What an AI Agent Really Is and How Systems Like ChatGPT and Claude Turn Models Into Action
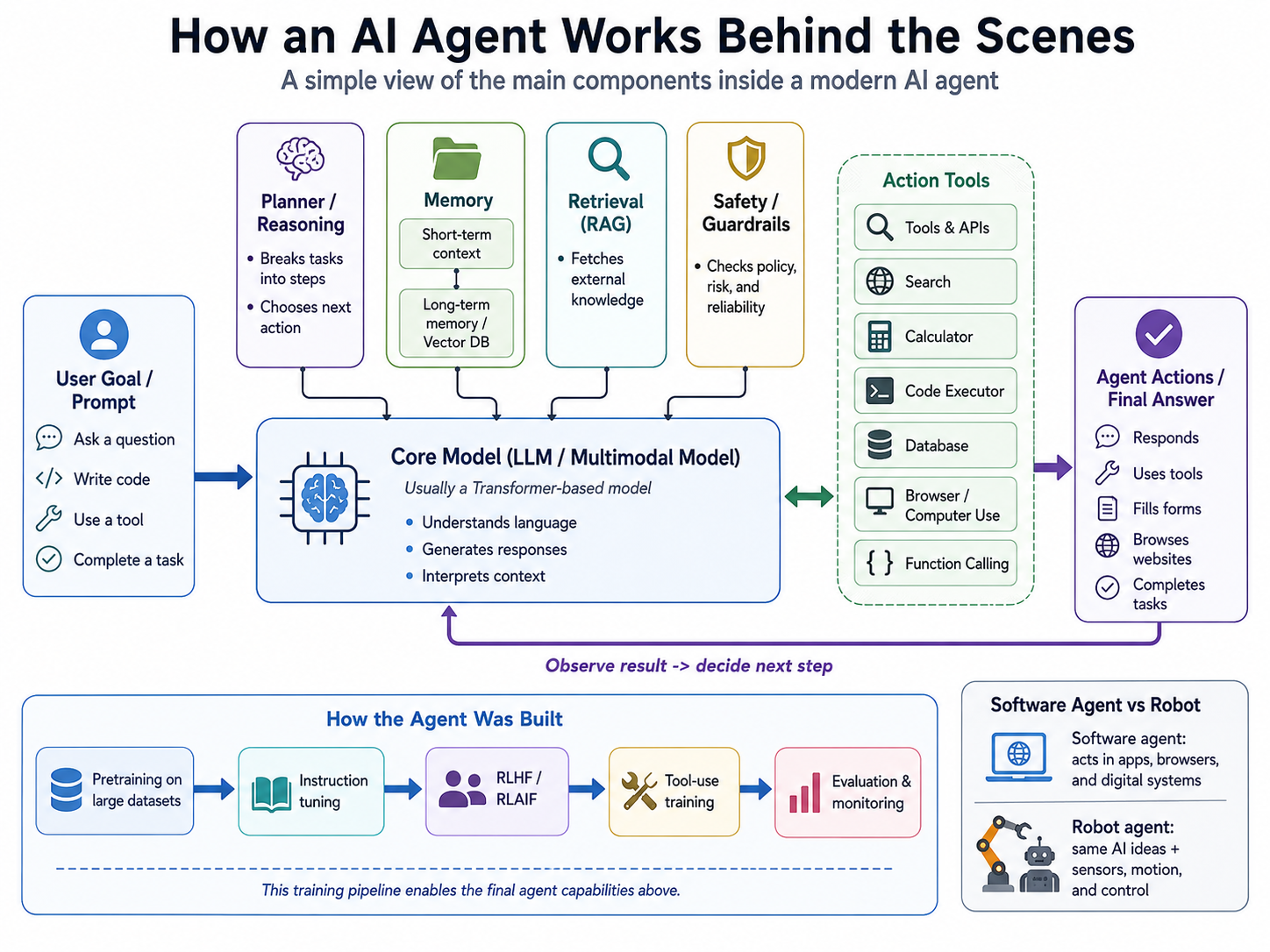
Most people use the phrase AI agent to mean “an AI that can do things.” That intuition is directionally right, but it is still too shallow. In the research literature, an agent is not merely a chatbot with better prompts. It is a goal-directed system that observes an environment, keeps track of state, decides on actions, executes those actions, and uses feedback to improve the next step. In the modern large-language-model era, that usually means a stack made of a foundation model, tool interfaces, memory or retrieval, policies and guardrails, and an execution loop that keeps running until the task is complete. Recent agent surveys describe LLM agents in exactly these terms, and both OpenAI and Anthropic now document agents as systems that plan, call tools, keep state, and complete multi-step work. [1]
If you want a publishable mental model, this is the most important idea in the whole topic: an agent is usually not one model. It is a runtime architecture built around one or more models. That is why the same base model can feel like a plain assistant in one product, a research agent in another, and a browser operator in a third. The model provides general intelligence; the surrounding system provides action. [2]
This article answers the questions people actually ask when they try to go deeper: what an AI agent is at a systems level, what is publicly known about how ChatGPT and Claude become agentic, which machine-learning components are usually inside an agent stack, how to build one yourself, how that differs from robotics, and what it takes to build a “digital robot” that can navigate websites, use software, and sometimes log in like a human worker. The analysis below relies on primary papers, official platform documentation, model system cards, and major research announcements rather than generic blog summaries. [3]
The deeper meaning of an AI agent
At a deeper level, an AI agent has three properties that a plain language model does not have on its own. First, it is goal-directed: it is trying to accomplish a task in the outside world, not just generate plausible text. Second, it is closed-loop: it observes the consequences of its actions and updates its next move accordingly. Third, it is environment-facing: it interacts with tools, files, APIs, browsers, operating systems, databases, or physical devices instead of only responding in natural language. Agent surveys published in 2024 and 2025 repeatedly converge on this structure, usually organizing the field around planning, memory, tool use, collaboration, and adaptation. [4]
The reason research moved in this direction is simple: raw language models are brilliant at pattern completion, but many real tasks require more than completion. They require looking things up, doing arithmetic, checking files, running code, browsing pages, or interacting through interfaces. That is why tool-use papers became foundational to the agent field. Toolformer showed that a model can be trained to decide when to call APIs and how to integrate the result back into token prediction. WebGPT showed that a model can browse the web to answer long-form questions and gather references. ReAct showed that alternating reasoning traces with actions significantly improves interactive decision-making, reporting absolute success-rate gains of 34 percentage points on ALFWorld and 10 points on WebShop over prior baselines. [5]
That leads to a useful distinction for your readers. A chatbot answers. An agent acts. A strong chatbot can still be weak as an agent if it cannot keep state, choose tools reliably, recover from errors, or verify its own work. Conversely, a smaller model can behave surprisingly well as an agent if it has high-quality tools, narrow task scope, strong retrieval, structured outputs, approvals, and tight evaluation loops. In production, agent quality is therefore a combined property of model capability + system design, not just model size. OpenAI’s own developer guidance increasingly frames this as an orchestration problem, and Anthropic’s tool-use documentation makes the same point by separating model decisions from application-side execution. [7]
What is publicly known about ChatGPT and Claude as agents
Neither OpenAI nor Anthropic publishes a full internal wiring diagram of their consumer products, so no outside writer should pretend to know the complete hidden architecture. What is public, however, is enough to establish the broad pattern. ChatGPT and Claude are not “just one transformer responding to text.” Public product notes and API documentation show a layered system in which a frontier language model is combined with tool use, structured function calling, memory features, retrieval or connectors, permissions, and runtime orchestration. OpenAI explicitly describes its Responses API as an agentic loop and its Agents SDK as infrastructure for tools, handoffs, approvals, and state. Anthropic’s docs likewise describe Claude deciding when to call tools and returning structured tool requests that the application executes, and Anthropic has expanded that stack with computer use, web search, code execution, text editing, and memory-related capabilities. [8]
For ChatGPT specifically, the public record shows a product layer that evolves over time as underlying model families change. OpenAI’s August 2025 launch notes said GPT-5 became the default model in ChatGPT for signed-in users, while 2026 release notes and help articles document ongoing retirement and replacement of older ChatGPT model options such as GPT-4o and other earlier families. That means the question “what model is inside ChatGPT?” does not have one timeless answer. The more accurate answer is that ChatGPT is a model-plus-runtime product that can sit on top of changing model families, memory systems, and tools. [9]
For Claude, the public picture is similar. Anthropic’s 2025 system card describes Claude Opus 4 and Claude Sonnet 4 as hybrid reasoning large language models with capabilities in reasoning, visual analysis, computer use, and tool use. Anthropic’s broader platform documentation shows the same architectural pattern: the core model sits inside a system that can use tools, web search, a computer-use interface, and memory capabilities, with Anthropic and the developer sharing responsibility for execution, approvals, and safety. [10]
The training philosophies also differ in publicly documented ways. OpenAI’s best-known alignment line for assistant behavior comes from instruction tuning and reinforcement learning from human feedback, as formalized in InstructGPT and earlier human-feedback work on summarization. Anthropic’s public alignment story adds Constitutional AI, where the model learns to critique and revise its own outputs against a set of principles, then undergoes reinforcement learning with AI feedback. Those methods are not the whole story of modern products, but they are central to why these systems behave more like assistants than raw next-token predictors. [11]
| Layer | What it does | What public sources suggest for ChatGPT and Claude |
|---|---|---|
| Foundation model | General reasoning, generation, planning, latent world knowledge | Frontier text or multimodal LLMs that change over time through model releases and retirements |
| Alignment layer | Instruction following, refusal behavior, helpfulness, tone | OpenAI: instruction tuning and RLHF; Anthropic: RLHF plus Constitutional AI-style training |
| Tool layer | Search, file access, code execution, connectors, browser or computer use | Both vendors publicly expose tool use; Anthropic also documents computer use in detail |
| Memory and retrieval | Cross-turn continuity, personalization, project context, external knowledge grounding | OpenAI documents ChatGPT memory; Anthropic documents memory systems and a beta memory tool |
| Runtime orchestration | State, retries, handoffs, approvals, tracing, step policies | OpenAI documents this through the Responses API and Agents SDK; Anthropic documents the agentic loop around tool use |
| Safety and governance | Permissioning, moderation, guardrails, prompt-injection defense, user approvals | Both vendors explicitly document security risks and recommend approvals or controls |
The table above is a synthesis from official docs, system cards, and core alignment papers. It is intentionally more accurate than saying “ChatGPT is model X” or “Claude is model Y,” because agentic products are layered systems. [12]
Which AI models usually make an agent work
If someone wants to build an AI agent, the first technical mistake is to ask only for “the best LLM.” High-performing agents usually combine several model types. The centerpiece is usually an autoregressive transformer language model, but it is rarely working alone. Depending on the product, the system often also uses embedding models for retrieval, rerankers or cross-encoders for search quality, vision-language models for screenshots and documents, reward or preference models for optimization, speech models for voice input and synthesis, specialized policy models for robotics or GUI action, and sometimes verification models or judge models for self-checking. Agent papers and platform docs increasingly treat this as normal system design rather than an exception. [13]
At the base of the stack is typically a transformer foundation model. This model is pre-trained on large corpora with self-supervised objectives, then often instruction-tuned and aligned using human or AI feedback. That gives you the broad reasoning and language interface. On top of that, tool-use methods make the model competent at deciding when an external system should take over. Toolformer is a canonical example of training a model to decide which API to call, when to call it, and how to use the returned result. ReAct is a canonical prompting-and-orchestration pattern in which reasoning steps and actions are interleaved during task execution. [14]
For knowledge-intensive agents, an embedding model is often as important as the main LLM. Embeddings convert documents, code, emails, or database entries into vectors so the system can retrieve likely-relevant context before the main model reasons. In practice, this is how many enterprise agents become more useful: not by storing everything inside the model weights, but by letting the model query fresh, private, or domain-specific data at runtime. OpenAI’s MCP and connectors documentation reflects exactly this design pattern, and Anthropic’s platform docs increasingly do the same via tools and memory systems. [15]
For multimodal or desktop agents, a vision-language model or visual pathway becomes essential. OpenAI’s Computer-Using Agent combines GPT-4o’s vision with advanced reasoning through reinforcement learning to operate graphical interfaces. Anthropic’s computer-use system similarly relies on screenshot understanding plus mouse and keyboard actions. Once your agent must deal with a browser or desktop instead of a clean API, perception quality becomes a major bottleneck. [16]
For robotics, the stack shifts again. Physical robots increasingly use vision-language-action models, which unify perception, language grounding, and action prediction. Google DeepMind’s RT-2 explicitly trained a vision-language-action model that learns from both web and robotics data. OpenVLA, one of the major open-source entries in this area, is a 7B VLA trained on 970,000 real-world robot demonstrations. Gemini Robotics and Gemini Robotics-ER push the same trajectory forward by combining embodied reasoning, perception, planning, and robot-oriented action generation. [17]
| Model type | Why agent builders use it | Common role in the stack |
|---|---|---|
| Instruction-tuned LLM | General reasoning, communication, planning, summarization | The “brain” of a digital agent |
| Reasoning-oriented LLM | Harder multi-step decision making, coding, verification | Planner, judge, or complex-task executor |
| Embedding model | Semantic search across private or fresh data | Retrieval, memory, project context, document grounding |
| Reranker or cross-encoder | Improves retrieval precision | Second-pass ranking before context is fed to the main model |
| Vision-language model | Reads screenshots, forms, dashboards, PDFs, UI state | Browser and desktop agents, multimodal support |
| Speech models | Voice interaction | Voice assistants, multimodal agents |
| Reward or preference model | Optimizes behavior toward helpfulness, safety, correctness | RLHF, self-improvement, ranking, post-training |
| Policy or action model | Maps observations to low-level actions | Robotics, GUI clicking, cursor movement, trajectory control |
| World model or simulator-backed planner | Predicts consequences before acting | Embodied agents, robotics, planning-heavy environments |
This table reflects what the literature and official product docs now imply very clearly: “AI agent” is not one model class. It is a coordinated assembly of model types serving different functions. [19]
How to build an AI agent like ChatGPT in practice
If you want to build something agentic like ChatGPT, the professional answer is not “train your own frontier model from scratch.” That is possible only for a tiny number of labs because pretraining and post-training frontier models require extraordinary compute, data, evaluation, and safety infrastructure. The practical route for almost every company is to build an agentic application on top of a strong model API or an already-available open-weight model, then add the runtime pieces that turn intelligence into action. OpenAI’s current docs make this explicit by separating basic model calls, tool use, and agent orchestration; Anthropic’s docs do the same. [20]
A good production blueprint has six stages. Start with one narrow job. For example: “research competitors,” “triage support tickets,” “prepare sales briefs,” or “navigate an internal dashboard to collect metrics.” The narrower the job, the easier it is to define tools, success criteria, and failure-recovery logic. Then pick the right model for that job, usually a strong text model for reasoning, and a multimodal model if the task involves screenshots or interfaces. Official OpenAI and Anthropic guidance both document model selection around task complexity and tool ambiguity rather than treating all agent tasks as the same. [21]
Next, define tools as clean interfaces. That means predictable functions with typed arguments and narrow permissions: search the knowledge base, run SQL against a read-only warehouse, fetch CRM data, write a draft email, or click in a sandboxed browser. Tool calling is the engineering heart of practical agents because it turns fuzzy natural-language intent into controlled machine action. This is why tool use appears so prominently in both major platform docs and in foundational research like Toolformer. [22]
Then add retrieval and memory sparingly. Developers often over-build memory and under-build retrieval. In most business settings, you want explicit context retrieval from documents, tickets, files, or databases, plus a small amount of durable state such as user preferences, task history, and current plan. OpenAI’s memory and connector materials, along with Anthropic’s memory-related docs, point toward exactly this split between user memory, project memory, and tool-based access to external systems. [23]
After that, implement the loop. A reliable agent is usually not one prompt. It is a loop that receives a goal, plans, chooses a tool, executes, reads the result, updates its state, and decides whether to continue, retry, escalate, or stop. ReAct remains one of the clearest research templates for this, while the Responses API and Agents SDK on OpenAI’s side, and Anthropic’s tool-use loop on Claude’s side, make that loop concrete for real products. [24]
Finally, add the production layer. This is where many demos fail. You need evaluation, tracing, observability, red-team testing, user approvals, spending limits, timeouts, structured outputs, idempotent actions, and rollback paths. OpenAI’s production best-practice and tracing docs, as well as Anthropic’s safety and data-retention documentation, all push in this direction. The lesson is blunt: the difference between a cool demo and a usable agent is usually infrastructure, not eloquence. [25]
A build path that is realistic for most teams
- Choose one workflow, not a universal assistant. A vertical agent beats a vague general agent in its first release. [26]
- Use a strong existing model first. Only consider custom training after you know the bottleneck is truly model behavior rather than tooling or prompt design. [27]
- Design a small toolset with explicit schemas and least privilege. Better three reliable tools than thirty vague ones. [28]
- Ground answers with retrieval. Put domain data outside the model and fetch it when needed. [29]
- Use structured outputs and validations. This reduces ambiguity and makes automation safer. [30]
- Add approvals for risky actions. Purchases, sending messages, deleting records, or credential entry should not be fully silent. [31]
- Instrument everything. Record tool calls, failures, retries, and cost so you can improve the system. [32]
- Evaluate on task success, not vibes. Agent benchmarks exist because fluent output can hide poor execution. [33]
How AI agents relate to robotics
AI agents and robots are deeply related, but they are not the same thing. A digital agent lives in software environments such as browsers, operating systems, APIs, and databases. A robot lives in the physical world and therefore must deal with geometry, occlusion, friction, latency, uncertainty, collision risk, and safety-critical control. Both can be understood as agents in the classical sense, but the required downstream models and systems differ sharply once real-world embodiment enters the picture. [34]
The shared part is the high-level loop: perceive, plan, act, observe, update. This is why language-model agent work transferred so naturally into robotics research. Google’s SayCan paired a language model with grounded robotic skills and reported 84% correct skill selection and 74% successful execution with PaLM-SayCan. RT-2 then moved farther by treating robot control as a vision-language-action problem, learning from both web-scale and robotic data to improve generalization. Gemini Robotics-ER and related work continue in that direction by combining perception, state estimation, spatial reasoning, planning, and code generation for robot control. [35]
The non-shared part is the control stack. A browser agent can usually tolerate a wrong click and try again. A physical robot cannot casually “retry” if the error means dropping glassware, colliding with a human, or becoming dynamically unstable. That is why robotics systems still rely heavily on classical controllers, motion planning, feedback control, simulation, state estimation, and hardware-specific safety layers beneath any language or vision-language model. DeepMind’s public robotics materials and recent embodied-AI surveys make this point explicitly: foundation models help with generality and reasoning, but low-level safety-critical control remains a distinct engineering layer. [36]
| Question | Digital AI agent | Robot or embodied agent |
|---|---|---|
| Main environment | Websites, apps, APIs, documents, operating systems | Homes, warehouses, factories, streets, labs |
| Main perception | Text, screenshots, UI state, files | Cameras, force sensors, proprioception, depth, tactile data |
| Main action type | Clicks, typing, API calls, code execution | Trajectories, grasping, locomotion, manipulation, tool use |
| Common model family | LLMs and VLMs with tool calling | VLA models plus planners and low-level controllers |
| Safety challenges | Prompt injection, data leakage, unwanted automation, account misuse | Collision, unstable motion, unsafe contact, task failure in the physical world |
| Failure cost | Usually reversible, though security and money can still be at risk | Potentially physically dangerous and expensive |
This is why it is misleading to ask whether the models are “the same.” They share concepts and increasingly share upper-layer architectures, but robotics adds embodiment, action grounding, and real-time control requirements that digital agents do not face. [37]
Can you build a digital robot that logs in and works like a human
Yes, in principle. In fact, one of the clearest current directions in the field is exactly that: a software agent that can use a browser or desktop the way a human does. OpenAI’s Computer-Using Agent was presented as a model that combines vision with advanced reasoning through reinforcement learning so it can interact with graphical user interfaces. Anthropic’s computer-use tool gives Claude screenshot perception and mouse-keyboard control for autonomous desktop interaction. These systems are best understood as digital robots: they are not physical bodies, but they do act in human software environments rather than purely through APIs. [16]
The obstacle is not only capability. It is security. The moment an agent can browse the open web, read email-like content, or operate in logged-in sessions, prompt injection becomes a central threat. Anthropic explicitly warns that using computer use in applications that require login increases the risk of bad outcomes from prompt injection. OpenAI’s security research makes the same broader point from another angle: prompt injections are a frontier security challenge for browser-based agents, and OpenAI has publicly argued that this class of attack is unlikely to be fully “solved” in a permanent, once-and-for-all way. [38]
That is the real reason many agent demos avoid personal logins or handle them cautiously. It is not because login is impossible. It is because a logged-in browser turns a model mistake into a real security, privacy, financial, or compliance incident. A safe production design therefore looks much more like enterprise identity engineering than like a magic prompt. You want scoped sessions, short-lived credentials, permission boundaries, step approvals for sensitive actions, preferably API integrations over raw GUI mimicry when available, isolated workspaces, audit logs, and secrets that are injected only when needed instead of sitting in plain conversation context. OpenAI’s approvals-and-security materials, Anthropic’s computer-use docs, and both companies’ prompt-injection discussions strongly support this architecture. [39]
If your goal is to make “a real robot inside the computer,” the mature strategy is to think in terms of degrees of autonomy. Start with read-only assistance. Then allow the agent to navigate and prepare drafts. Then allow low-risk writes. Only after strong evaluation should you allow high-impact actions such as purchasing, publishing, sending emails, or entering credentials. That progression mirrors how the research field itself has developed: from question answering, to tool calling, to web browsing, to full computer use, with safety and approval layers becoming more important at each step. [40]
What a safer digital-worker architecture looks like
| Design choice | Why it matters | Better practice |
|---|---|---|
| Raw browser automation with personal account always logged in | High prompt-injection and account-abuse risk | Use isolated sessions and keep sensitive accounts logged out unless explicitly needed |
| Credentials pasted into normal chat context | Secrets exposure and poor operational hygiene | Use a secrets vault or secure credential-injection layer |
| No human approval for payments or communications | Small errors become real-world incidents | Add user confirmation and policy gates for high-impact actions |
| Using GUI automation when an API exists | GUI is brittle, slower, and more attack-prone | Prefer stable APIs for core business actions; reserve GUI use for edge cases |
| No trace logs or replay | Hard to debug and hard to audit | Log decisions, tool calls, screenshots, approvals, and outcomes |
| Unlimited autonomy from day one | No containment for novel failure modes | Roll out autonomy gradually with benchmarks and red-team testing |
That table is the practical answer to a question many founders ask too late: not “can the agent log in?” but “under what security conditions should it be allowed to log in?” Official vendor documentation now makes clear that agent engineering is inseparable from security engineering. [41]
The most important takeaway for builders and executives
If you strip away the hype, the modern AI agent is best understood as a goal-seeking software system with a foundation model at the center and an action runtime around it. ChatGPT and Claude feel agentic not merely because their core models are strong, but because they are embedded in increasingly rich systems for memory, tools, retrieval, structured outputs, approvals, and sometimes browser or computer use. In public research, the decisive advances came from giving language models ways to act, observe, and improve inside environments. In production engineering, the decisive advances come from narrowing scope, grounding the model with data, instrumenting the loop, and controlling permissions. [42]
So if somebody wants to build an AI agent like ChatGPT, the correct roadmap is not “train something mystical.” It is: choose the workflow, choose the model, define the tools, add retrieval, implement a ReAct-style or tool-calling execution loop, add memory carefully, then invest heavily in evaluation, approvals, observability, and security. If they want a robot in the physical world, they must then go beyond that stack into embodied perception, action grounding, and hardware-safe control. If they want a robot inside the computer, they must go beyond clever prompting into browser safety, credential hygiene, and human-governed autonomy. That is what the literature and the official vendor documentation, taken together, now show very clearly. [43]
References
- Ouyang, Long, et al. Training Language Models to Follow Instructions with Human Feedback. NeurIPS, 2022. RLHF and instruction tuning as a core alignment recipe for assistant behavior. [44]
- Stiennon, Nisan, et al. Learning to Summarize from Human Feedback. NeurIPS, 2020. Early large-scale demonstration of reinforcement learning from human preferences. [45]
- Bai, Yuntao, et al. Constitutional AI: Harmlessness from AI Feedback. 2022. Anthropic’s public paper on self-critique and AI-feedback-based alignment. [46]
- Schick, Timo, et al. Toolformer: Language Models Can Teach Themselves to Use Tools. 2023. Foundational tool-use paper. [47]
- Nakano, Reiichiro, et al. WebGPT: Browser-Assisted Question-Answering with Human Feedback. 2021. Early browsing-based agent research with reference collection. [48]
- Yao, Shunyu, et al. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR, 2023. Foundational reasoning-plus-action template for agent loops. [49]
- Wang, Lei, et al. A Survey on Large Language Model Based Autonomous Agents. Frontiers of Computer Science, 2024. A widely cited overview of planning, memory, and tools in LLM agents. [50]
- Huang, Xu, et al. Understanding the Planning of LLM Agents: A Survey. 2024. Planning taxonomy for decomposition, reflection, memory, and external modules. [51]
- Luo, Junyu, et al. Large Language Model Agent: A Survey on Methodology, Applications and Challenges. 2025. Methodology-centered taxonomy of agent architectures. [52]
- OpenAI Developer Docs. Using Tools, Function Calling, Responses API, and Agents SDK. Public documentation of agentic loops, tools, approvals, tracing, and state. [53]
- OpenAI Help and Product Notes. ChatGPT Capabilities Overview, Memory FAQ, and model release notes. Public evidence that ChatGPT is a changing product layer with model, memory, and orchestration features. [54]
- Anthropic Docs and System Cards. Tool Use, Computer Use, memory-related docs, and the Claude Opus 4 & Claude Sonnet 4 System Card. Public evidence for hybrid reasoning models and agentic tooling. [55]
- Ahn, Michael, et al. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. 2022. SayCan paper on language models grounded in robot skills. [56]
- Brohan, Anthony, et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. 2023. Major VLA milestone in robotics. [57]
- Kim, Moo Jin, et al. OpenVLA: An Open-Source Vision-Language-Action Model. 2024. Open-source VLA trained on 970k real-world robot demonstrations. [58]
- Google DeepMind. Gemini Robotics Brings AI into the Physical World. 2025. Public description of embodied reasoning, planning, and robot control. [59]
- OpenAI. Computer-Using Agent and Introducing Operator. Public description of vision-plus-reasoning GUI agents and reported benchmark performance. [60]
- OpenAI and Anthropic security materials on prompt injection and browser or computer use. Essential reading for anyone who wants a logged-in digital worker. [61]
[1] [2] [4] [6] [13] [19] [42] [50] A survey on large language model based autonomous agents
https://link.springer.com/article/10.1007/s11704-024-40231-1?utm_source=chatgpt.com
[3] [11] [14] [44] Training language models to follow instructions with …
https://arxiv.org/abs/2203.02155?utm_source=chatgpt.com
[5] [47] Toolformer: Language Models Can Teach Themselves to Use Tools
https://arxiv.org/abs/2302.04761?utm_source=chatgpt.com
[7] [12] [21] [31] Agents SDK | OpenAI API
https://developers.openai.com/api/docs/guides/agents?utm_source=chatgpt.com
[8] Migrate to the Responses API
https://developers.openai.com/api/docs/guides/migrate-to-responses?utm_source=chatgpt.com
[9] Introducing GPT-5
https://openai.com/index/introducing-gpt-5/?utm_source=chatgpt.com
[10] System Card: Claude Opus 4 & Claude Sonnet 4
https://www-cdn.anthropic.com/4263b940cabb546aa0e3283f35b686f4f3b2ff47/claude-opus-4-and-claude-sonnet-4-system-card.pdf?utm_source=chatgpt.com
[15] [29] MCP and Connectors | OpenAI API
https://developers.openai.com/api/docs/guides/tools-connectors-mcp?utm_source=chatgpt.com
[16] [60] Computer-Using Agent
https://openai.com/index/computer-using-agent/?utm_source=chatgpt.com
[17] [57] RT-2: Vision-Language-Action Models Transfer Web …
https://arxiv.org/abs/2307.15818?utm_source=chatgpt.com
[18] [40] [48] Browser-assisted question-answering with human feedback
https://arxiv.org/abs/2112.09332?utm_source=chatgpt.com
[20] [39] OpenAI API Platform Documentation
https://developers.openai.com/api/docs?utm_source=chatgpt.com
[22] [28] [53] Using tools | OpenAI API
https://developers.openai.com/api/docs/guides/tools?utm_source=chatgpt.com
[23] Memory FAQ
https://help.openai.com/articles/8590148-memory-faq?utm_source=chatgpt.com
[24] [43] [49] Synergizing Reasoning and Acting in Language Models
https://arxiv.org/abs/2210.03629?utm_source=chatgpt.com
[25] [26] Production best practices | OpenAI API
https://developers.openai.com/api/docs/guides/production-best-practices?utm_source=chatgpt.com
[27] Model optimization | OpenAI API
https://developers.openai.com/api/docs/guides/model-optimization?utm_source=chatgpt.com
[30] Agent output – OpenAI Agents SDK
https://openai.github.io/openai-agents-python/ref/agent_output/?utm_source=chatgpt.com
[32] Tracing – OpenAI Agents SDK
https://openai.github.io/openai-agents-python/tracing/?utm_source=chatgpt.com
[33] A Survey on Evaluation of LLM-based Agents
https://arxiv.org/html/2503.16416v2?utm_source=chatgpt.com
[34] [37] A Comprehensive Survey on Embodied AI
https://arxiv.org/html/2407.06886v8?utm_source=chatgpt.com
[35] SayCan: Grounding Language in Robotic Affordances
https://say-can.github.io/?utm_source=chatgpt.com
[36] [59] Gemini Robotics brings AI into the physical world
https://deepmind.google/blog/gemini-robotics-brings-ai-into-the-physical-world/?utm_source=chatgpt.com
[38] [41] Computer use tool – Claude API Docs
https://platform.claude.com/docs/en/agents-and-tools/tool-use/computer-use-tool?utm_source=chatgpt.com
[45] Learning to summarize from human feedback
https://arxiv.org/abs/2009.01325?utm_source=chatgpt.com
[46] Constitutional AI: Harmlessness from AI Feedback
https://arxiv.org/abs/2212.08073?utm_source=chatgpt.com
[51] Understanding the planning of LLM agents: A survey
https://arxiv.org/abs/2402.02716?utm_source=chatgpt.com
[52] Large Language Model Agent: A Survey on Methodology …
https://arxiv.org/abs/2503.21460?utm_source=chatgpt.com
[54] ChatGPT Capabilities Overview
https://help.openai.com/en/articles/9260256-chatgpt-capabilities-overview?utm_source=chatgpt.com
[55] Tool use with Claude – Claude API Docs
https://platform.claude.com/docs/en/agents-and-tools/tool-use/overview?utm_source=chatgpt.com
[56] Do As I Can, Not As I Say: Grounding Language in Robotic …
https://arxiv.org/abs/2204.01691?utm_source=chatgpt.com
[58] OpenVLA: An Open-Source Vision-Language-Action Model
https://arxiv.org/abs/2406.09246?utm_source=chatgpt.com
[61] Understanding prompt injections: a frontier security challenge
https://openai.com/index/prompt-injections/?utm_source=chatgpt.com