Understanding BERT: How It Works and Why It’s Transformative in NLP
BERT (Bidirectional Encoder Representations from Transformers) is a foundational model in Natural Language Processing (NLP) that has reshaped how machines understand language. Developed by Google in 2018, BERT brought significant improvements in language understanding tasks by introducing a bidirectional transformer-based architecture that reads text in both directions (left-to-right and right-to-left). This blog post will dive deep into how BERT works, its architecture, pretraining strategies, and its applications, complemented by tables and figures for better comprehension.
1. BERT’s Architecture
At its core, BERT is based on the transformer architecture, specifically utilizing the encoder part of the transformer model.
Key Components:
- Self-Attention Mechanism: BERT uses multi-headed self-attention to focus on different parts of a sentence, learning which words are important relative to each other.
- Layers: BERT models come in two sizes—BERT-Base (12 layers) and BERT-Large (24 layers). These layers process the text at different levels of abstraction.
Table 1: BERT-Base vs. BERT-Large
| Model | Layers | Hidden Units | Attention Heads | Parameters |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | 110 million |
| BERT-Large | 24 | 1024 | 16 | 340 million |
2. Bidirectional Learning in BERT
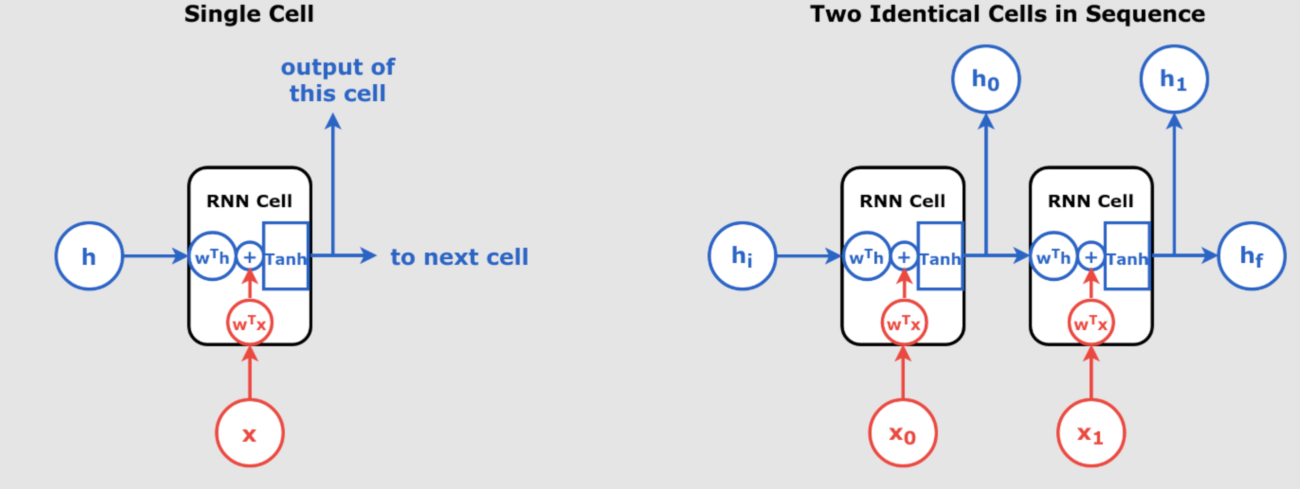
Previous models like GPT were unidirectional, meaning they processed text only from left to right. BERT, however, uses a bidirectional approach, allowing it to read the entire context of a word by looking at the words both before and after it. This improves BERT’s ability to understand the nuances of language, particularly for tasks like sentiment analysis and question answering.

Figure 1: Unidirectional vs. Bidirectional Language Models
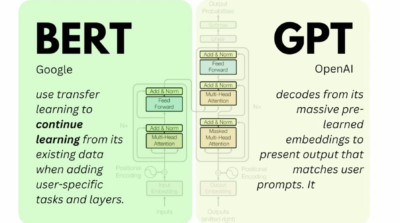
- Title of the image source : “深蓝学院第八节笔记 构建一个GPT模型“
- Author: weixin_46479223 on CSDN
- License: CC BY-SA 4.0
3. Pretraining Strategies: MLM and NSP
BERT’s training involves two innovative pretraining objectives:
- Masked Language Model (MLM): BERT randomly masks 15% of the tokens in each sentence and trains to predict those masked words. This forces the model to learn context from both directions.
- Next Sentence Prediction (NSP): BERT is also trained to predict whether a given sentence follows another sentence. This task is crucial for understanding sentence relationships in tasks like question answering.
Table 2: Pretraining Tasks in BERT
| Task | Description | Example |
|---|---|---|
| Masked Language Model (MLM) | Predicts masked words in a sentence | “The cat sat on the [MASK].” |
| Next Sentence Prediction (NSP) | Predicts whether two sentences follow each other | “He went to the store. He bought milk.” |
4. Applications of BERT
1. Question Answering
BERT is trained to understand the context of passages and answer questions based on them. It excels in SQuAD (Stanford Question Answering Dataset) by locating the exact span of text that answers a question.
2. Sentiment Analysis
Fine-tuned BERT models can analyze the sentiment of a text (positive, negative, or neutral) by understanding how context affects the meaning of words.
3. Text Summarization
BERT can be combined with abstractive summarization models to generate human-like summaries that rephrase and condense text, while extractive methods focus on pulling key sentences.
5. BERT’s Influence and Limitations
Influence:
- Transfer Learning: BERT popularized the use of pretraining and fine-tuning in NLP, enabling models to generalize across tasks with minimal modifications.
- Adaptations: Several variations of BERT have emerged, such as RoBERTa (more training data, longer training) and DistilBERT (smaller and faster but still effective).
Limitations:
- Computational Complexity: BERT is computationally expensive to train and fine-tune, requiring significant resources.
- Handling Long Texts: BERT struggles with longer texts due to its 512-token input limit. Solutions like Longformer extend BERT’s capacity for longer inputs.
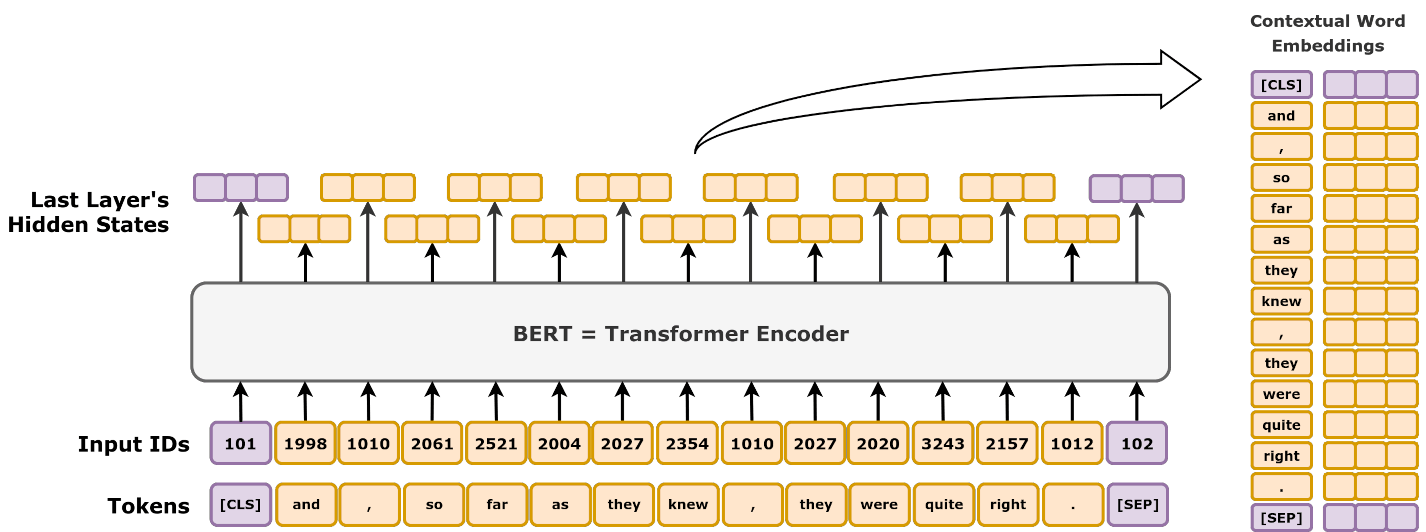
6. Visualizing BERT’s Working
Figure 2: BERT Transformer Encoder
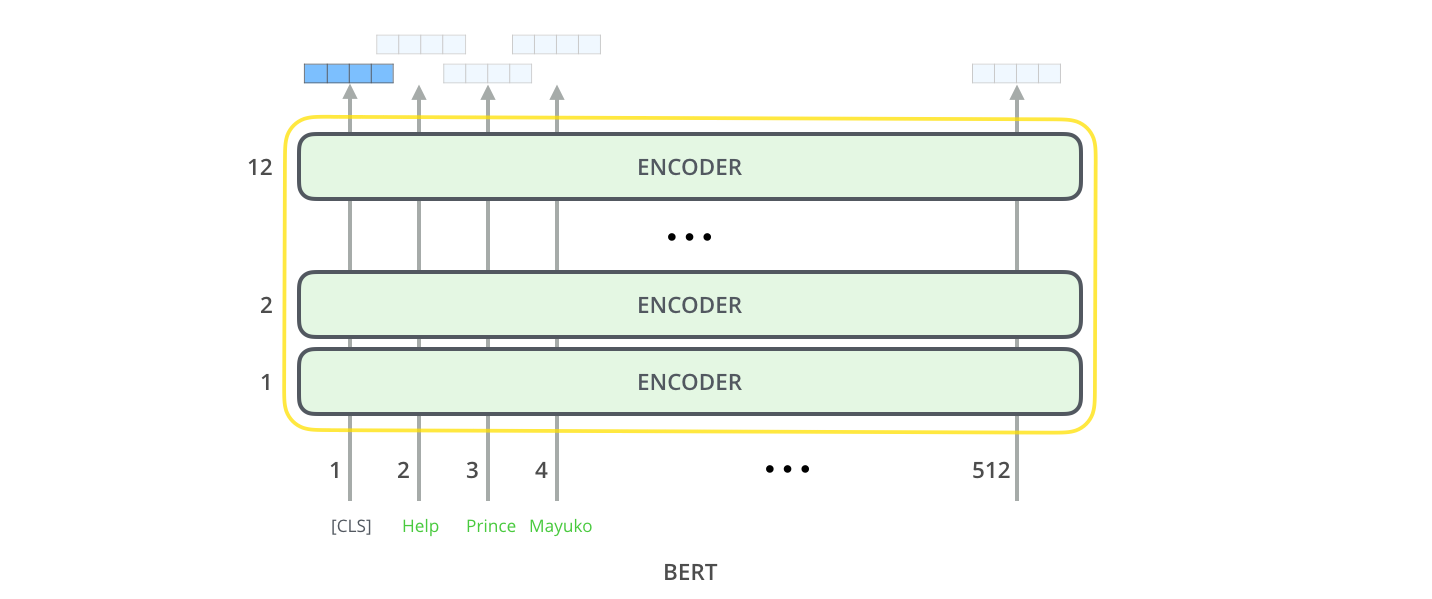
Source: Jalammar.github.io
7. Future Directions for BERT
While BERT is a cornerstone in NLP, there are active research efforts focused on overcoming its challenges:
- Efficiency Improvements: Variants like DistilBERT aim to reduce the size and computational demands of BERT without sacrificing too much performance.
- Multilingual Capabilities: Models like mBERT and XLM-R expand BERT’s capabilities to handle multiple languages effectively, which is increasingly important in global applications.
- Handling Longer Sequences: Extensions like Longformer adapt BERT for handling longer documents by modifying its attention mechanisms.
-
Enhanced Multilingual Capabilities: Google is expected to continue improving BERT’s understanding of different languages, expanding its reach to include underrepresented languages, thereby making it even more effective globally(JEMSU). This focus will make search engines and other NLP tools more relevant in diverse linguistic contexts.
-
Improved Efficiency: One of the significant anticipated updates for BERT in the coming years is improving its efficiency, making it lighter and faster. This will allow the model to be deployed on devices with lower processing power without sacrificing performance. This is particularly important for making NLP tools more accessible and reducing the computational costs(JEMSU)(Ryadel).
-
Deeper Integration Across Applications: BERT will likely be used more deeply across Google’s ecosystem, not only for search but also for improving the relevance of ads and making other products more context-aware. This integration will enhance the personalization of services like Google Ads and other AI-driven tools(JEMSU).
-
Combinational AI: One of the emerging trends is the use of combinational AI, where BERT or similar models work in tandem with other AI models to solve more complex problems, such as customer behavior prediction. Technologies like LangChain enable AI systems to combine insights from various models, and this trend will continue growing, especially in enterprise settings(DATAVERSITY).
-
Ethics and Efficiency: The rise of smaller language models (SLMs) alongside BERT will address concerns over the computational expense of large models. These smaller, more efficient models are predicted to become highly versatile and deployable even on edge devices, opening up new possibilities for real-time, low-power NLP applications(AI News).
In summary, BERT is set to evolve with a focus on efficiency, multilingual capabilities, and broader integration across applications. With ongoing innovations and a push towards more ethical and resource-efficient AI, BERT will continue to play a vital role in NLP in the coming years.
Conclusion
BERT has revolutionized NLP by introducing a bidirectional architecture and self-attention mechanisms that enable it to deeply understand context. Its influence on NLP tasks like question answering, sentiment analysis, and text summarization is unmatched, and its architecture has paved the way for newer, more advanced models. Although BERT has its limitations, ongoing research and adaptations continue to improve its efficiency and extend its capabilities across various languages and tasks.
For those interested in diving deeper into the world of NLP, understanding BERT is essential as it forms the foundation of many state-of-the-art models today.
References
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- DistilBERT: A smaller and faster BERT model
- SQuAD (Stanford Question Answering Dataset)
- Visualizing BERT with Transformer Encoder
- Longformer: The Long Document Transformer