Solo-developer AI products in early 2026: iOS, SaaS, marketplaces, and low-cost robotics
Executive synthesis
Now days, The opportunity for solo developers has shifted from “build a chatbot” to “ship a narrowly-scoped workflow product that uses LLMs as an invisible engine”. The technical barrier to building has fallen because (a) open-weight models now cover small-to-medium model sizes suitable for laptops and edge devices, (b) parameter-efficient fine-tuning (PEFT) and low-bit quantisation make adaptation feasible without a GPU cluster, and (c) deployment can be “serverless”, “on-device”, or “in-browser” depending on privacy and cost constraints. [1]
Demand-side signals also support niche, workflow-focused products: Stanford’s AI Index 2025 reports that generative AI private investment reached $33.9B in 2024 and that 78% of organisations reported using AI in 2024 (up from 55% the year prior), indicating widespread adoption pressure across industries. [2] At the same time, enterprise-scale transformation remains rare: “The GenAI Divide” deck (MIT/NANDA, 2025) characterises adoption as high but “scaled integration” as low (for example, it highlights that only a small minority have integrated AI into workflows at scale). That gap is exactly where solo “micro-SaaS” and “micro-plugins” can succeed—by solving a specific job in a specific toolchain. [3]
The competitive reality in 2026 is that generic consumer AI apps are saturated. The defensible lane for a solo developer is usually one (or more) of: distribution-first marketplaces (App Store / Chrome Web Store / Shopify / Atlassian / Slack), privacy-first local/offline, or an underserved niche with high-intent searches and willingness to pay. [4]
LLM technology landscape
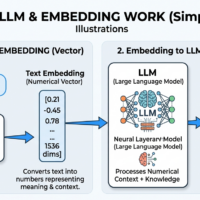
The “default” architecture remains Transformer-based (self-attention), but modern product-facing models in 2026 increasingly emphasise longer context windows, multimodality, tool use/function calling, and “routing” architectures like Mixture-of-Experts (MoE) to increase capability without linearly increasing inference cost. [5]
An example of practical way for solo developers is to think in “tiers” of models you can build on:
Open-weight general-purpose models for self-host or local use have matured. Meta’s own Llama repository documents releases through Llama 4 and summarises key properties (sizes, context lengths, licensing, acceptable use policies), making it clear that “open” does not mean “no-strings”—you must accept licence terms and comply with usage policies. [6] Google’s Gemma 3 family explicitly positions “relatively small” variants as deployable on “laptops, desktops, or your own cloud infrastructure”, and the Hugging Face ecosystem provides first-class support for these models. [7] Alibaba’s Qwen family likewise positions itself as a continuously released suite of LLMs and multimodal models; Qwen’s own repo explicitly calls out Apple Silicon–friendly MLX support for Qwen3 via mlx-lm. [8]
MoE is now “mainstream” in open models. Mistral’s Mixtral release describes a sparse MoE where a router selects two experts per token (out of eight) and combines their outputs, which improves efficiency because only a subset of parameters is active per token. [9] This matters to solo developers because it accelerates the trickle-down of “strong model quality” into smaller, cheaper inference footprints—especially when combined with quantisation and efficient serving backends.
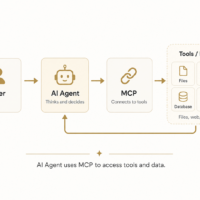
Agentic workflows are becoming a platform primitive rather than an app-layer hack. On the OpenAI side, the Responses API and built-in “tools” (web/file search, computer use, etc.) are described as agent-native building blocks, and OpenAI’s year-end 2025 developer roundup highlights a “move toward agent-native APIs” and better tool calling support. [10] On the open ecosystem side, Hugging Face’s function/tool calling documentation frames tools as the structured mechanism for models to trigger real actions (and not just generate prose). [11]
Many “software products” are now best modelled as (LLM) + (tools) + (retrieval) + (guardrails/evals) rather than as a single monolithic model. That’s a good thing for solo builders, because product value can come from the toolchain and workflow, not from training a frontier model.
Fine-tuning and post-training methods that matter in 2026
Most solo-developer fine-tuning that is economically sensible falls into two buckets: parameter-efficient fine-tuning (so you don’t retrain all weights) and preference-based post-training (so outputs match what users want without full RLHF complexity).
Parameter-efficient fine-tuning: LoRA remains foundational. The LoRA paper (ICLR 2022) describes freezing most pretrained weights and injecting low-rank trainable matrices into layers, avoiding the cost of full fine-tuning. [12] QLoRA extends this idea by fine-tuning through a frozen 4-bit quantised base model into LoRA adapters, reducing memory enough that (in their experiments) even very large models become fine-tuneable on a single high-memory GPU. [13] In practice, this is why solo developers can realistically fine-tune small-to-mid open models on prosumer GPUs and, sometimes, on higher-memory Apple Silicon machines (with the right tooling and expectations).
Preference-based post-training has become “offline and practical”. Direct Preference Optimisation (DPO) reframes RLHF-style alignment into a simpler classification-style loss without explicit reward modelling loops, aiming for stability and reduced complexity. [14] After DPO, 2024 introduced multiple “simplify further” approaches including ORPO (monolithic, reference-free preference optimisation during SFT) and KTO (alignment with a binary desirable/undesirable signal, inspired by prospect theory), plus SimPO which proposes a reference-free reward formed from average log probability and introduces margins for better separation. [15]
Crucially for solo developers, these methods are not just papers: Hugging Face TRL’s documentation positions TRL as a full-stack library supporting SFT, DPO, reward modelling, and other post-training methods. [16] Meanwhile, OpenAI’s platform documentation explicitly describes fine-tuning workflows and lists supervised fine-tuning, DPO, and reinforcement fine-tuning as supported options in its “model optimisation” guidance. [17]
A key strategic decision is whether you should fine-tune at all. Retrieval-Augmented Generation (RAG) was originally formalised as combining parametric memory (the model) with non-parametric memory (a retrievable index), improving knowledge-intensive tasks and enabling updates without retraining the model. [18] Modern developer docs (LangChain, LlamaIndex) frame retrieval as the solution to finite context and static knowledge, which is why many production apps in 2026 prefer RAG first, fine-tune second. [19]
Practical “solo-friendly” rule of thumb in 2026: fine-tune when you need consistent style/format/tool-call behaviour or domain-specific patterns that prompts can’t reliably enforce; use RAG when you need up-to-date or proprietary knowledge grounding; combine both when you need “company tone + grounded facts”.
Examples of Deployment options that are realistic for solo developers
Some example of Solo developers can be chosen among five viable deployment modes, each with different cost, ops burden, and privacy implications.
On-device deployment is materially more capable than it was in 2023. Apple’s Core ML documentation frames Core ML as a unified representation for models, supporting on-device prediction and also “train or fine-tune” workflows using user data. [20] Apple’s Core ML pages and WWDC material emphasise improved support for “advanced generative” models on-device, including granular weight compression, multifunction models, and execution patterns that help with large language models and adapters. [21] This makes “privacy-first local AI” a genuine distribution differentiator for iOS/macOS products, not just a marketing slogan.
Local desktop deployment has become normalised through tools like llama.cpp and Ollama. The llama.cpp project explicitly targets minimal-setup inference across diverse hardware (local and cloud) and includes quantisation tooling, while Ollama positions itself as a simple way to run open models locally with a developer-friendly API. [22] For a solo developer, this enables a “no cloud bill” product class: one-time paid apps that run models locally, possibly paired with optional paid cloud features.
In-browser deployment is becoming credible for certain classes of models. Transformers.js runs models in the browser using ONNX Runtime, and Hugging Face documents WebGPU as a new standard enabling GPU compute in-browser, which is well-suited for client-side ML. [23] This enables products that are essentially “static sites” (low ops) with embedded ML—in 2026, that can mean local summarisation, embeddings, classification, lightweight Q&A, or multimodal demos, depending on model size.
Self-hosted GPU serving remains the most flexible but also the most operationally intense. vLLM’s research paper introduced PagedAttention to reduce KV-cache waste and improve concurrency for LLM serving, and vLLM is now a standard choice for open-model serving stacks. [24] Hugging Face’s Text Generation Inference (TGI) is explicitly positioned as a deployment toolkit with production use at Hugging Face itself, and it supports features like continuous batching and model optimisations. [25] NVIDIA’s TensorRT-LLM is positioned as an open-source inference optimisation library with features such as quantisation and speculative decoding, aimed at maximising NVIDIA GPU throughput and latency. [26]
Managed deployments (serverless APIs and managed endpoints) are increasingly compelling for solo developers because they compress operational complexity into a bill. Hugging Face Inference Endpoints is documented as a managed service for deploying models to production on dedicated autoscaling infrastructure. [27] AWS explicitly positions SageMaker LMI containers as a way to deploy and optimise LLM inference, and AWS has announced LMI container versions powered by vLLM. [28] Modal’s “deploy vLLM” tutorial illustrates a serverless model: you can run vLLM on cloud GPUs with autoscaling and cache model artefacts to reduce cold starts. [29]
Sellable product landscape with real-world examples a solo developer can emulate
The “audio → text → summary → chat” stack is one of the most proven solo-friendly patterns because it is a complete workflow with clear value and clear pricing. OpenAI’s Whisper was trained on 680,000 hours of multilingual audio and is widely used for transcription and translation. [30] Indie and small-team apps demonstrate that packaging this into a product is feasible: the macOS app MacWhisper markets on-device transcription and privacy-first workflows, and it is openly discussed by the developer in the Whisper.cpp community. [31] On iOS, apps like “Whisper Transcription” explicitly advertise share-sheet transcription, optional on-device models (for certain devices), and AI summaries/chat over transcripts—features a solo developer can realistically replicate using existing model APIs or local inference runtimes. [32] AudioPen similarly positions itself as converting voice notes into clean text, and it exists as both web and mobile apps, reinforcing that “voice-to-structured writing” is a durable consumer workflow. [33]
“Chat with documents” remains a high-demand category, but the differentiation has moved from “it chats” to “it’s trustworthy, cites sources, and plugs into your workflow”. Products like AskYourPDF and PDF.ai demonstrate multi-surface distribution: web + mobile + Chrome extension, plus integrations (e.g., Zotero in AskYourPDF’s case). [34] Under the hood, this is usually RAG: parse documents, chunk, embed, retrieve, then answer with citations. The core RAG concept is well-established in the literature and modern frameworks. [35]
Browser-based summarisation is simultaneously crowded and newly interesting because the platform itself is adding primitives. Chrome’s documented Summarizer API indicates that developers can offer summarisation directly in the browser with different lengths and formats—reducing the need for an external LLM call for certain users/environments. [36] Independently, Chrome Web Store listings like “Briefy” show that “summarise + build a knowledge base + chat” is an existing extension pattern. [37] The risk here is commoditisation; the opportunity is to specialise (e.g., summarise compliance pages, summarise medical papers with structured extraction, summarise bug reports into Jira-ready tickets).
Reader/knowledge-work assistants are maturing into “prompt libraries + retrieval + automation”. Readwise Reader’s Ghostreader docs describe summarisation that triggers on items you manually save and supports custom prompt libraries—essentially productising prompt engineering into a repeatable user workflow. [38]
Finally, there is a strong and growing “local-first AI” segment driven by privacy and predictable costs. Home Assistant explicitly describes integrating cloud or local LLMs (including local via Ollama) so users can “chat” about their smart home state; this shows that “local LLM + domain context + tool access” is increasingly normal outside Big Tech. [39]
Table of product patterns, real-world references, and solo-build feasibility
| Product pattern (solo-friendly framing) | Real-world examples (today) | Core ML/LLM technique likely used | Why a solo dev can build it | Distribution that can work with minimal active marketing |
| Voice notes → clean text → summaries | AudioPen (web + iOS), VoicePen (web + apps) | ASR + LLM rewrite/summarise | Clear “job to be done”; simple UX; can start by calling APIs, later optimise locally | SEO for “voice to text”, app stores, creator communities [40] |
| Local transcription + privacy-first | MacWhisper | On-device Whisper / local inference | One-time purchase model is viable when cloud costs are avoided; strong privacy narrative | Direct sales + word-of-mouth + niche communities (journalists, podcasters) [41] |
| iOS “transcribe + chat with transcript” | Whisper Transcription (iOS) | ASR + summarisation + Q&A over transcript | Mobile UX is straightforward; transcripts are structured data; can hybrid local/cloud | App Store search + subscriptions [42] |
| Chat with PDFs / docs (general) | AskYourPDF, PDF.ai | RAG + citations | Frameworks and vector DB tooling are mature; can specialise by domain | SEO (“chat with PDF”), Chrome Web Store, integrations (Zotero etc.) [43] |
| “AI inside an existing workflow tool” plugin | Shopify App Store apps; Atlassian Marketplace apps; Slack apps | Tool-calling + RAG over workspace data | Smaller surface area than building a full product; users already pay for workflows | Marketplace search and category browsing [44] |
| Browser extension that summarises/extracts structured data | Chrome Web Store summariser extensions | LLM summarise/extract, possibly local browser AI | Very fast iteration and low infrastructure; can upsell with subscription | Chrome Web Store discoverability [45] |
| Local-first smart-home “advisor” | Home Assistant LLM chat | Local LLM + tool access to sensors | Niche community; clear value (summaries of sensor states, automations) | Community add-ons + forum-driven discovery [46] |
| In-browser ML app (no server) | Transformers.js apps | ONNX Runtime + WebGPU | Near-zero ops; privacy-first; good for lightweight tasks | SEO + GitHub + “use it in browser” virality [47] |
Minimal-marketing distribution: marketplaces, organic discovery, and niche demand
“Minimal marketing” rarely means zero effort; it means choosing distribution channels where users are already searching and where your product page, reviews, and keywords do the selling.
App marketplaces remain powerful, but economics and rules matter. Apple’s App Store Small Business Program documents a 15% commission rate for developers under $1M in proceeds, which makes subscription-based indie iOS apps more viable than the old 30% baseline. [48] Apple’s own guidance on discoverability stresses that categories and search/browse placement influence how customers find apps. [49] In the EU, however, distribution and payment rules are shifting under regulatory pressure; Reuters reported changes to App Store rules in the EU to allow more external linking/payment options (with new fee structures), which means solo developers targeting Europe should actively track policy changes rather than assume stable economics. [50] Apple also documents marketplace search configurations for alternative marketplaces (including sitemap-based approaches), signalling that “app discovery” might increasingly extend beyond the App Store itself in certain regions. [51]
SaaS/platform marketplaces are arguably the most underappreciated organic channel for solo developers, because they combine high-intent discovery with built-in billing norms. Shopify’s developer docs state that partners pay 0% revenue share on the first $1,000,000 in gross app revenue earned on or after 1 Jan 2025, then 15% above that threshold—an unusually strong incentive for “micro-SaaS” built as a Shopify app. [52] Atlassian’s developer blog announced that (from 1 Jan 2026) qualifying standard Forge apps will also benefit from a 0% revenue share incentive up to a lifetime revenue threshold (with “Runs on Atlassian” apps already benefiting), making “build a Jira/Confluence AI helper” a distribution-first route with attractive take-home economics. [53] Slack’s documentation describes Marketplace distribution as a reviewed process, which can be a quality filter and therefore a discovery advantage once listed. [54]
Browser extensions remain one of the fastest “ship and iterate” channels. Google’s Chrome Web Store publishing docs describe an end-to-end workflow for listing extensions (including distribution controls), which can support freemium/paywalled models and country targeting. [55] In 2026, browser platform AI features (like Chrome’s summarisation API) may also reduce your inference costs for certain users—if you design your product to opportunistically use built-in capabilities when present. [36]
A practical solo-developer playbook for low-marketing distribution is:
Build where the buyer already is: pick one “home” marketplace (App Store, Shopify, Atlassian, Chrome Web Store, Slack) and treat it as your primary acquisition channel. Your marketing becomes product page optimisation, reviews, and solving a real workflow problem; not paid ads.
Optimise for high-intent search terms: “chat with PDF”, “transcribe meetings locally”, “summarise Jira tickets”, “generate Shopify product descriptions”, etc. These queries often come with users ready to pay.
Use integrations as distribution: an integration directory listing is itself a marketing channel. The marketplace listing is a landing page with built-in trust signals and intent.
Business models and monetisation that fit LLM/deep-learning products
Monetisation is constrained by two forces: LLM inference costs (or the hardware you must provide) and user tolerance for subscriptions. The most robust solo models are those that align price with cost drivers, while keeping value clear.
A key operational reality: if you rely on paid API calls, you need unit economics discipline (routing, caching, smaller models on easy tasks, batching where possible). If you can run locally (on-device or on the customer’s hardware), you can sell one-time licences or lifetime deals more sustainably because marginal inference cost approaches zero.
Table of monetisation models suited to LLM products
| Model | Works best for | What to charge for | Why it fits LLM economics | Risks / mitigations |
| Subscription (individual) | Consumer productivity apps (voice notes, doc chat) | Ongoing access + new features | Smooths variable compute costs; users understand it | Churn; reduce by focusing on a daily/weekly habit loop (e.g., “inbox” workflows) |
| Usage-based (credits / tokens / minutes) | Transcription, OCR-heavy doc workflows | Measurable units (minutes audio, pages, docs) | Aligns cost to revenue; reduces “power user” losses | User confusion; mitigate with simple tiers + overage pricing |
| Hybrid (seat + usage) | B2B assistants and integrations | Per-seat base + usage beyond included quota | Predictable base revenue, fair scaling with heavy usage | Billing complexity; mitigate with clear dashboards |
| One-time licence | Local-first, offline products (macOS tools) | App purchase + paid upgrades | Works when inference is local; avoids perpetual cloud cost | Requires continuous value via updates; offer upgrade pricing or “major version” pricing |
| Marketplace add-on | Shopify / Atlassian / Slack apps | Workflow feature in-platform | Marketplace discovery + built-in billing norms | Platform risk (policy changes); mitigate with email list + export features |
| “Open-core” + paid hosting | Developer tools, agents infrastructure | Hosted convenience and support | OSS builds trust and organic discovery | Support burden; keep scope tight and automate onboarding |
Marketplace economics can materially improve outcomes. Apple’s 15% small business commission changes indie iOS calculus, while Shopify and Atlassian explicitly lower rev-share for the first $1M under defined conditions—strong tailwinds for solo builders who choose “ecosystem apps” as the go-to-market. [56]
Robotics opportunities and realistic solo pathways, plus practical hardware/software stacks
Robotics is attractive but easy to underestimate: physical products add manufacturing, support, safety, and returns. The “no marketing budget” constraint makes robotics software (or hardware-adjacent add-ons) far more realistic than building a full robot.
The most viable solo robotics opportunities :
Smart home and consumer “robotics-adjacent” systems. Home Assistant is a strong example of a community-driven ecosystem where local control and privacy are valued, and it explicitly supports chatting with integrated LLMs—locally via Ollama or through cloud models. [39] Home Assistant also offers a “Voice Preview Edition” hardware path that is explicitly privacy-focused and intended for community development. [57] For a solo developer, this suggests a clear product direction: build a paid Home Assistant add-on that turns voice + sensors into a “home operator” with explainable actions (and optionally runs on-device).
Robotics middleware plugins and “LLM as planner” patterns. ROS 2 documentation emphasises modular nodes communicating through topics/services/actions—an architecture that maps naturally to tool-calling agents (each ROS action becomes a tool). [58] Research like SayCan demonstrates a pattern where an LLM proposes high-level steps constrained by grounded skill/value functions, showing why “LLM as brain + skills as hands” is a robust approach. [59] A solo developer can emulate this without building novel robot learning: use an LLM for planning and language understanding, but execute through deterministic controllers and validated action libraries in ROS.
Low-cost edge AI hardware for “robot perception” and voice. Raspberry Pi is explicitly pushing into local generative AI: Raspberry Pi announced the AI HAT+ 2 (Hailo-10H + 8GB on-board RAM) to bring LLM/VLM capability to Raspberry Pi 5, and the product page lists a launch price of $130. [60] This creates a credible solo path for small “robot brains” that do local perception (camera + VLM), basic planning, and voice, especially when paired with ecosystems like Home Assistant or lightweight ROS 2 robots.
If you specifically want to integrate LLMs with robot policies, open robotics foundation models exist, but shipping them as a solo product is usually a longer-term play. OpenVLA is an open-source vision-language-action (VLA) model trained on ~970k robot demonstrations. [61] Octo is a transformer-based generalist robot policy trained on 800k trajectories and claims it can be fine-tuned to new robot setups within a few hours on “standard consumer GPUs”. [62] The near-term solo opportunity here is not “sell a general-purpose robot model”, but “sell a packaged integration”: a calibrated policy + tooling + dataset + deployment guide for one specific low-cost robot platform (e.g., a small arm, a camera turret, or a mobile base).
Table of practical stacks for solo developers (Mac M-series, NVIDIA GPUs, edge devices, and cloud)
| Target | What it’s good for | Accessible tools/frameworks | Key constraints (solo-relevant) | Suggested product fit |
| MacBook (Apple Silicon) | Prototyping, small fine-tunes, local inference for privacy | PyTorch MPS backend (Apple + PyTorch), Core ML / coremltools, MLX framework | Single-GPU-per-machine for MPS; some ops missing; fallbacks may be needed [63] | Privacy-first desktop apps; local summarisation/search; offline assistants |
| NVIDIA GPU workstation | Faster training + serving; quantised inference at scale | PyTorch (CUDA), bitsandbytes (4-bit), TRL (SFT/DPO), vLLM/TGI/TensorRT-LLM | Driver/CUDA compatibility; GPU memory limits dictate model size [64] | B2B SaaS with predictable cost; higher-throughput APIs; multi-user apps |
| Browser (client-side) | Zero-server demos and lightweight inference | Transformers.js + WebGPU + ONNX Runtime | Model size/latency limits; browser support variability [47] | Niche in-browser tools; privacy-first text analysis; lead-gen into paid SaaS |
| Raspberry Pi 5 + AI HAT+ 2 | Edge LLM/VLM experiments; local “robot brain” | Pi AI HAT+ 2 stack (Hailo-10H), Home Assistant pipelines, local model runners | Tight model size constraints; power and thermal limits [65] | Smart-home local assistants; camera scene summaries; low-cost robotics add-ons |
| Serverless/managed cloud | Fast launch, scalable inference without DevOps overhead | Hugging Face Inference Endpoints, AWS SageMaker LMI (vLLM), Modal vLLM deployments | Ongoing costs; vendor dependency; need cost controls [66] | Early-stage SaaS; variable traffic; B2B pilots; marketplace integrations |
Actionable robotics project ideas that don’t require huge budgets
Local smart-home “operator” that explains actions: build a Home Assistant add-on that uses an LLM to interpret goals (“make the living room cosy”), proposes an automation plan, and then executes via Home Assistant services with explicit human confirmation. Distribution can be community-driven (add-on store, GitHub) and monetised via paid binaries, a hosted config UI, or a subscription for premium features. The viability is supported by Home Assistant’s explicit positioning of LLM chat integrations (including local via Ollama) and its push into voice hardware. [67]
ROS 2 “natural language to action” bridge for a specific robot class: package a ROS 2 node that converts a constrained set of intents into ROS actions/services (navigation, gripper open/close, camera pan/tilt). Sell it as a commercial licence to labs and makers who want quick demos, with a free community edition. ROS 2’s modular “nodes + topics” architecture supports this decomposition cleanly. [58]
Edge camera “scene log” kit on Raspberry Pi 5: use Raspberry Pi 5 + AI HAT+ 2 to run a vision-language model locally that generates periodic scene descriptions (“delivery at door 14:03”), and expose it to Home Assistant. Raspberry Pi explicitly positions AI HAT+ 2 as enabling LLM/VLM workloads with dedicated RAM and Hailo-10H acceleration. [68]
Note on the diagrams above: the fine-tuning timeline, deployment trade-off map, and product strategy loop are schematic summaries grounded in the cited techniques (LoRA/QLoRA; DPO/ORPO/KTO/SimPO; Core ML/MLX; Transformers.js/WebGPU; vLLM/TGI; marketplace-led distribution). [69]
[1] [6] https://github.com/meta-llama/llama-models
https://github.com/meta-llama/llama-models
[2] https://hai.stanford.edu/ai-index/2025-ai-index-report
https://hai.stanford.edu/ai-index/2025-ai-index-report
[3] https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
[4] https://developer.apple.com/app-store/discoverability/
https://developer.apple.com/app-store/discoverability
[5] Attention Is All You Need
https://arxiv.org/abs/1706.03762?utm_source=chatgpt.com
[7] https://huggingface.co/google/gemma-3-4b-it
https://huggingface.co/google/gemma-3-4b-it
[8] https://huggingface.co/Qwen
[9] https://mistral.ai/news/mixtral-of-experts
https://mistral.ai/news/mixtral-of-experts
[10] https://openai.com/index/new-tools-for-building-agents/
https://openai.com/index/new-tools-for-building-agents
[11] https://huggingface.co/docs/transformers/en/chat_extras
https://huggingface.co/docs/transformers/en/chat_extras
[12] [69] LORA: LOW-RANK ADAPTATION OF LARGE LAN
https://openreview.net/pdf?id=nZeVKeeFYf9&utm_source=chatgpt.com
[13] QLORA: Efficient Finetuning of Quantized LLMs
https://arxiv.org/pdf/2305.14314?utm_source=chatgpt.com
[14] Direct Preference Optimization: Your Language Model is …
https://arxiv.org/abs/2305.18290?utm_source=chatgpt.com
[15] ORPO: Monolithic Preference Optimization without Reference Model
https://arxiv.org/abs/2403.07691?utm_source=chatgpt.com
[16] https://huggingface.co/docs/trl/en/index
https://huggingface.co/docs/trl/en/index
[17] https://platform.openai.com/docs/guides/model-optimization
https://platform.openai.com/docs/guides/model-optimization
[18] [35] https://arxiv.org/abs/2005.11401
https://arxiv.org/abs/2005.11401
[19] https://docs.langchain.com/oss/python/langchain/retrieval
https://docs.langchain.com/oss/python/langchain/retrieval
[20] https://developer.apple.com/documentation/coreml
https://developer.apple.com/documentation/coreml
[21] https://developer.apple.com/machine-learning/core-ml/
https://developer.apple.com/machine-learning/core-ml
[22] https://github.com/ggml-org/llama.cpp
https://github.com/ggml-org/llama.cpp
[23] [47] https://huggingface.co/docs/transformers.js/en/index
https://huggingface.co/docs/transformers.js/en/index
[24] Efficient Memory Management for Large Language Model …
https://arxiv.org/abs/2309.06180?utm_source=chatgpt.com
[25] https://huggingface.co/docs/text-generation-inference/en/index
https://huggingface.co/docs/text-generation-inference/en/index
[26] https://docs.nvidia.com/tensorrt-llm/index.html
https://docs.nvidia.com/tensorrt-llm/index.html
[27] [66] https://huggingface.co/docs/inference-endpoints/en/index
https://huggingface.co/docs/inference-endpoints/en/index
[28] https://docs.aws.amazon.com/sagemaker/latest/dg/large-model-inference-container-docs.html
https://docs.aws.amazon.com/sagemaker/latest/dg/large-model-inference-container-docs.html
[29] https://modal.com/blog/how-to-deploy-vllm
https://modal.com/blog/how-to-deploy-vllm
[30] https://openai.com/index/whisper/
https://openai.com/index/whisper
[31] [41] https://goodsnooze.gumroad.com/l/macwhisper
https://goodsnooze.gumroad.com/l/macwhisper
[32] [42] https://apps.apple.com/us/app/whisper-transcription/id1668083311
https://apps.apple.com/us/app/whisper-transcription/id1668083311
[33] [40] https://audiopen.ai/
[34] [43] https://askyourpdf.com/
[36] https://developer.chrome.com/docs/ai/summarizer-api
https://developer.chrome.com/docs/ai/summarizer-api
[37] https://chromewebstore.google.com/detail/briefy-ai-summarizer-with/hhcfeikmmkngnnaogpodbggmcjcebfba
https://chromewebstore.google.com/detail/briefy-ai-summarizer-with/hhcfeikmmkngnnaogpodbggmcjcebfba
[38] https://docs.readwise.io/reader/guides/ghostreader/overview
https://docs.readwise.io/reader/guides/ghostreader/overview
[39] [46] [67] https://www.home-assistant.io/blog/2025/09/11/ai-in-home-assistant/
https://www.home-assistant.io/blog/2025/09/11/ai-in-home-assistant
[44] [52] https://shopify.dev/docs/apps/launch/distribution/revenue-share
https://shopify.dev/docs/apps/launch/distribution/revenue-share
[45] [55] https://developer.chrome.com/docs/webstore/publish
https://developer.chrome.com/docs/webstore/publish
[48] [56] https://developer.apple.com/app-store/small-business-program/
https://developer.apple.com/app-store/small-business-program
[49] https://developer.apple.com/app-store/categories/
https://developer.apple.com/app-store/categories
[50] https://www.reuters.com/legal/litigation/apple-changes-app-store-rules-eu-comply-with-antitrust-order-2025-06-26/
[51] https://developer.apple.com/documentation/AppStoreConnectAPI/marketplace-search-configurations
https://developer.apple.com/documentation/AppStoreConnectAPI/marketplace-search-configurations
[53] https://www.atlassian.com/blog/developer/runs-on-atlassian-apps-can-now-take-home-100-of-marketplace-revenue
[54] https://docs.slack.dev/slack-marketplace/distributing-your-app-in-the-slack-marketplace
https://docs.slack.dev/slack-marketplace/distributing-your-app-in-the-slack-marketplace
[57] https://www.home-assistant.io/voice-pe/
https://www.home-assistant.io/voice-pe
[58] https://docs.ros.org/en/rolling/Tutorials/Beginner-CLI-Tools/Understanding-ROS2-Nodes/Understanding-ROS2-Nodes.html
[59] https://arxiv.org/abs/2204.01691
https://arxiv.org/abs/2204.01691
[60] [68] https://www.raspberrypi.com/news/introducing-the-raspberry-pi-ai-hat-plus-2-generative-ai-on-raspberry-pi-5/
[61] https://arxiv.org/abs/2406.09246
https://arxiv.org/abs/2406.09246
[62] https://arxiv.org/abs/2405.12213
https://arxiv.org/abs/2405.12213
[63] https://developer.apple.com/metal/pytorch/
https://developer.apple.com/metal/pytorch
[64] https://pytorch.org/get-started/locally/
https://pytorch.org/get-started/locally
[65] https://www.raspberrypi.com/products/ai-hat-plus-2/