Understanding Non-Linearity in Neural Networks
Non-linearity in neural networks is essential for solving complex tasks where the data is not linearly separable. This blog post explains why hidden layers and non-linear activation functions are necessary, using the XOR problem as an example.
What is Non-Linearity?
Non-linearity in neural networks allows the model to learn and represent more complex patterns. In the context of decision boundaries, a non-linear decision boundary can bend and curve, enabling the separation of classes that are not linearly separable.
Role of Activation Functions
The primary role of an activation function is to introduce non-linearity into the neural network. Without non-linear activation functions, even networks with multiple layers would behave like a single-layer network, unable to learn complex patterns. Common non-linear activation functions include sigmoid, tanh, and ReLU.
Role of Hidden Layers
Hidden layers provide the network with additional capacity to learn complex patterns by applying a series of transformations to the input data. However, if these transformations are linear, the network will still be limited to linear decision boundaries. The combination of hidden layers and non-linear activation functions enables the network to learn non-linear relationships and form non-linear decision boundaries.
Mathematical Explanation
Without Hidden Layers
A single-layer neural network (perceptron) computes the output as:
Where:
- is the input vector.
- is the weight vector.
- is the bias.
- is the activation function (e.g., sigmoid).
For the decision boundary:
This is a linear equation, so the decision boundary is a straight line.
With Hidden Layers
A neural network with one hidden layer computes the output as:
Where:
- are the weights and biases for the hidden layer.
- are the weights and biases for the output layer.
- and are activation functions (e.g., tanh).
The non-linear activation function introduces non-linearity, enabling the network to learn complex patterns and create non-linear decision boundaries.
Understanding Non-Linearity in Neural Networks
Example: XOR Problem
Example: XOR Problem
The XOR problem is a classic example of a non-linearly separable dataset. We will train a neural network with and without hidden layers to demonstrate how decision boundaries are formed.
Code with Hidden Layer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier
# Define the XOR dataset
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
# Train a neural network
mlp = MLPClassifier(hidden_layer_sizes=(2,), activation='tanh', max_iter=10000, random_state=42)
mlp.fit(X, y)
# Plot the decision boundary
def plot_decision_boundary(model, X, y, title):
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired)
plt.title(title)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
plot_decision_boundary(mlp, X, y, "Neural Network Decision Boundary")
Code Without Hidden Layer
from sklearn.linear_model import LogisticRegression
# Train a logistic regression model
log_reg = LogisticRegression()
log_reg.fit(X, y)
# Plot decision boundaries
plot_decision_boundary(log_reg, X, y, "Logistic Regression Decision Boundary")
Analysis
- With Hidden Layer: The network creates a non-linear decision boundary, enabling it to solve the XOR problem. The hidden layer and activation function introduce the non-linearity required.
- Without Hidden Layer: The logistic regression model produces a linear decision boundary, failing to separate the XOR dataset correctly.
Comparison Table
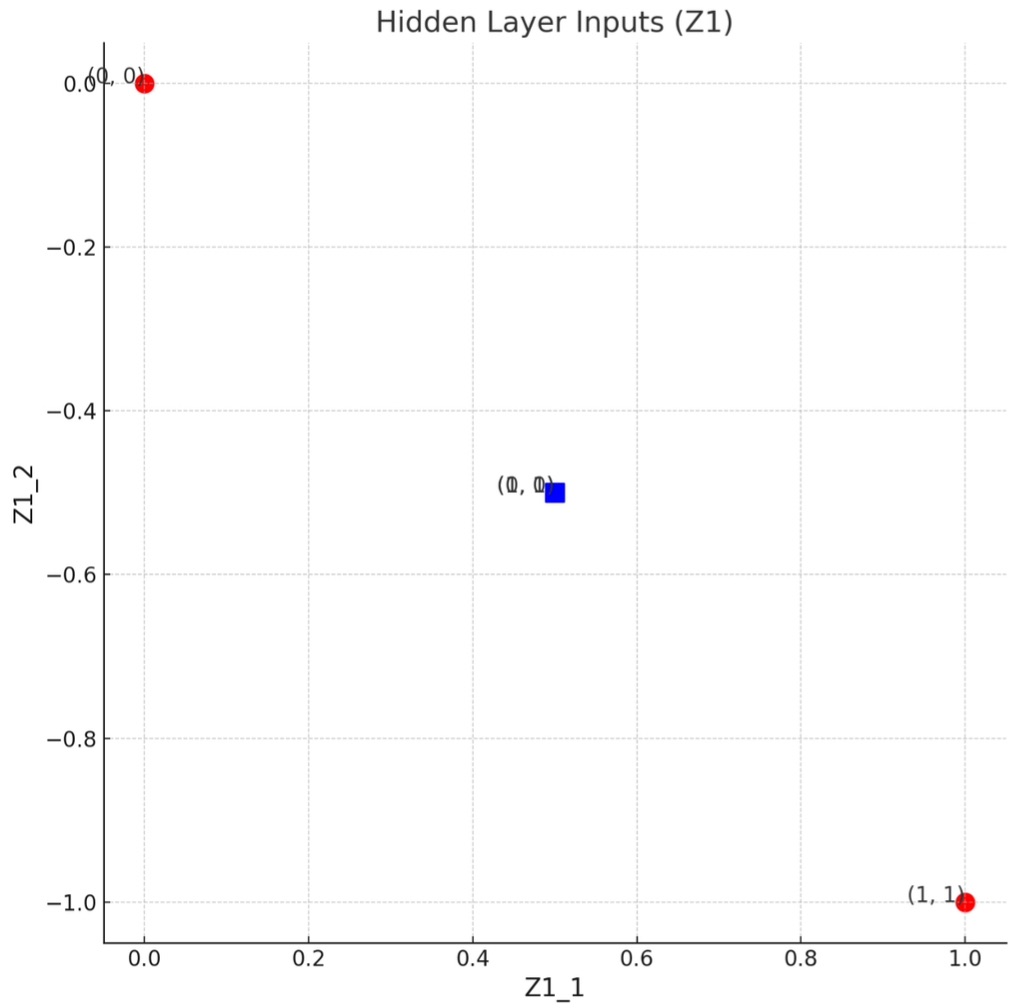
| Input | Hidden Layer Outputs () | Output () |
|---|---|---|
| (1, 0) | (0.462, -0.462) | 0.5 |
| (0, 1) | (0.462, -0.462) | 0.5 |
| (0, 0) | (0, 0) | 0.5 |
| (1, 1) | (0.762, -0.762) | 0.5 |
Conclusion
The combination of hidden layers and non-linear activation functions allows neural networks to solve complex problems like XOR. By introducing non-linearity, the network can create flexible decision boundaries capable of separating non-linearly separable datasets.