Reinforcement Learning: An Evolution from Games to Real-World Impact
Reinforcement Learning (RL) is a fascinating branch of machine learning, with its roots stretching back to the 1950s. Although not always in the limelight, RL made a significant impact in various domains, especially in gaming and machine control. In 2013, a team from DeepMind, a British startup, built a system capable of learning and excelling at Atari games using only raw pixels as input—without any knowledge of the game’s rules. This breakthrough led to DeepMind’s famous system, AlphaGo, defeating world Go champions and ignited a global interest in RL.
The Foundations of Reinforcement Learning: How It Works
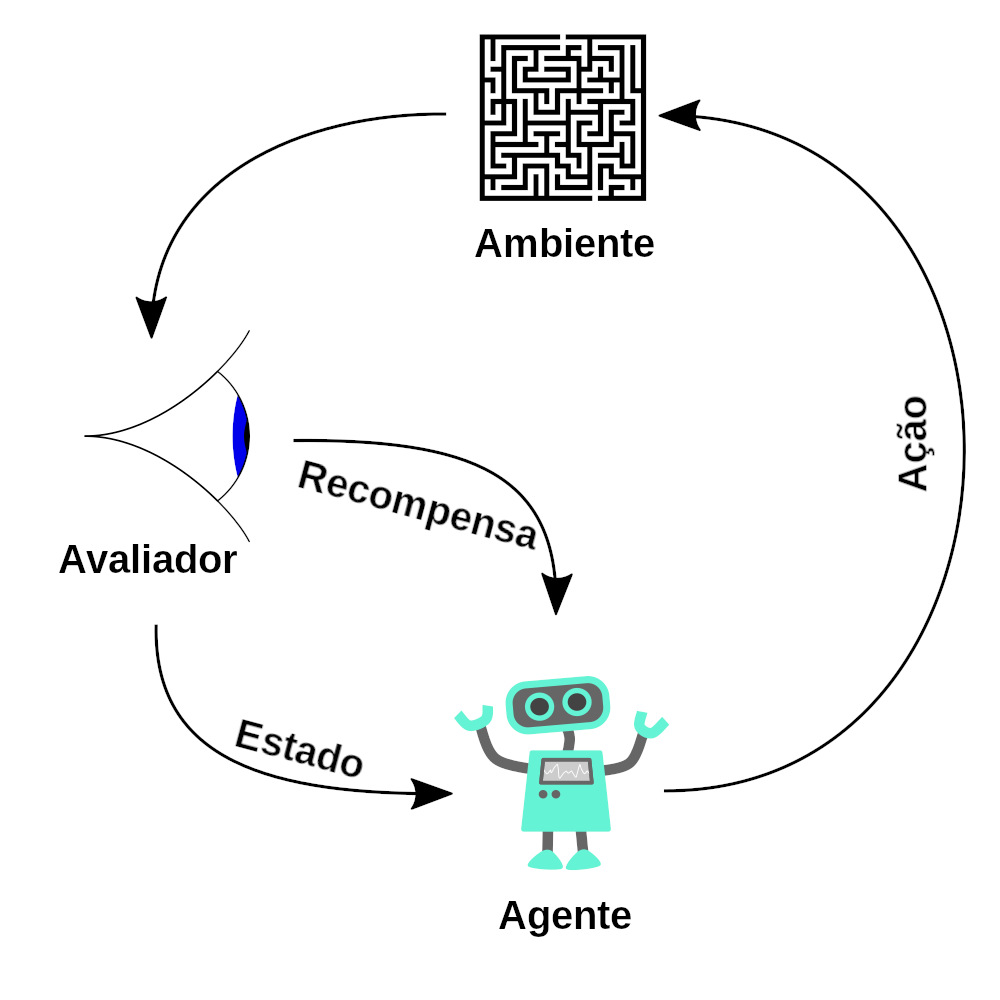
In RL, an agent interacts with an environment, observes outcomes, and receives feedback through rewards. The agent’s objective is to maximize cumulative rewards over time, learning the best actions through trial and error.
| Term | Explanation |
|---|---|
| Agent | The software or system making decisions. |
| Environment | The external setting with which the agent interacts. |
| Reward | Feedback from the environment based on the agent’s actions. |
Examples of RL Applications
Here are a few tasks RL is well-suited for:
| Application | Agent | Environment | Reward |
|---|---|---|---|
| Robot Control | Robot control program | Real-world physical space | Positive for approaching target, negative for incorrect movement |
| Atari Game | Game-playing program | Game simulation | Points scored in the game |
| Board Game (e.g., Go) | Game-playing program | Game board | Reward only if it wins the game |
| Smart Thermostat | Thermostat control program | Indoor temperature settings | Positive for saving energy, negative if adjustments are needed by humans |
| Stock Market | Trading agent | Financial market data | Monetary gains and losses |
Defining Policy: The Agent’s Guide to Action
The approach or “policy” an agent uses to decide its actions is central to RL. A policy can be as straightforward as a set of if-then rules or as complex as a deep neural network that analyzes observations to output actions. Policies can be deterministic or stochastic (random). In training an agent, policy search methods help identify effective policies, often through trial and error.
Policy Search and Optimization Techniques
| Method | Description |
|---|---|
| Brute-Force Search | Tries various policy parameters systematically, though it’s not feasible for complex policies. |
| Genetic Algorithms | Generates multiple policies, selects the best, and iterates through generations with random mutations. |
| Policy Gradients (PG) | Adjusts policy parameters by evaluating gradients based on rewards to optimize actions. |
Getting Started with OpenAI Gym
Training RL agents requires environments where the agent can safely learn and test its policies. OpenAI Gym is a popular toolkit that offers simulated environments for RL training, from Atari games to physical simulations. By using OpenAI Gym, developers can safely experiment and refine RL agents without needing a physical setup.
Setting Up OpenAI Gym
To install and use OpenAI Gym on Colab or a local machine, developers can use the following commands:
# Upgrade Gym and install dependencies on Colab
%pip install -q -U gym
%pip install -q -U gym[classic_control,box2d,atari,accept-rom-license]
These commands install Gym and essential libraries for running classic and Atari environments.
Creating a CartPole Environment
In this 2D environment, a cart must balance a pole by deciding when to move left or right:
import gym
env = gym.make("CartPole-v1", render_mode="rgb_array")
obs, info = env.reset(seed=42)
print(obs) # Initial observationHere, obs is a 1D array representing the cart’s position and velocity, as well as the pole’s angle and angular velocity.
| Observation | Description |
|---|---|
| Horizontal Position | Cart’s position relative to the center (0.0 = center). |
| Velocity | Speed and direction of the cart. |
| Angle | Pole’s tilt relative to vertical (0.0 = perfectly vertical). |
| Angular Velocity | Speed and direction of the pole’s tilt. |
Implementing a Simple Policy for CartPole
This policy directs the cart to move left or right based on the pole’s tilt angle:
def basic_policy(obs):
angle = obs[2]
return 0 if angle < 0 else 1The policy adjusts based on the observation, keeping the pole balanced for as long as possible. After running multiple trials, we can evaluate its performance:
totals = []
for episode in range(500):
episode_rewards = 0
obs, info = env.reset(seed=episode)
for step in range(200):
action = basic_policy(obs)
obs, reward, done, truncated, info = env.step(action)
episode_rewards += reward
if done or truncated:
break
totals.append(episode_rewards)The results, such as the mean and standard deviation of rewards, indicate how well this simple policy performs.
The RL Loop
At the core of RL is the interaction between the agent and the environment.
+---------+ Action +-------------+
| | ---------------> | |
| Agent | | Environment |
| | <--------------- | |
+---------+ Observation +-------------+
(State, Reward)
Figure 1: The Agent-Environment Interaction Loop
- Agent: Learns and decides which action to take.
- Environment: Responds to the agent's actions and provides feedback.
Markov Decision Processes (MDPs)
An MDP provides a mathematical framework for modeling RL problems.
Components of an MDP
- States (S): All possible situations the agent can be in.
- Actions (A): All possible moves the agent can make.
- Transition Probability (P): Probability of moving from one state to another given an action.
- Reward Function (R): Feedback received after taking an action.
- Discount Factor (γ): Determines the importance of future rewards.
Value Functions and the Bellman Equations
Value functions estimate how good it is to be in a state or to perform an action in a state.
State-Value Function Vπ(s)
![V^{\pi}(s) = \mathbb{E}_{\pi} \left[ \sum_{t=0}^{\infty} \gamma^t r_{t+1} \,|\, s_0 = s \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-380e7029e82e22b03986feee03d3109c_l3.png "Rendered by QuickLaTeX.com")
 : Value of state
: Value of state  under policy
under policy  .
.
![\mathbb{E}_{\pi} [ \cdot ]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-26ea52ae733ec26ad98e5815793ea9db_l3.png "Rendered by QuickLaTeX.com") : Expected value when following policy .
: Expected value when following policy .
 : Sum over all future time steps.
: Sum over all future time steps.
 : Discount factor raised to the power
: Discount factor raised to the power  (0 ≤
(0 ≤  ≤ 1).
≤ 1).
 : Reward at time
: Reward at time  .
.
 : Starting from state at time
: Starting from state at time  .
.
Action-Value Function 
![Q^{\pi}(s, a) = \mathbb{E}_{\pi} \left[ \sum_{t=0}^{\infty} \gamma^t r_{t+1} \,|\, s_0 = s, a_0 = a \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-6ebc3ad2959e555e9fde4b50174bde53_l3.png "Rendered by QuickLaTeX.com")
: Value of taking action  in state under policy .
in state under policy .
 : Taking action at the initial time.
: Taking action at the initial time.
Other terms are as previously defined.
The Bellman Expectation Equation
For the state-value function:
![V^{\pi}(s) = \sum_{a \in A} \pi(a | s) \sum_{s' \in S} P(s' | s, a) \left[ R(s, a) + \gamma V^{\pi}(s') \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-f0ad393cc7498830c3276473da074d10_l3.png "Rendered by QuickLaTeX.com")
: Value of state under policy .
 : Probability of taking action in state under policy .
: Probability of taking action in state under policy .
 : Probability of transitioning to state
: Probability of transitioning to state  from after action .
from after action .
 : Immediate reward after action in state .
: Immediate reward after action in state .
 : Value of the next state .
: Value of the next state .
Q-Learning and Temporal Difference Learning
Q-Learning is a model-free RL algorithm that seeks to learn the optimal policy.
Q-Learning Update Rule
![Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-5f0f3461a06bb6228b3878e78cac61ee_l3.png "Rendered by QuickLaTeX.com")
 : Current estimate of the Q-value for state
: Current estimate of the Q-value for state  and action
and action  .
.
 : Update operation; assigns the new value to .
: Update operation; assigns the new value to .
 : Learning rate (
: Learning rate ( ).
).
: Reward received after taking action .
: Discount factor.
 : Maximum estimated Q-value for the next state
: Maximum estimated Q-value for the next state  over all possible actions
over all possible actions  .
.
: Current Q-value before the update.
Q-Learning Variables
| Symbol | Description |
|---|---|
|
Current state |
|
Action taken at state |
|
Reward received after action |
|
Next state after action |
|
Learning rate |
|
Discount factor |
|
Current Q-value estimate |
Function Approximation with Neural Networks
When dealing with large or continuous state spaces, we use neural networks to approximate the Q-function.
Neural Network Approximation
[Input Layer]: State s_t
|
[Hidden Layers]
|
[Output Layer]: Q-values for all actions
Figure 2: Neural Network Approximation
- Input: State representation.
- Output: Estimated Q-values for possible actions.
Deep Q-Networks (DQN)
DQN combines Q-Learning with deep neural networks.
Key Components of DQN
- Experience Replay: Stores agent's experiences and samples mini-batches to break correlation.
- Target Network: A separate network to calculate target Q-values, improving stability.
DQN Loss Function
![L(\theta) = \mathbb{E}_{(s, a, r, s')} \left[ \left( y - Q(s, a; \theta) \right)^2 \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-498262ec4eda9f26344c13854a8eb5b8_l3.png "Rendered by QuickLaTeX.com")
 : Loss function to minimize during training.
: Loss function to minimize during training.
![\mathbb{E}_{(s, a, r, s')} \left[ \cdot \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-bd8e32635a008b865c59bf1c72a50fc9_l3.png "Rendered by QuickLaTeX.com") : Expected value over the experience replay buffer containing tuples
: Expected value over the experience replay buffer containing tuples  .
.
 : Target Q-value.
: Target Q-value.
 : Predicted Q-value from the network for state and action , parameterized by
: Predicted Q-value from the network for state and action , parameterized by  .
.
Where the target Q-value is:

: Target Q-value.
 : Reward received after taking action in state .
: Reward received after taking action in state .
: Discount factor.
 : Maximum predicted Q-value for the next state over all actions , using the target network parameters
: Maximum predicted Q-value for the next state over all actions , using the target network parameters  .
.
: Parameters of the target network (a delayed copy of ).
Policy Gradient Methods
Policy Gradient methods optimize the policy directly.
Policy Representation
 : Probability of taking action in state , parameterized by .
: Probability of taking action in state , parameterized by .
Objective Function
![J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \sum_{t=0}^{\infty} \gamma^t \, r_{t+1} \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-72f9150e1043076d070dd0c7b6271fa7_l3.png "Rendered by QuickLaTeX.com")
 : Performance measure of the policy.
: Performance measure of the policy.
![\mathbb{E}_{\pi_{\theta}} \left[ \cdot \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-1cde1a6f027c8a094468abc3a6266521_l3.png "Rendered by QuickLaTeX.com") : Expected reward under the policy
: Expected reward under the policy  .
.
: Discount factor raised to the power .
: Reward received at time .
Actor-Critic Algorithms
Actor-Critic algorithms combine policy-based and value-based methods to improve stability and efficiency.
Actor Update

 : Parameters of the actor (policy) network.
: Parameters of the actor (policy) network.
 : Learning rate for the actor network.
: Learning rate for the actor network.
 : Temporal Difference (TD) error calculated as:
: Temporal Difference (TD) error calculated as:

 : Gradient of the log-probability of the action taken with respect to the actor’s parameters.
: Gradient of the log-probability of the action taken with respect to the actor’s parameters.
Critic Update

 : Parameters of the critic (value function) network.
: Parameters of the critic (value function) network.
 : Learning rate for the critic network.
: Learning rate for the critic network.
: Temporal Difference error (as calculated above).
 : Gradient of the value function estimate with respect to the critic's parameters.
: Gradient of the value function estimate with respect to the critic's parameters.
Advanced Techniques in Deep RL
Recent advances in RL leverage complex algorithms and architectures to improve performance in challenging environments.
Proximal Policy Optimization (PPO)
PPO improves training stability by limiting the extent to which policy updates can deviate. It applies a clipping function to the policy loss, constraining how much the updated policy can differ from the old policy.
Soft Actor-Critic (SAC)
SAC introduces an entropy term into the reward function, encouraging exploration by making the agent seek stochastic policies. The objective is to maximize both the reward and the policy’s entropy.
Applications of RL with Neural Networks
Gaming
- AlphaGo: Used RL to achieve superhuman performance in the game of Go by combining deep neural networks with Monte Carlo tree search.
- Atari Games: Achieved human-level performance on many Atari games using DQN, which learns directly from raw pixel inputs.
Robotics
- Manipulation: RL helps robots learn to pick and manipulate objects with precision.
- Locomotion: Agents use RL to learn movement patterns for walking, running, and navigating through obstacles.
Autonomous Vehicles
- Navigation: RL helps autonomous vehicles make real-time decisions in complex, dynamic environments.
Conclusion
Reinforcement learning, especially when combined with neural networks, has transformed the field of AI, enabling machines to tackle complex tasks across multiple domains. Understanding the mathematical foundations and practical applications of RL helps us appreciate its potential and limitations as we continue to explore its capabilities in the real world.
| Step | Concept | Details | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Markov Decision Processes (MDP) |
An MDP provides a mathematical framework for modeling decision-making where outcomes are partly random and partly under the control of a decision-maker.
Markov Property: The future state depends only on the current state and action, not on the sequence of events that preceded it. |
||||||||||||
| 2 | Value Functions |
Value functions estimate how good it is to be in a given state or to perform a specific action in a state, in terms of expected return (cumulative future rewards).
Explanation: The expectation |
||||||||||||
| 3 | Bellman Equations |
The Bellman equations provide recursive definitions for the value functions, expressing the value of a state (or state-action pair) in terms of the immediate reward and the value of successor states.
|
||||||||||||
| 4 | Optimal Value Functions and Policies |
Optimal value functions represent the maximum expected return achievable from any state or state-action pair, under any policy.
The Bellman Optimality Equations define these optimal value functions recursively:
|
||||||||||||
| 5 | Policies |
A policy
Policy Improvement: The process of improving a policy by making it greedy with respect to the current value function. |
||||||||||||
| 6 | Temporal Difference (TD) Learning |
TD learning methods update estimates based on a combination of observed rewards and existing estimates.
|
||||||||||||
| 7 | Q-Learning |
Q-Learning is an off-policy TD control algorithm that aims to learn the optimal action-value function
Explanation: The update rule adjusts the current Q-value towards the target, which is the immediate reward plus the discounted estimate of the optimal future Q-value. |
||||||||||||
| 8 | Function Approximation & Neural Networks |
In environments with large or continuous state spaces, it's impractical to maintain a table of Q-values. Function approximation methods, like neural networks, are used to estimate value functions.
Explanation: Here, |
||||||||||||
| 9 | Deep Q-Networks (DQN) |
DQN combines Q-learning with deep neural networks to handle high-dimensional state spaces.
Explanation: The loss function quantifies how close the neural network's predictions are to the targets. The target network |
||||||||||||
| 10 | Policy Gradient Methods |
Policy gradient methods optimize the policy directly by adjusting its parameters to maximize expected return.
Explanation: By taking steps proportional to the policy gradient, we improve the policy to maximize expected rewards. |
||||||||||||
| 11 | REINFORCE Algorithm |
REINFORCE is a Monte Carlo policy gradient method that updates the policy based on complete episodes.
Explanation:
|
||||||||||||
| 12 | Actor-Critic Methods |
Actor-Critic methods combine the benefits of policy gradients and value function approximation.
Explanation: The critic evaluates the current policy by estimating the value function, while the actor updates the policy parameters in a direction that improves performance according to the critic's feedback. |
||||||||||||
| 13 | Mathematics Behind Neural Network Updates |
Neural networks are trained by adjusting their parameters to minimize a loss function using gradient descent.
Explanation:
|
||||||||||||
| 14 | Example: DQN Update Step |
Steps to update DQN parameters:
Explanation:
|
||||||||||||
| 15 | Exploration vs. Exploitation |
Balancing the need to explore new actions to discover their value and exploiting known actions to maximize reward.
|
||||||||||||
| 16 | Advanced Techniques |
Enhancements to basic algorithms to improve performance and stability.
|
||||||||||||
| 17 | Summary |
Reinforcement learning enables agents to learn optimal behaviors through interactions with an environment by maximizing cumulative rewards. The mathematical foundations, including MDPs, value functions, and Bellman equations, provide a framework for understanding and developing RL algorithms. Neural networks serve as powerful function approximators, especially in complex, high-dimensional environments, making advanced algorithms like DQN and policy gradient methods feasible. |



 , which determines the importance of future rewards
, which determines the importance of future rewards
![V^\pi(s) = \mathbb{E}_\pi \left[ \sum_{t=0}^\infty \gamma^t R(s_t, a_t) \,\bigg|\, s_0 = s \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-e2e313bb5a1e7cffdf6d75f7d3407562_l3.png "Rendered by QuickLaTeX.com")

![Q^\pi(s, a) = \mathbb{E}_\pi \left[ \sum_{t=0}^\infty \gamma^t R(s_t, a_t) \,\bigg|\, s_0 = s, a_0 = a \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-884b17546e73e78e353c6fa4e249d4b9_l3.png "Rendered by QuickLaTeX.com")
 is taken over all possible sequences of future states and actions, weighted by the probability of their occurrence under policy
is taken over all possible sequences of future states and actions, weighted by the probability of their occurrence under policy ![V^\pi(s) = \sum_{a} \pi(a|s) \left[ R(s, a) + \gamma \sum_{s'} P(s'|s, a) V^\pi(s') \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-9bc0cc696ef1278c963a73004435da02_l3.png "Rendered by QuickLaTeX.com")
 , averaged over all possible actions
, averaged over all possible actions 




![V^*(s) = \max_{a} \left[ R(s, a) + \gamma \sum_{s'} P(s'|s, a) V^*(s') \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-1d0ef0760ce44336f013bf81e627523c_l3.png "Rendered by QuickLaTeX.com")


![\pi(a|s) = \mathbb{P}[A_t = a \,|\, S_t = s]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-865067516bd4a90e254642f16faee799_l3.png "Rendered by QuickLaTeX.com")

 : Reward received after taking action at time
: Reward received after taking action at time  : Discounted estimate of future value.
: Discounted estimate of future value. : Current estimate of the value of state
: Current estimate of the value of state  .
.

![Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha \left[ R_{t+1} + \gamma \max_{a'} Q(S_{t+1}, a') - Q(S_t, A_t) \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-8d621289e325c31f2020fd024b0dbd23_l3.png "Rendered by QuickLaTeX.com")
 using the reward
using the reward  : Estimated optimal future value.
: Estimated optimal future value.

![L(\theta) = \mathbb{E}_{s,a,r,s'} \left[ \left( y - Q(s, a; \theta) \right)^2 \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-d4874ef27343c35c331b7abbe953e381_l3.png "Rendered by QuickLaTeX.com")
 : Estimated optimal future value using the target network parameters
: Estimated optimal future value using the target network parameters ![J(\theta) = \mathbb{E}_\pi [ R ]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-01acbb99006ef5cb54c8df5983b71fb3_l3.png "Rendered by QuickLaTeX.com")
![\nabla_\theta J(\theta) = \mathbb{E}_\pi \left[ \nabla_\theta \log \pi_\theta(a|s) Q^\pi(s, a) \right]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-e4682a736db005cc66fa6d99249a7ba6_l3.png "Rendered by QuickLaTeX.com")
 : Gradient of the log-probability of action
: Gradient of the log-probability of action 

 is the return from time
is the return from time 
 : Estimated value of state
: Estimated value of state  .
.

 : Critic's learning rate.
: Critic's learning rate.

 : Actor's learning rate.
: Actor's learning rate.

 : Gradient of the loss with respect to the parameters, computed using backpropagation.
: Gradient of the loss with respect to the parameters, computed using backpropagation. from the replay buffer.
from the replay buffer.



 is computed using the target network parameters
is computed using the target network parameters  -Greedy Policy
-Greedy Policy , select the action with the highest estimated Q-value (exploitation).
, select the action with the highest estimated Q-value (exploitation).


