

Abstract
Machine learning models are often developed using frameworks like PyTorch and TensorFlow, which offer dynamic graphing and flexibility. However, deploying these models on Apple devices requires their conversion to Core ML. This paper delves into the mathematical processes behind such conversions, emphasizing tensor format transformations, weight serialization, and graph representation. It also explores Core ML’s hardware optimizations, offering a complete understanding of the transformation process.
1. Introduction
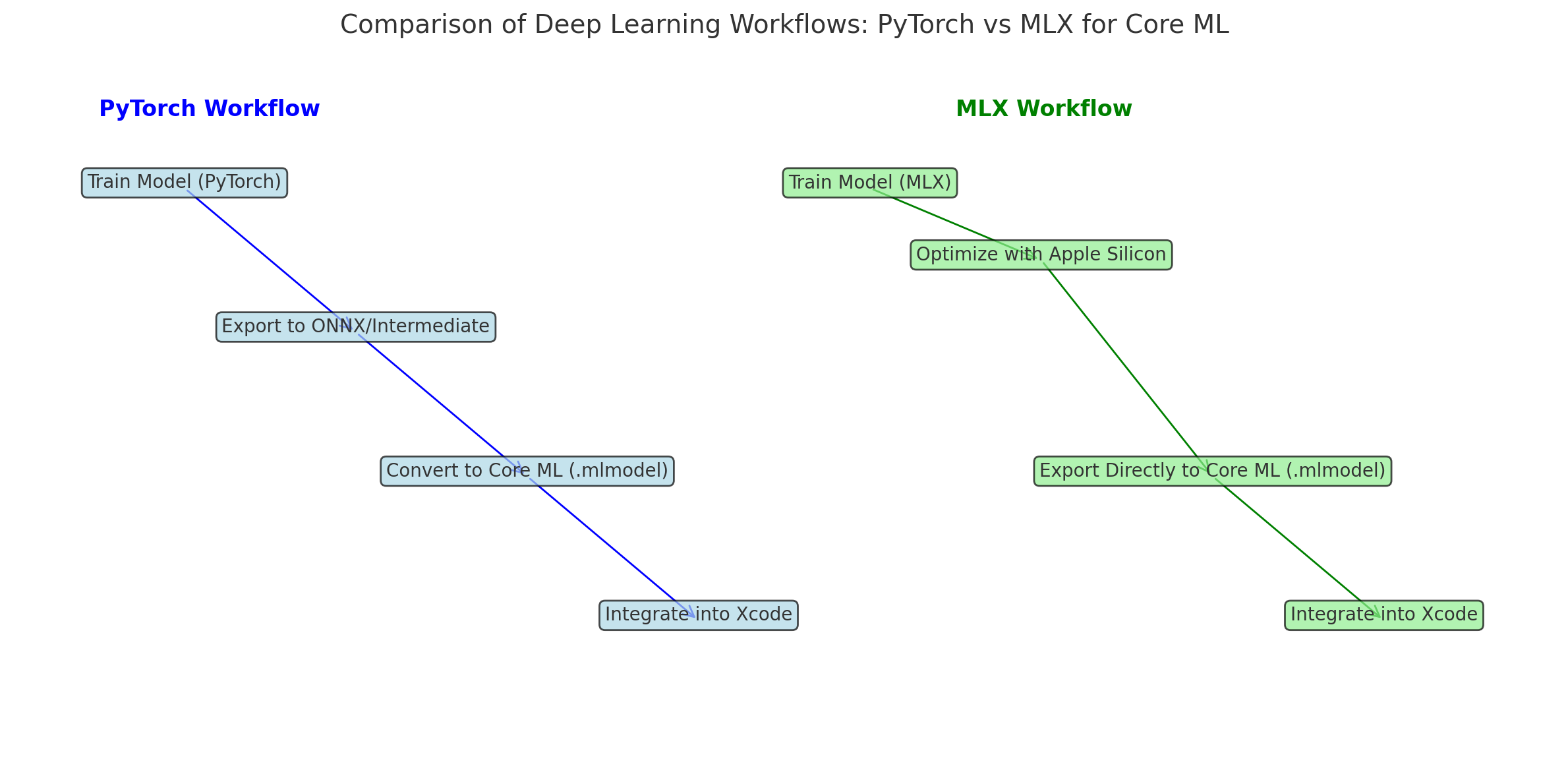
Core ML is Apple’s proprietary framework optimized for deploying machine learning models on iOS devices. Unlike PyTorch and TensorFlow, which prioritize training, Core ML is built for inference, utilizing Apple’s hardware to enhance performance.
Core ML requires models to be in a static computational graph format, necessitating mathematical transformations to ensure compatibility and accuracy. This paper provides insights into:

- Tensor representations and operations.
- Graph transformations (dynamic to static).
- Optimizations specific to Core ML and Apple hardware.
—
2. Tensor Representations and Operations
2.1 Tensor Definitions
Tensors are generalizations of scalars, vectors, and matrices. They represent data in multi-dimensional arrays, crucial for neural network computations. A tensor is mathematically defined as:

Where  are the dimensions of the tensor. For example:
are the dimensions of the tensor. For example:
- A scalar is a 0-dimensional tensor.
- A vector is a 1-dimensional tensor.
- A matrix is a 2-dimensional tensor.
2.2 Tensor Operations
Neural networks heavily rely on tensor operations like addition and multiplication:
- Tensor Addition: Adds tensors element-wise, assuming identical shapes:

- Tensor Multiplication: Extends matrix multiplication across dimensions:

This forms the backbone of linear transformations in neural networks.
—
3. Computational Graphs
3.1 Static vs. Dynamic Graphs
Frameworks like PyTorch use dynamic graphs, building operations on-the-fly during execution. In contrast, Core ML relies on static graphs, where all operations are pre-defined. Static graphs enable greater optimization but reduce flexibility.
3.2 Graph Conversion
Converting a dynamic graph (PyTorch) to a static graph (Core ML) involves two key steps:
- Tracing: Recording the model’s operations with sample data.
- Freezing: Saving the computational graph with fixed parameters.
Mathematical representation of a linear layer:

Where:
 : Input tensor
: Input tensor : Weight matrix
: Weight matrix : Bias vector
: Bias vector
—
4. Tensor Format Conversion
4.1 Format Differences
Tensors differ in layout conventions across frameworks:
- **NCHW**: Batch size, channels, height, and width (PyTorch).
- **NHWC**: Batch size, height, width, and channels (Core ML).
4.2 Permutation
To convert tensors from NCHW to NHWC, their axes are permuted:
![T'_{NHWC} = \text{Permute}(T_{NCHW}, [0, 2, 3, 1])](https://i0.wp.com/ingoampt.com/wp-content/ql-cache/quicklatex.com-3bfc311db8a58c9c7f14bc8b1bd3b441_l3.png?resize=302%2C19&ssl=1 "Rendered by QuickLaTeX.com")
Where ![[0, 2, 3, 1]](https://i0.wp.com/ingoampt.com/wp-content/ql-cache/quicklatex.com-05770c0c2e6b56175b5a1f324ac36f90_l3.png?resize=65%2C18&ssl=1 "Rendered by QuickLaTeX.com") indicates the new axis order.
indicates the new axis order.
Example:
Input tensor: 
Output tensor: 
—
5. Weight Serialization
5.1 Convolutional Layer Weights
Convolutional weights must be serialized to match Core ML’s requirements. PyTorch stores weights as:

Core ML requires weights in:

5.2 Transposition
To convert weights, transpose the dimensions:
![W' = \text{Transpose}(W, [2, 3, 1, 0])](https://i0.wp.com/ingoampt.com/wp-content/ql-cache/quicklatex.com-5de5329b5c05293ca0e962164372d633_l3.png?resize=232%2C19&ssl=1 "Rendered by QuickLaTeX.com")
—
6. Matrix Multiplications
6.1 Mathematical Definition
Matrix multiplication underpins fully connected layers. For matrices:
The product  is:
is:

6.2 Optimization
Core ML optimizes these multiplications using Apple’s Metal Performance Shaders (MPS), leveraging GPU parallelism.
—
1. Detailed Tensor Format Conversion
1.1 Context of Conversion
Tensors in machine learning represent data as multi-dimensional arrays. Different frameworks use different formats for storing these arrays:
- PyTorch: Uses the NCHW format (Batch Size, Channels, Height, Width).
- Core ML: Requires the NHWC format (Batch Size, Height, Width, Channels).
1.2 Mathematical Representation
To convert tensors from NCHW to NHWC, we permute the axes:
This reorders the dimensions of the tensor. For example:
Input tensor in PyTorch:
After conversion to Core ML:
1.3 Why This Matters
The reordering ensures compatibility with Core ML’s inference engine, which is optimized for the NHWC layout due to GPU hardware requirements.
—
2. Weight Serialization and Transformation
2.1 Weight Storage Formats
In convolutional layers, weights are stored as 4D tensors. The format varies by framework:
- PyTorch:
- Core ML:
2.2 Transposing Weights
The weights must be transposed during conversion to match Core ML’s expected format:
This ensures the convolution operation remains mathematically consistent.
2.3 Mathematical Proof of Consistency
The convolution operation is defined as:

The transposition aligns the indices for the kernel dimensions and channels, ensuring the output remains accurate post-conversion.
—
3. Matrix Multiplications in Fully Connected Layers
3.1 Definition
Fully connected layers rely on matrix multiplication, which is mathematically defined as:

Where:
 : Input matrix
: Input matrix : Weight matrix
: Weight matrix : Output matrix
: Output matrix
3.2 Core ML Optimization
Core ML uses Metal Performance Shaders (MPS) to perform matrix multiplications efficiently by leveraging:
- Parallelism across GPU cores.
- Unified memory architecture to minimize memory transfer overhead.
3.3 Importance of Optimization
Matrix multiplication is computationally expensive with a time complexity of  . Optimizing this operation significantly reduces inference latency on Apple devices.
. Optimizing this operation significantly reduces inference latency on Apple devices.
—
4. Non-Linear Activations
4.1 Swish Activation Function
The Swish activation function is mathematically defined as:

Core ML does not natively support Swish, requiring approximations.
4.2 Polynomial Approximation
A second-order polynomial can approximate Swish:

This approximation balances computational efficiency with accuracy.
—
5. Challenges in Model Conversion
5.1 Graph Translation
Dynamic graphs (used in PyTorch) must be converted to static graphs (used in Core ML). This involves tracing and freezing the model’s operations with sample data.
5.2 Numerical Precision
Core ML often uses  (16-bit floating point) to improve performance during inference. Conversion from
(16-bit floating point) to improve performance during inference. Conversion from  (32-bit floating point) involves rounding:
(32-bit floating point) involves rounding:

5.3 Validation
Post-conversion validation ensures:
- Accuracy of predictions is preserved.
- Inference latency is reduced.
—
Conclusion
Core ML optimizes machine learning models for deployment on Apple devices through tensor format alignment, weight serialization, and hardware acceleration. Understanding these mathematical principles ensures successful model conversion and optimal performance.