Momentum Optimization in Machine Learning: A Detailed Mathematical Analysis and Practical Application
Momentum optimization is a key enhancement to the gradient descent algorithm, widely used in machine learning for faster and more stable convergence. This guide will explore the mathematical underpinnings of gradient descent and momentum optimization, provide proofs of their convergence properties, and demonstrate how momentum can accelerate the optimization process through a practical example.
1. Gradient Descent: Mathematical Foundations and Proof of Convergence
1.1 Basic Gradient Descent
Gradient Descent is an iterative algorithm used to minimize a cost function  . It updates the parameters
. It updates the parameters  in the direction of the negative gradient of the cost function. The update rule for gradient descent is:
in the direction of the negative gradient of the cost function. The update rule for gradient descent is:

Where:
 is the parameter vector at iteration
is the parameter vector at iteration  .
. is the learning rate.
is the learning rate. is the gradient of the cost function with respect to .
is the gradient of the cost function with respect to .
1.2 Mathematical Proof Without Momentum
Let’s consider a quadratic cost function, which is common in many machine learning problems:

Where  is a positive-definite matrix and
is a positive-definite matrix and  is a vector.
is a vector.
The gradient of this cost function is:

Using the gradient descent update rule:

Rearranging:

For convergence, we require the eigenvalues of  to be less than 1 in magnitude, which leads to the condition:
to be less than 1 in magnitude, which leads to the condition:
![0 Where [latex]\lambda_{\max}](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-105d37e800ebdb121ec987273d6a1323_l3.png "Rendered by QuickLaTeX.com") is the largest eigenvalue of . This condition ensures that gradient descent converges to the global minimum.
is the largest eigenvalue of . This condition ensures that gradient descent converges to the global minimum.
However, this convergence can be slow, especially when the condition number  is large, leading to slow progress in directions corresponding to small eigenvalues.
is large, leading to slow progress in directions corresponding to small eigenvalues.
1.3 Practical Example Without Momentum
Let’s consider the specific quadratic function:

Here,  and
and  . The gradient is simply
. The gradient is simply  , and the update rule becomes:
, and the update rule becomes:

For  and initial value
and initial value  :
:



This process shows a slow and steady convergence towards the minimum at  , with each step reducing by a factor of 0.9.
, with each step reducing by a factor of 0.9.
2. Momentum Optimization: Mathematical Foundations and Proof of Convergence
2.1 Momentum-Based Gradient Descent
Momentum improves upon gradient descent by introducing a velocity term  that incorporates both the current gradient and the previous velocity. This leads to faster convergence and reduced oscillations.
that incorporates both the current gradient and the previous velocity. This leads to faster convergence and reduced oscillations.
The update rules for momentum-based gradient descent are:
- Velocity Update:
 Where
Where  is the momentum coefficient.
is the momentum coefficient. - Parameter Update:

2.2 Mathematical Proof With Momentum
Using the same quadratic cost function :
- Velocity Update:

- Parameter Update:
 Expanding the recursion:
Expanding the recursion: Simplifying:
Simplifying:
This equation reveals that momentum introduces a second-order term, effectively accelerating the optimization in directions where the gradient is consistent and damping oscillations in directions where the gradient changes rapidly.
2.3 Numerical Example With Momentum
Let’s use the same quadratic function with ,  , and ,
, and ,  :
:
- Iteration 1:

- Iteration 2:

- Iteration 3:

Comparing this with standard gradient descent:
- Without Momentum: decreases steadily but slowly.
- With Momentum: decreases more rapidly due to the accumulated effect of past gradients, showing faster convergence.
3. Practical Application of Momentum in Machine Learning
Momentum is widely used in training machine learning models, particularly in neural networks where the cost function may have flat regions and steep valleys. Below is a practical example of applying momentum to a simple linear regression problem:
import numpy as np
def gradient_descent_momentum(X, y, learning_rate=0.01, momentum=0.9, num_iterations=100):
num_samples, num_features = X.shape
theta = np.zeros(num_features)
velocity = np.zeros_like(theta)
for iteration in range(num_iterations):
predictions = np.dot(X, theta)
errors = predictions - y
gradients = (1/num_samples) * np.dot(X.T, errors)
velocity = momentum * velocity + learning_rate * gradients
theta -= velocity
mse = np.mean(errors**2)
print(f"Iteration {iteration+1}, MSE: {mse}")
return theta
# Example Usage:
np.random.seed(42)
X = np.random.rand(100, 1)
y = 2 + 3 * X + np.random.randn(100, 1)
theta_momentum = gradient_descent_momentum(X, y, learning_rate=0.1, momentum=0.9, num_iterations=100)
Explanation:
- Data Preparation: Synthetic data is generated for a simple linear regression task.
- Momentum-Based Gradient Descent: The function `gradient_descent_momentum` is used to optimize the model parameters.
- Comparison: The use of momentum accelerates the convergence, particularly when compared to standard gradient descent. This is because momentum smooths the updates and speeds up the optimization process in flat regions or areas with consistent gradient directions.
Momentum optimization is a powerful enhancement to the gradient descent algorithm. The mathematical analysis demonstrates that momentum can significantly accelerate convergence by adding a velocity component that incorporates the history of gradients. This not only speeds up progress in directions of consistent gradients but also reduces oscillations, leading to smoother and more efficient optimization. The practical example below illustrates how momentum can be effectively applied in real-world machine learning tasks, offering faster and more stable convergence than standard gradient descent:
Momentum Optimization: Practical Example and Visualization
To better understand the impact of momentum on gradient descent, let’s explore a practical example with visualization. This example demonstrates how momentum affects the optimization path compared to standard gradient descent by visualizing the trajectory in a two-dimensional cost function space.
import numpy as np
import matplotlib.pyplot as plt
# Define a cost function with a narrow valley
def cost_function(x, y):
return 0.5 * x**2 + 2 * y**2
# Gradient of the cost function
def gradient(x, y):
return np.array([x, 4 * y])
# Parameters for gradient descent
learning_rate = 0.05 # Lowered learning rate
momentum = 0.5 # Lowered momentum coefficient
num_iterations = 50
# Initial position
x, y = -3.0, 2.0
# Track positions for visualization
positions_no_momentum = []
positions_with_momentum = []
# Gradient Descent without Momentum
for _ in range(num_iterations):
dx, dy = gradient(x, y)
x -= learning_rate * dx
y -= learning_rate * dy
positions_no_momentum.append((x, y))
# Reset initial position for momentum-based gradient descent
x, y = -3.0, 2.0
vx, vy = 0, 0 # Velocity components
# Gradient Descent with Momentum
for _ in range(num_iterations):
dx, dy = gradient(x, y)
vx = momentum * vx + learning_rate * dx
vy = momentum * vy + learning_rate * dy
x -= vx
y -= vy
positions_with_momentum.append((x, y))
# Convert to numpy arrays for plotting
positions_no_momentum = np.array(positions_no_momentum)
positions_with_momentum = np.array(positions_with_momentum)
# Plot the paths
plt.figure(figsize=(10, 5))
plt.plot(positions_no_momentum[:, 0], positions_no_momentum[:, 1], 'r-o', label='Without Momentum')
plt.plot(positions_with_momentum[:, 0], positions_with_momentum[:, 1], 'b-o', label='With Momentum')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.title('Optimization Path Comparison')
plt.show()
Explanation:
- Cost Function: The function
 is chosen to create a narrow valley in the cost landscape. This setup helps illustrate the effect of momentum on the optimization trajectory, as the gradient in the
is chosen to create a narrow valley in the cost landscape. This setup helps illustrate the effect of momentum on the optimization trajectory, as the gradient in the  direction is much smaller than in the
direction is much smaller than in the  direction.
direction. - Gradient Descent Without Momentum: The red line in the plot represents the path taken by standard gradient descent. Since it follows the steepest descent at each step without considering the previous step, it takes a more direct but slower path to the minimum. This is evident in scenarios where the function has a narrow valley, as the optimizer moves slowly in the shallow direction.
- Gradient Descent With Momentum: The blue line in the plot shows the path taken by gradient descent with momentum. Momentum allows the optimizer to build speed in the consistent gradient direction, moving faster along the shallow direction while smoothing oscillations in the steep direction. The result is a more efficient path towards the minimum, demonstrating the benefits of momentum in accelerating convergence.
- Visualization: The plot compares the optimization paths, showing how momentum affects the trajectory. The red path is steadier but slower, while the blue path with momentum is faster and more direct, highlighting the effectiveness of momentum in optimizing complex cost functions.
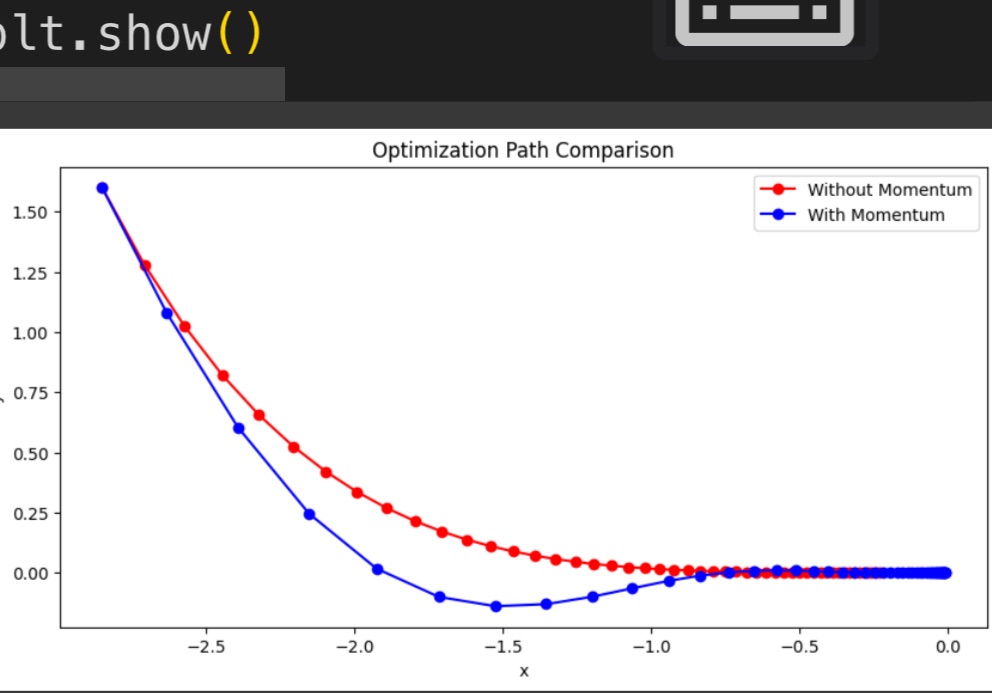
Here is the image which show from the Python given code to show the difference between having and not having momentum as explained
Conclusion
This example demonstrates the practical impact of momentum on the gradient descent algorithm. By visualizing the optimization paths, it becomes clear that momentum not only accelerates convergence but also reduces oscillations, particularly in functions with narrow valleys or steep regions. The practical benefits of momentum make it an essential component in modern optimization techniques, particularly in training deep neural networks.
Note :