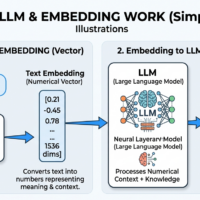
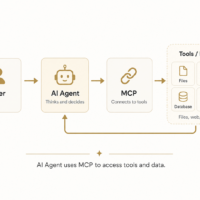
ingoampt November 4, 2024 Machine Learning Overview DeepNet – What Happens by Scaling Transformers to 1,000 Layers ? – Day 79 Photo by Matheus Bertelli on <a href="https://www.pexels.com/photo/man-using-smartphone-with-chat-gpt-16094064/" rel="nofollow">Pexels.com</a> Subscribe to continue reading Subscribe to get access to the rest of this post and other subscriber-only content. Type your email… Subscribe Already a subscriber?