NIST guidance supports unique session identifiers, HTTPS-only transport, secure secret handling, and authentication lifecycle controls. [70]
End-to-end workflow
A rigorous end-to-end workflow looks like this:
- Onboarding and consent. The user uploads a resume, answers screening defaults, chooses automation mode, sets exclusions, and authorizes specific integrations. [71]
- Document normalization. The system parses the resume and profile into structured attributes, with confidence scores and editable fields. [72]
- Discovery. Connectors poll or receive jobs from approved APIs, ATS postings, or permitted pages. [73]
- Deduplication and normalization. Equivalent postings across boards are clustered by employer, requisition ID, title, locale, and URL features. This step is partly architectural inference but follows from the multiplicity of posting surfaces documented by boards and ATSs. [74]
- Eligibility and risk filtering. The agent rejects jobs that are clearly ineligible, suspicious, duplicate, or outside configured constraints. FTC job-scam guidance makes scam filtering a nontrivial safety requirement. [75]
- Matching and ranking. Retrieve broadly, rerank narrowly, then set a minimum threshold for autonomous submission. [76]
- Application package synthesis. The system selects or edits the resume, drafts a letter, and prepares answers from profile-grounded evidence. [77]
- Human review when needed. Route legal attestations, salary expectations, relocation answers, security-clearance questions, and any low-confidence generation to the user. This is a governance recommendation derived from GDPR/AI Act and platform-risk constraints. [78]
- Submission. Use the official API or ATS endpoint if available; otherwise use a permitted browser workflow under an isolated session. [79]
- Outcome tracking. Subscribe to webhooks where available, otherwise poll status pages or mailboxes under user authorization. [80]
Implementation guidance
Scalability. Use queue-backed workers, platform-specific connector services, and idempotent submission keys. Harvest, Lever, and SmartRecruiters all publish explicit rate and concurrency constraints, which means scheduler design should be rate-aware rather than purely throughput-driven. [81]
Error handling. Treat 4xx and 5xx differently. 429 should trigger platform-specific backoff using returned headers or documented retry guidance. Use durable state machines so a job application can move through discovered → normalized → scored → staged → submitted → confirmed → failed. LinkedIn, Indeed, Greenhouse, Lever, and SmartRecruiters all document 429 or related throttling behavior. [82]
Anti-bot detection and CAPTCHA. On sites that publish anti-automation prohibitions, CAPTCHA should be treated as a stop condition, not a puzzle to “beat.” The correct implementation is escalation to the user or abandonment of that surface in favor of an official integration. This is both a legal/compliance choice and a systems-reliability choice. [83]
Human-in-the-loop. Semi-autonomous review gates are not merely UX sugar. They are one of the clearest controls for reducing false answers, fraud risk, and regulatory exposure around profiling and automated decisions. Approved-with-edit review is the safest default mode. [84]
Consent management. Store versioned consent receipts: what data was uploaded, what platforms were authorized, what automation level was chosen, and when that consent was last refreshed. That design aligns with notice, transparency, and auditability needs under GDPR and CCPA. [85]
Audit logs. High-value actions should generate append-only logs: credential grant, job discovery source, model decision score, generated output hash, submission timestamp, webhook receipt, and human overrides. Greenhouse exposes audit and webhook patterns; OWASP emphasizes high-value transaction trails with integrity controls. [86]
Models and machine learning techniques
The model choice question is best answered by decomposing the pipeline. No single model class is ideal for all stages. Recruitment research increasingly supports this modular view: parsing, extraction, representation learning, recommendation/matching, reranking, explanation, and fairness auditing are distinct subproblems. [87]
Model families that fit the task well
Large language models. LLMs are appropriate for reasoning over complex qualifications, generating grounded explanations, drafting cover letters, and handling unstructured application questions. They are also useful as judges or rerankers on top of a narrower candidate set. But recent hiring evaluations also show that general-purpose LLMs need careful fairness testing and often benefit from being compared against task-specific match models rather than assumed to be superior by default. [88]
Retrieval-augmented generation. RAG is well suited to job-application agents because the system needs to bind generated text to user-provided evidence and job-specific facts. The original RAG work argued for combining parametric memory with non-parametric memory to improve specificity and factuality, which maps closely onto resume/job grounding. [89]
Dual encoders and semantic retrieval. For broad recall over large corpora of postings, embedding-based retrieval is efficient and robust to synonyms, abbreviations, and paraphrases. Recent recruitment work explicitly uses shared embedding spaces or dual-encoder structures for resume–job matching, and open-source sentence-transformer tooling fits this stage well. [90]
Cross-encoders / rerankers. After retrieval narrows the candidate set, cross-encoders or LLM judging can model richer token-level interactions between a resume and a job description. The literature around LLM-enhanced and dual-/cross-encoder matching supports this second-stage precision layer. [91]
Named entity recognition and structured extraction. Resume parsing still benefits from classic information extraction. Recent resume-parsing work continues to use NER-style formulations or hierarchical sequence labeling, often augmented by layout reasoning. spaCy is a practical open-source baseline, but domain fine-tuning is usually needed for resume-specific entities such as skills, degrees, dates, visa status, and clearance markers. [92]
Reinforcement learning and policy learning. RL is not the first tool for document parsing or matching, but it is plausible for the outer-loop policy problem: when to submit, how many applications per day, which job families to prioritize, and how to optimize long-run interview yield under rate limits and user constraints. PPO remains the canonical general-purpose policy-optimization reference, although in production a contextual bandit or constrained policy layer is often simpler and more auditable. [93]
Multi-agent systems. Multi-agent decomposition is attractive when the system must combine research, parsing, generation, validation, and execution under separate tools. The recent multi-agent literature around tool use and browser tasks supports this architecture, but the right lesson for hiring agents is to use small, observable agents with explicit contracts, not unconstrained “agent swarms.” [94]
Privacy-preserving ML. Where organizations train matching models on sensitive resumes and outcomes, differential privacy and federated/federated-fine-tuning approaches are relevant. The trade-off is real: privacy protections can reduce utility, especially on small or non-IID data, but they can materially reduce raw-data exposure and support collaboration across controlled datasets. [95]
Recommended model stack by function
| Function | Best-fit techniques | Why |
|---|---|---|
| Resume and profile parsing | Layout-aware parser + NER / hierarchical extraction | Resume formats are highly variable; layout and section order matter. [96] |
| Job retrieval | Sentence embeddings + ANN index | High recall over large corpora; tolerant of vocabulary mismatch. [97] |
| Final fit scoring | Cross-encoder or LLM reranker + structured rules | Better precision and better handling of nuanced constraints. [98] |
| Cover letters / questionnaire drafting | RAG-grounded LLM | Lets the system cite user facts and job-specific evidence instead of hallucinating. [99] |
| Tool orchestration | ReAct-style planner or constrained workflow engine | Suitable for search → retrieve → fill → validate sequences. [100] |
| Long-run optimization | Bandit / RL policy layer | Useful for prioritization, pacing, and experimentation. [93] |
| Privacy-sensitive training | DP / federated adaptation | Reduces centralized exposure of sensitive resume data. [101] |
The strongest empirical warning from recent hiring literature is about bias and fairness. Studies on job-resume matching and hiring-related LLM tasks consistently find that bias has not disappeared; explicit gender/race effects may decline in some settings, but educational and other implicit signals remain important, and allocational fairness must be tested directly rather than assumed. [102]
Ethics, legal, privacy, and security
The central ethical issue is delegated identity. A user-side job agent acts in a gray zone between assistance and representation. Once the system begins submitting applications, answering questions, or interacting under the user’s authenticated session, it can affect legal rights, reputational standing, and platform trust. That makes transparency, consent, and verifiability first-order design requirements rather than policy add-ons. [103]
Consent, profiling, and privacy
Under the GDPR, controllers must establish a lawful basis, provide transparent notice, limit processing to necessary purposes, and handle profiling responsibly. Article 22 is especially relevant where decisions are based solely on automated processing and produce legal or similarly significant effects; the EDPB’s profiling guidance remains the standard interpretive reference. Even where the job-seeker agent itself is “user-controlled,” downstream filtering models and automated ranking can still trigger these concerns if employers rely on them or if the service operator uses them opaquely. [104]
Under the CCPA/CPRA, businesses handling applicant or job-seeker data still need notice at collection and must support applicable consumer rights, including what data is collected and for what purpose. The official California materials emphasize both notice duties and response obligations. [105]
The privacy-design consequence is clear: job agents should collect only what they need, separate raw documents from derived features, support deletion/export, and avoid retaining generated questionnaire responses indefinitely unless the user explicitly chooses to preserve them. This recommendation is an implementation inference grounded in data-minimization and notice requirements. [106]
Impersonation, deception, and fraud
Several platform terms directly capture the impersonation risk. LinkedIn requires a real-name account and treats automated inauthentic activity as a basis for restriction. Glassdoor prohibits impersonating another person and creating accounts for anyone other than yourself. These provisions matter because an “autonomous apply” agent can easily cross from authorized assistance into quasi-impersonation if it submits misleading or fabricated answers, uses cloned browser contexts, or acts contrary to the user’s actual intent. [107]
Fraud risk is not limited to the applicant side. FTC job-scam guidance shows that employment scams actively target job seekers for money and personal information. A responsible job agent should therefore include scam heuristics, employer/domain verification, suspicious-payment detection, and manual confirmation for unusual flows. [108]
Platform terms and liability
For platform risk, the immediate legal reality is often contractual rather than statutory: account suspension, API revocation, blocked IP ranges, invalidated applications, or partner offboarding. LinkedIn’s help pages and user agreement, Indeed’s terms, and Glassdoor’s terms all make those enforcement risks explicit. Broader liability—fraud, unauthorized access, unfair/deceptive practices, or employment discrimination—depends on jurisdiction and facts, so it should not be overstated here. But the low-level point is certain: a developer cannot honestly present a LinkedIn/Indeed/Glassdoor browser-bot auto-apply product as “fully compliant” when the relevant public terms say otherwise. [109]
Bias, fairness, and transparency
Hiring is a high-stakes domain, and recent research shows that LLM-based job matching can reproduce unfair patterns. The literature reviewed here reports fairness concerns across gender, race, and educational background, and recent head-to-head evaluations recommend measuring both predictive quality and allocational fairness instead of treating them as substitutes. In the EU, this concern is reinforced by the AI Act’s explicit classification of recruitment and selection use cases as high-risk. [110]
In practice, transparency means at least four things: explaining what sources were used, showing the rationale for a match score, disclosing whether answers were AI-generated, and giving the user a way to review or override. For public-facing deployment, that is not only ethically superior; it is more defensible under profiling/transparency regimes. [111]
Security and data-protection best practices
A job-application agent inevitably handles highly sensitive data: resumes, addresses, salary history, citizenship/work authorization, diversity responses, and account credentials. Good practice therefore includes encryption in transit, encryption at rest, key rotation, secure secrets management, least-privilege scopes, session isolation, MFA-aware authentication flows, and tamper-evident audit logs. OWASP and NIST guidance support these controls directly. [112]
A concise risk matrix is useful:
| Design choice | Legal / platform risk | Privacy risk | Operational risk | Recommended posture |
|---|---|---|---|---|
| Official ATS / partner APIs | Lower, if contract scopes are respected. [113] | Moderate, because sensitive applicant data still flows. | Lower and more stable. | Preferred default |
| Employer career pages you control or are explicitly contracted to integrate with | Moderate, fact-dependent. | Moderate. | Moderate. | Acceptable with contract and notice |
| Browser automation on LinkedIn / Indeed / Glassdoor member-facing pages | High, because public terms explicitly restrict it. [83] | High, due to session and credential handling. | High, due to anti-bot controls and fragility. | Avoid in publishable systems |
| Fully autonomous answering of questionnaires | Moderate-to-high if answers become misleading or material. | High if sensitive fields are inferred or stored poorly. | High due to hallucinations. | Require review for sensitive or open-text prompts |
Evaluation, open-source tools, and open questions
A rigorous evaluation program should distinguish component quality from system utility. Parsing quality, retrieval quality, ranking quality, submission reliability, interview conversion, fairness, and user trust are not interchangeable. The recent hiring literature commonly evaluates predictive accuracy with ROC AUC, PR AUC, and F1, and fairness with impact-ratio style analyses across demographic groups. Resume-parsing work uses entity-level F1 / exact-match style measures. [114]
Recommended evaluation design
An academically clean design has four layers:
Parsing layer. Measure entity-level precision, recall, and F1 on gold resume annotations for skills, education, employers, dates, locations, and credentials. For section segmentation and key-value extraction, exact match or normalized-field accuracy is appropriate. [115]
Retrieval and ranking layer. Use recall@k or NDCG for job retrieval, then classification/ranking metrics such as ROC AUC, PR AUC, and F1 for final fit judgments. Recent hiring evaluations explicitly use ROC AUC, PR AUC, and F1 in real candidate-job settings. [116]
Operational layer. Measure application throughput, successful-submission rate, duplicate-submission rate, 429 incidence, CAPTCHA incidence, mean time-to-submit, and webhook/status reconciliation success. These are systems metrics derived from documented platform throttles and application workflows. [117]
Outcome and human factors layer. Measure recruiter response rate, interview rate, offer rate, user satisfaction, perceived control, and regret. A strong design should compare at least three modes: manual baseline, assistive/autofill, and semi-autonomous/autonomous. That comparison is especially important because “more applications” is not automatically “better applications.” This is a methodological inference, but it is strongly motivated by the contrast between automation vendors and fairness/performance studies. [118]
A concise metric set that would stand up well in publication is:
| Layer | Core metrics | Why they matter |
|---|---|---|
| Parsing | Field-level precision / recall / F1; section EM | Resume normalization quality determines everything downstream. [119] |
| Retrieval | Recall@k, NDCG@k | Broad but relevant candidate-job matching. [120] |
| Ranking | ROC AUC, PR AUC, F1 | Strong current practice in hiring-model comparisons. [116] |
| Fairness | Impact ratio / subgroup disparity; counterfactual or matched-pair bias tests | Hiring is high-stakes and fairness must be measured directly. [121] |
| Operations | Throughput, success rate, retry rate, 429 rate | Validates system reliability under platform constraints. [122] |
| User experience | Satisfaction, trust, override rate, regret | Necessary for credible deployment claims. |
Recommended open-source tools and a reference stack
The tools below are not all “job-agent libraries,” but they form a strong reference stack for building one.
| Layer | Recommended tools | Why |
|---|---|---|
| Browser automation | Playwright, Selenium WebDriver | Both are mature browser-automation stacks; Playwright explicitly positions itself for scripting and AI agents, and Selenium is the longstanding W3C WebDriver ecosystem. Use only on permitted surfaces. [123] |
| Document parsing | PyMuPDF | High-performance PDF extraction with positional text blocks and words, which is useful for reading order and layout-aware resume processing. [124] |
| NER / information extraction | spaCy | Industrial-strength open-source NLP with trainable NER and transformer support. [125] |
| Retrieval / embeddings | Sentence Transformers + Faiss | Practical semantic search stack for embeddings, ANN search, and reranking. [126] |
| RAG / agent orchestration | LlamaIndex | Open framework for agents and RAG pipelines as tools. [127] |
| Security reference | OWASP Cheat Sheets | Strong practical guidance for session management, auth, logging, REST security, and secrets. [128] |
A defensible reference architecture for an academic or publishable prototype would therefore use PyMuPDF + spaCy for normalization, Sentence Transformers + Faiss for retrieval, an LLM/RAG layer for rewriting and open-text answers, Playwright only for allowed surfaces, official ATS APIs whenever available, and an append-only audit layer aligned with OWASP logging guidance. [129]
Open questions and limitations
This report prioritizes primary sources and current official documentation, but several limitations remain. Glassdoor’s current public API documentation is still live, yet its modern partner/rate-limit details are thin in the official pages reviewed, so some current operational specifics are incomplete. [130]
Company-size classifications for the consumer auto-apply vendors are reasoned market labels rather than audited employee counts, because many of these companies do not publish authoritative headcount numbers on their own sites. [131]
Finally, there is still no broad public evidence that major incumbent job platforms want third-party job-seeker agents to submit applications cross-platform on behalf of members. The official API ecosystem remains overwhelmingly employer- and ATS-centric. That is the single most important structural fact about this market in mid-2026. [132]
References
[1] [6] [10] [12] [13] [16] [23] Sonara: AI Job Search Tool & AI Auto Apply
[2] [32] https://learn.microsoft.com/en-us/linkedin/shared/authentication/getting-access
https://learn.microsoft.com/en-us/linkedin/shared/authentication/getting-access
[3] [43] [44] [61] [63] [67] [79] https://developers.greenhouse.io/job-board.html
https://developers.greenhouse.io/job-board.html
[4] [65] [85] [104] [106] https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng
https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng
[5] [37] https://docs.indeed.com/getstarted/integrate-and-call-apis
https://docs.indeed.com/getstarted/integrate-and-call-apis
[7] [8] [118] Autofill Job Applications and Track Jobs | Simplify Copilot
[9] [22] [30] [84] Automate Job Applications with AI
https://jobcopilot.com/automate-job-applications/
[11] [31] [35] [113] https://learn.microsoft.com/en-us/linkedin/talent/apply-connect/create-apply-connect-jobs?view=li-lts-2026-03
[14] [131] https://www.loopcv.pro/about/
[15] AI Apply: How AI Is Transforming the Job Application Process
https://www.sonara.ai/blog/how-ai-is-revolutionizing-the-job-application-process
[17] Job search tools and tips, one click job apply
https://lazyapply.com/job-application-automation
[18] [25] LazyApply – AI for Job Search
[19] AI That Applies to Jobs for You Automatically — Free
https://www.loopcv.pro/jobseekers/
[20] [24] AI Job Search Automation – Auto-Apply to 1,000+ Jobs
[21] AI Agent for Job Applications – What to Use in 2026
https://jobcopilot.com/ai-agent-job-applications/
[26] JobCopilot: Automate Job Applications with AI
[28] https://jobhire.ai/
[29] https://aiapply.co/students
[33] [64] https://learn.microsoft.com/en-us/linkedin/shared/authentication/authentication
https://learn.microsoft.com/en-us/linkedin/shared/authentication/authentication
[34] https://learn.microsoft.com/en-us/linkedin/shared/api-guide/concepts/rate-limits
https://learn.microsoft.com/en-us/linkedin/shared/api-guide/concepts/rate-limits
[36] [59] [73] [122] https://docs.indeed.com/job-sync-api/job-sync-api-guide
https://docs.indeed.com/job-sync-api/job-sync-api-guide
[38] https://docs.indeed.com/support/faq
https://docs.indeed.com/support/faq
[39] Terms of Service
[40] [60] [130] https://www.glassdoor.com/developer/jobsApiActions.htm
https://www.glassdoor.com/developer/jobsApiActions.htm
[41] https://www.glassdoor.com/developer/companiesApiActions.htm
https://www.glassdoor.com/developer/companiesApiActions.htm
[42] Terms of Use | Glassdoor
https://www.glassdoor.com/about/terms/
[45] [81] https://developers.greenhouse.io/harvest.html
https://developers.greenhouse.io/harvest.html
[46] [47] [48] [49] [62] https://hire.lever.co/developer/documentation
https://hire.lever.co/developer/documentation
[50] https://developers.smartrecruiters.com/docs/application-api
https://developers.smartrecruiters.com/docs/application-api
[51] https://developers.smartrecruiters.com/docs/authentication
https://developers.smartrecruiters.com/docs/authentication
[52] https://developers.smartrecruiters.com/docs/rate-limiting
https://developers.smartrecruiters.com/docs/rate-limiting
[53] https://developers.smartrecruiters.com/docs/posting-api
https://developers.smartrecruiters.com/docs/posting-api
[54] https://developers.ashbyhq.com/docs/public-job-posting-api
https://developers.ashbyhq.com/docs/public-job-posting-api
[55] https://developers.ashbyhq.com/reference/applicationformsubmit
https://developers.ashbyhq.com/reference/applicationformsubmit
[56] [57] https://developers.google.com/search/docs/appearance/structured-data/job-posting
https://developers.google.com/search/docs/appearance/structured-data/job-posting
[58] [83] [109] Automated activity on LinkedIn | LinkedIn Help
https://www.linkedin.com/help/linkedin/answer/a1340567
[66] [129] https://pymupdf.readthedocs.io/en/latest/recipes-text.html
https://pymupdf.readthedocs.io/en/latest/recipes-text.html
[68] [90] https://arxiv.org/html/2503.02056v1
https://arxiv.org/html/2503.02056v1
[69] [89] [99] https://arxiv.org/abs/2005.11401
https://arxiv.org/abs/2005.11401
[70] https://docs.indeed.com/scim-api/scim-api-guide
https://docs.indeed.com/scim-api/scim-api-guide
[71] How to Use AI Auto Apply for Jobs & Land More Interviews
https://www.sonara.ai/blog/how-to-use-auto-apply-for-jobs-and-land-interviews
[72] https://arxiv.org/html/2511.02537v1
https://arxiv.org/html/2511.02537v1
[74] https://learn.microsoft.com/en-us/linkedin/talent/job-postings/api/job-posting-api-schema?view=li-lts-2026-03
[75] [108] https://consumer.ftc.gov/articles/job-scams
https://consumer.ftc.gov/articles/job-scams
[76] https://arxiv.org/html/2502.12361v1
https://arxiv.org/html/2502.12361v1
[78] [103] [111] https://ec.europa.eu/newsroom/article29/redirection/item/612053
https://ec.europa.eu/newsroom/article29/redirection/item/612053
[80] https://developers.greenhouse.io/webhooks.html
https://developers.greenhouse.io/webhooks.html
[82] [117] https://learn.microsoft.com/en-us/linkedin/shared/api-guide/concepts/error-handling
https://learn.microsoft.com/en-us/linkedin/shared/api-guide/concepts/error-handling
[86] https://developers.greenhouse.io/audit-log.html
https://developers.greenhouse.io/audit-log.html
[87] https://arxiv.org/html/2307.03195v3
https://arxiv.org/html/2307.03195v3
[88] [102] [110] [121] https://aclanthology.org/2025.naacl-industry.55/
https://aclanthology.org/2025.naacl-industry.55/
[91] https://arxiv.org/html/2604.02200v1
https://arxiv.org/html/2604.02200v1
[92] [115] [119] https://arxiv.org/pdf/2309.07015
https://arxiv.org/pdf/2309.07015
[93] https://arxiv.org/abs/1707.06347
https://arxiv.org/abs/1707.06347
[94] https://arxiv.org/html/2604.18133v1
https://arxiv.org/html/2604.18133v1
[95] [101] https://arxiv.org/html/2506.11687v2
https://arxiv.org/html/2506.11687v2
[96] https://arxiv.org/pdf/2510.09722
https://arxiv.org/pdf/2510.09722
[97] https://sbert.net/examples/sentence_transformer/applications/semantic-search/README.html
https://sbert.net/examples/sentence_transformer/applications/semantic-search/README.html
[98] https://arxiv.org/pdf/2604.02200
https://arxiv.org/pdf/2604.02200
[100] https://arxiv.org/abs/2210.03629
https://arxiv.org/abs/2210.03629
[105] https://oag.ca.gov/privacy/ccpa
https://oag.ca.gov/privacy/ccpa
[107] User Agreement
https://www.linkedin.com/legal/user-agreement
[112] https://cheatsheetseries.owasp.org/cheatsheets/REST_Security_Cheat_Sheet.html
https://cheatsheetseries.owasp.org/cheatsheets/REST_Security_Cheat_Sheet.html
[114] [116] https://arxiv.org/abs/2507.02087
https://arxiv.org/abs/2507.02087
[120] https://arxiv.org/html/2410.07671v2
https://arxiv.org/html/2410.07671v2
[123] https://playwright.dev/
[124] https://pymupdf.readthedocs.io/
https://pymupdf.readthedocs.io/
[125] https://spacy.io/
[126] https://sbert.net/
[127] https://developers.llamaindex.ai/python/framework/
https://developers.llamaindex.ai/python/framework/
[128] https://cheatsheetseries.owasp.org/cheatsheets/Session_Management_Cheat_Sheet.html
https://cheatsheetseries.owasp.org/cheatsheets/Session_Management_Cheat_Sheet.html
[132] https://learn.microsoft.com/en-us/linkedin/talent/job-postings/api/overview?view=li-lts-2026-03
https://learn.microsoft.com/en-us/linkedin/talent/job-postings/api/overview?view=li-lts-2026-03