Demystifying Trainable and Non-Trainable Parameters in Batch Normalization
Batch normalization (BN) is a powerful technique used in deep learning to stabilize and accelerate training. The core idea behind BN is to normalize the output of a previous layer by subtracting the batch mean and dividing by the batch standard deviation. This is expressed by the following general formula:
\[
\hat{x} = \frac{x – \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}
\]
\[
y = \gamma \hat{x} + \beta
\]
Where:
- \( x \) is the input to the batch normalization layer.
- \( \mu_B \) and \( \sigma_B^2 \) are the mean and variance of the current mini-batch, respectively.
- \( \epsilon \) is a small constant added to avoid division by zero.
- \( \hat{x} \) is the normalized output.
- \( \gamma \) and \( \beta \) are learnable parameters that scale and shift the normalized output.
Why This Formula is Helpful
The normalization step ensures that the input to each layer has a consistent distribution, which addresses the problem of “internal covariate shift”—where the distribution of inputs to a layer changes during training. By maintaining a stable distribution, the training process becomes more efficient, requiring less careful initialization of parameters and allowing for higher learning rates.
The addition of \( \gamma \) and \( \beta \) parameters allows the model to restore the capacity of the network to represent the original data distribution. This means that the model can learn any representation it could without normalization, but with the added benefits of stabilized and accelerated training. The use of batch normalization has been shown empirically to result in faster convergence and improved model performance, particularly in deeper networks.
Understanding Trainable and Non-Trainable Parameters in Batch Normalization
In any batch normalization layer, there are typically four parameters associated with the normalization process:
- γ (Scale) – Trainable
- β (Shift) – Trainable
- μ (Moving Mean) – Non-Trainable
- σ (Moving Variance) – Non-Trainable
Trainable Parameters: γ and β
γ (Scale): This parameter scales the normalized output, allowing the model to control the variance after normalization. Without this parameter, the network might lose the ability to represent inputs with varying magnitudes.
β (Shift): This parameter shifts the normalized output, essentially adjusting the mean of the output distribution. It prevents the network from losing information about the original distribution after normalization.
Both γ and β are critical because they give the model the flexibility to learn the optimal scale and shift for the normalized activations during training. These parameters are updated via backpropagation, just like weights in a Dense layer.
Non-Trainable Parameters: μ and σ
μ (Moving Mean): This is the running average of the means computed over each mini-batch during training. It provides a stable mean during inference when the batch statistics might differ from the training phase.
σ (Moving Variance): Similar to the moving mean, this is the running average of the variance computed over each mini-batch. It stabilizes the variance during inference.
These parameters are crucial for ensuring that the batch normalization behaves consistently during inference. Unlike γ and β, μ and σ are not updated by backpropagation; instead, they are updated by tracking the statistics during training.
When to Use Trainable and Non-Trainable Parameters
The decision of whether to keep γ and β trainable or fixed is often task-dependent. Here’s a guide on when and how to configure these parameters:
1. Standard Use Case (Trainable γ and β)
In most scenarios, you want γ and β to be trainable because they allow the network to learn the appropriate scaling and shifting, which can significantly improve performance, especially in deeper networks.
tf.keras.layers.BatchNormalization(trainable=True)
This configuration is the default in most frameworks, as it provides the network with the flexibility needed to adapt during training.
2. Fixed Scale and Shift (Non-Trainable γ and β)
There are cases where you might want to fix γ and β, such as when your model needs to behave predictably without adapting during training, or in certain transfer learning scenarios where pre-trained layers are being fine-tuned.
tf.keras.layers.BatchNormalization(scale=False, center=False)
This approach is less common but can be useful in specific architectures where you want to prevent the model from overfitting or when the normalized inputs are already well-distributed.
3. Custom Configurations
You might also encounter situations where only one of these parameters (either γ or β) is trainable. This might be the case in models where scaling is crucial but shifting is not, or vice versa.
tf.keras.layers.BatchNormalization(scale=True, center=False)
These custom settings can be explored based on the behavior of your model on validation data.
Practical Example: Understanding the Model Summary
Consider the following model structure, which includes batch normalization:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]),
tf.keras.layers.Dense(300, kernel_initializer="he_normal", use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation("relu"),
tf.keras.layers.Dense(100, kernel_initializer="he_normal", use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation("relu"),
tf.keras.layers.Dense(10, activation="softmax")
])
When you inspect the model summary, you’ll notice a distinction between trainable and non-trainable parameters:
Total params: 271,346
Trainable params: 268,978
Non-trainable params: 2,368
How to Interpret These Numbers:
– Impact on Model Capacity: Trainable parameters directly affect the model’s capacity to learn from data. More trainable parameters typically allow the model to capture more complex patterns, but they also increase the risk of overfitting.
– Role During Inference: Non-trainable parameters ensure consistent behavior during inference. They allow the model to maintain stable predictions even when batch statistics vary between training and inference.
<
Choosing the Right Configuration
The choice between trainable and non-trainable configurations should be informed by:
– Model Complexity: For simpler models, fixed γ and β might suffice, whereas deeper networks benefit from trainable parameters.
– Training Data: Large, diverse datasets generally require trainable γ and β to adapt well, while small datasets might benefit from fixed parameters to prevent overfitting.
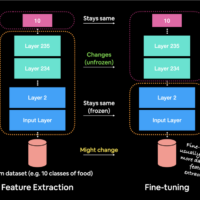
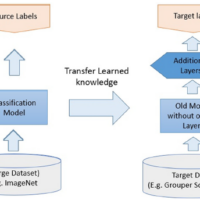
– Transfer Learning: In transfer learning, freezing γ and β in the early layers (especially those from a pre-trained model) might help maintain the learned features, while allowing later layers to adapt to new data.
Conclusion
Understanding the distinction between trainable and non-trainable parameters in batch normalization is essential for fine-tuning neural networks. By strategically configuring these parameters, you can enhance model performance, stabilize training, and ensure consistency during inference. Always consider the specific requirements of your task and experiment with different settings to find the optimal configuration.
This nuanced approach to batch normalization will empower you to make informed decisions when designing and training deep learning models, leading to more robust and effective results.