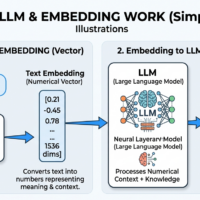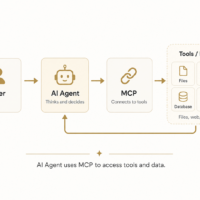
Where to Get Data for Machine Learning and Deep Learning Model Creation
1. Primary Data Sources for Machine Learning and Deep Learning
| Source | Description |
|---|---|
| Kaggle | A community-driven platform offering a variety of datasets, including image, text, and structured data. |
| UCI Machine Learning Repository | A longstanding repository with datasets suitable for traditional machine learning models. |
| Hugging Face Datasets | Offers numerous text datasets specifically for NLP projects, accessible via Hugging Face API. |
| Google Dataset Search | A search engine for freely available datasets, including government and scientific data. |
| GitHub | Hosts open datasets as part of machine learning projects, often accompanied by sample code. |
2. Data Collection Techniques for Custom and Specialized Models
| Technique | Description |
|---|---|
| Web Scraping | Useful for creating custom datasets by extracting data from online sources; tools like BeautifulSoup and Scrapy can help. |
| Synthetic Data Generation | Creates artificial data that mimics real-world scenarios; ideal when data privacy is a concern. |
| APIs | APIs from Twitter, OpenWeatherMap, etc., offer easy access to real-time, structured data directly from the source. |
| Crowdsourcing and Labeling | Platforms like Amazon Mechanical Turk enable outsourcing of data collection and labeling. |
| Simulated Environments | Used for reinforcement learning tasks; includes platforms like OpenAI Gym and Unity ML-Agents. |
3. Data Types by Model Requirements
| Model Type | Data Requirement | Source Examples |
|---|---|---|
| Supervised Learning | Labeled data | Kaggle, ImageNet, COCO |
| Unsupervised Learning | Unlabeled data | Open Images, Wikipedia dumps |
| Reinforcement Learning | Simulated environments | OpenAI Gym, Unity ML-Agents Toolkit |
| Semi-Supervised Learning | Partial labels | Common Crawl, Open Images |
| Time Series Models | Sequential data | Yahoo Finance, NOAA |
4. How Data is Categorized on the Internet
| Category Type | Description |
|---|---|
| Taxonomies | Hierarchical structures that organize data into nested categories. |
| Folksonomies | User-generated tags that provide a non-hierarchical, flexible categorization. |
| Ontologies | Frameworks defining relationships between concepts, often used in AI. |
| Metadata Schemas | Standardized elements used to describe datasets, like Dublin Core for digital resources. |
| Controlled Vocabularies | Predefined terms ensuring consistent data categorization, used in specialized fields. |
5. Best Practices for Data Collection and Usage
| Practice | Description |
|---|---|
| Compliance with Licensing | Check dataset licenses for any restrictions on usage, modification, or redistribution. |
| Data Augmentation | Increase data variety by applying transformations, like rotating or flipping images. |
| Combining Datasets | Merge multiple compatible datasets to enhance model performance and coverage. |
| Data Labeling and Annotation | For supervised learning, quality labeled data is essential; crowdsourcing is an option. |
| Privacy and Ethics | Obtain user consent and anonymize data, especially in sensitive fields like healthcare. |
Creating a Simple Deep Learning Model for Voice Tone Change Using PyTorch
Step 1: Collecting and Preprocessing Audio Data
For this example, we use voice recordings from datasets like LibriSpeech or Mozilla’s Common Voice. After downloading the audio data, we convert it to spectrograms using Librosa, making it suitable for our CNN model.
import librosa import torch import numpy as np # Load an audio sample audio_path = 'path_to_audio_file.wav' audio_data, sample_rate = librosa.load(audio_path, sr=16000) # Convert to a Mel-spectrogram spectrogram = librosa.feature.melspectrogram(y=audio_data, sr=sample_rate, n_mels=128) log_spectrogram = librosa.power_to_db(spectrogram, ref=np.max) # Convert to torch tensor for model input input_data = torch.tensor(log_spectrogram, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
Step 2: Building a Simple CNN for Voice Tone Change
We use a simple Convolutional Neural Network (CNN) model to process spectrograms. The model adjusts audio properties based on patterns in pitch and frequency.
import torch.nn as nn
class SimpleToneChangeModel(nn.Module):
def __init__(self):
super(SimpleToneChangeModel, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(32 * 128 * 128, 128)
self.fc2 = nn.Linear(128, 128)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = x.view(x.size(0), -1)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Instantiate the model
model = SimpleToneChangeModel()
Step 3: Training the Model
For training, we define a loss function and optimizer. The model learns by comparing original and pitch-shifted spectrograms, adjusting its weights to alter audio pitch effectively.
import torch.optim as optim
# Define loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Example dataset class for audio spectrograms
class AudioDataset(torch.utils.data.Dataset):
def __init__(self, audio_data_list):
self.audio_data_list = audio_data_list
def __len__(self):
return len(self.audio_data_list)
def __getitem__(self, idx):
original_spectrogram = self.audio_data_list[idx]
pitch_shifted_audio = librosa.effects.pitch_shift(original_spectrogram, sr=16000, n_steps=2)
target_spectrogram = librosa.feature.melspectrogram(y=pitch_shifted_audio, sr=16000, n_mels=128)
return torch.tensor(original_spectrogram, dtype=torch.float32), torch.tensor(target_spectrogram, dtype=torch.float32)
# DataLoader setup
audio_data = [input_data]
audio_dataset = AudioDataset(audio_data)
data_loader = torch.utils.data.DataLoader(audio_dataset, batch_size=1, shuffle=True)
# Training loop
for epoch in range(10):
for inputs, targets in data_loader:
inputs = inputs.unsqueeze(1)
targets = targets.unsqueeze(1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
Step 4: Testing the Model
After training, we use the model to alter the tone of a new audio sample, creating a pitch-shifted version of the input audio.
with torch.no_grad():
test_audio, _ = librosa.load('test_audio.wav', sr=16000)
test_spectrogram = librosa.feature.melspectrogram(y=test_audio, sr=16000, n_mels=128)
test_input = torch.tensor(test_spectrogram, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
output_spectrogram = model(test_input).squeeze().numpy()
output_audio = librosa.feature.inverse.mel_to_audio(output_spectrogram)
# Save or play the modified audio
librosa.output.write_wav('output_audio.wav', output_audio, sr=16000)
Summary
In this example, we covered data gathering, model selection, training, and testing to create a simple tone-changing model. This basic CNN model can be expanded for more sophisticated audio processing tasks by increasing its complexity or adding recurrent layers.