

A Deep Dive into Recurrent Neural Networks, Layer Normalization, and LSTMs
Recurrent Neural Networks (RNNs) are a cornerstone in handling sequential data, ranging from time series analysis to natural language processing. However, training RNNs comes with challenges, particularly when dealing with long sequences and issues like unstable gradients. This post will cover how Layer Normalization (LN) addresses these challenges and how Long Short-Term Memory (LSTM) networks provide a more robust solution to memory retention in sequence models.
The Challenges of RNNs: Long Sequences and Unstable Gradients
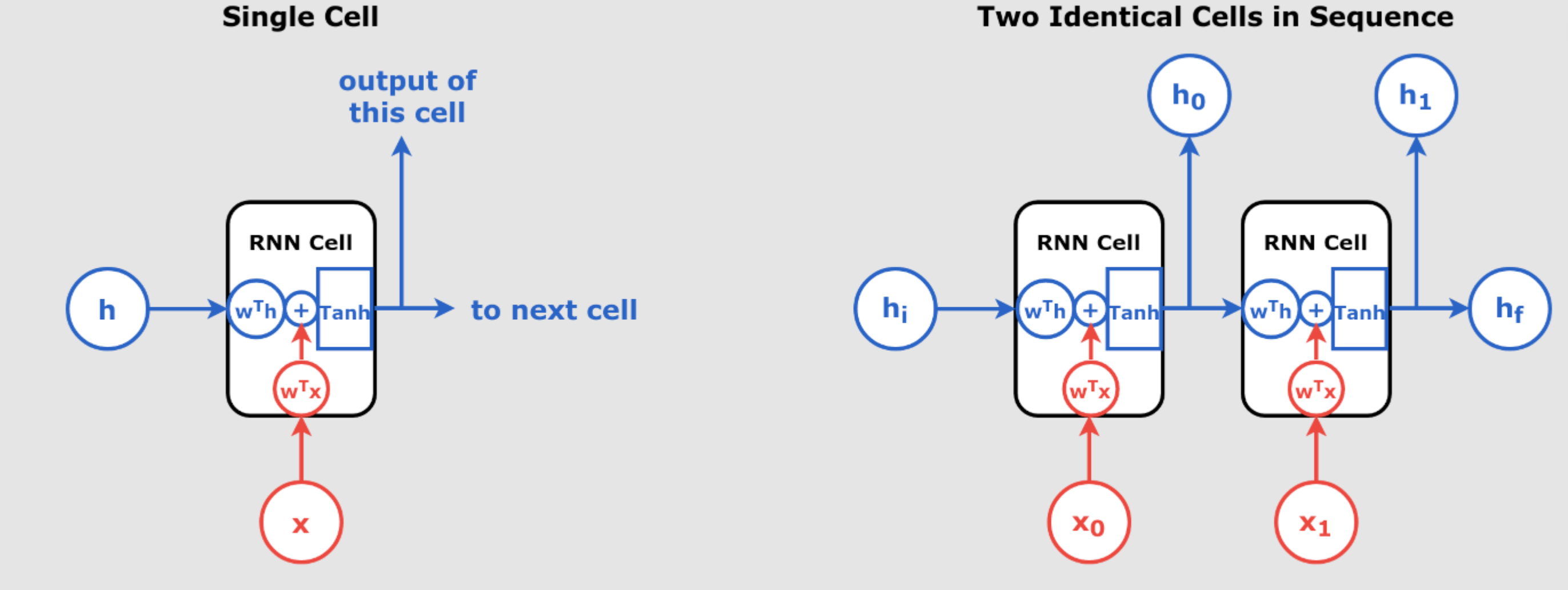
When training an RNN over long sequences, the network can experience the unstable gradient problem—where gradients either explode or vanish during backpropagation. This makes training unstable and inefficient. Additionally, RNNs may start to “forget” earlier inputs as they move forward through the sequence, leading to poor retention of important data points, a phenomenon referred to as the short-term memory problem.
Addressing Unstable Gradients:
- Gradient Clipping: Limits the maximum value of gradients, ensuring they don’t grow excessively large.
- Smaller Learning Rates: Using a smaller learning rate helps prevent gradients from overshooting during updates.
- Activation Functions: Saturating activation functions like the hyperbolic tangent (tanh) help control gradients better than ReLU in RNNs.
- Layer Normalization: As we’ll explore further, layer normalization is particularly well-suited to address this issue in RNNs.
Why Batch Normalization Doesn’t Work Well with RNNs
Batch Normalization (BN) is popular in feedforward and convolutional neural networks because it helps stabilize training and accelerates convergence. However, BN does not work as effectively in RNNs for several reasons:
- Temporal Dependence: In RNNs, hidden states evolve over time, making it difficult to normalize across mini-batches at each time step.
- Small Batches in Sequential Data: BN requires large batch sizes to compute meaningful statistics, which is often impractical for RNNs that operate on smaller batch sizes or variable-length sequences.
- Sequence Variation: Since BN operates across mini-batches, it struggles to accommodate variable sequence lengths common in sequential tasks like text processing.
In contrast, Layer Normalization (LN) normalizes across features within each time step, allowing it to handle sequences efficiently.

Layer Normalization: The Solution for RNNs
Layer Normalization was introduced to solve some of the limitations of BN in RNNs. It operates by normalizing across the features within a layer, rather than across the mini-batch. This approach is particularly useful in RNNs because it:
- Normalizes Independently of Batch Size: LN calculates statistics (mean and variance) for each time step across the features, making it independent of batch size, which is critical in sequence tasks.
- Stabilizes Gradient Flow: By normalizing the input at each time step, LN ensures smoother gradient flow, reducing both exploding and vanishing gradient problems that are common in RNNs.
Layer Normalization Code Example:
class LNSimpleRNNCell(tf.keras.layers.Layer): def __init__(self, units, activation="tanh", **kwargs): super().__init__(**kwargs) self.state_size = units self.output_size = units self.simple_rnn_cell = tf.keras.layers.SimpleRNNCell(units, activation=None) self.layer_norm = tf.keras.layers.LayerNormalization() self.activation = tf.keras.activations.get(activation) def call(self, inputs, states): outputs, new_states = self.simple_rnn_cell(inputs, states) norm_outputs = self.activation(self.layer_norm(outputs)) return norm_outputs, [norm_outputs]How to Use It in a Model:
custom_ln_model = tf.keras.Sequential([ tf.keras.layers.RNN(LNSimpleRNNCell(32), return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ])This model is equipped with the custom cell that normalizes each time step and addresses the gradient issues in RNNs.
The Short-Term Memory Problem and LSTMs
Even with Layer Normalization, standard RNNs often fail to retain important information over long sequences, which brings us to Long Short-Term Memory (LSTM) networks. LSTMs are specifically designed to address the short-term memory problem by maintaining two key states:
- Short-Term State (hₜ): Captures the most recent information at the current time step.
- Long-Term State (cₜ): Stores information over longer sequences, allowing the network to retain useful context for more extended periods.
LSTM Structure: LSTMs introduce three gates—forget, input, and output—that control the flow of information, deciding which information to retain, which to discard, and what to output at each step.
LSTM Code Example:
model = tf.keras.Sequential([ tf.keras.layers.LSTM(32, return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ])LSTMs use these gates to manage memory and retain long-term dependencies in the data, solving one of the most critical challenges in sequence modeling.
How Layer Normalization and LSTMs Improve RNNs
By combining Layer Normalization and LSTMs, we can build models that effectively handle long sequences and mitigate unstable gradients:
- Layer Normalization: Stabilizes the training process and ensures smooth gradient flow, preventing exploding or vanishing gradients.
- LSTMs: Allow the network to maintain long-term memory, enabling it to better understand long-range dependencies in the sequence data.
Both techniques work in harmony to tackle the primary weaknesses of traditional RNNs, making them essential tools for anyone working with sequential data like time series, language models, or any application requiring memory retention over time.
Summary Table
| Method | Purpose | Key Advantage |
|---|---|---|
| Layer Normalization | Normalize across features in RNNs | Handles variable batch sizes efficiently |
| LSTM | Retain long-term memory in sequences | Manages long-range dependencies |
Let’s Continue with GRU, LSTM, and Modern Architectures in 2024 (With Relation to RNNs and PyTorch Implementation)
Gated Recurrent Unit (GRU) in 2024
GRUs continue to be an efficient alternative to LSTMs, especially in situations where computational efficiency is crucial. As of 2024, GRUs are often preferred in resource-constrained environments, such as mobile applications, due to their simpler architecture and faster training times compared to LSTM. GRU’s gating mechanism, which combines the forget and input gates into a single update gate, allows them to train faster while maintaining good performance on shorter sequences and tasks that don’t require as much memory as LSTMs.
Mathematical Recap of GRU:
The GRU update equations are:




Relation to RNNs:
GRUs are a direct evolution of vanilla RNNs, which suffered from the vanishing gradient problem that prevented them from learning long-term dependencies. By introducing the update and reset gates, GRUs offer a more flexible mechanism for learning dependencies over time.
PyTorch Implementation:
import torch import torch.nn as nn class GRUModel(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(GRUModel, self).__init__() self.gru = nn.GRU(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): out, _ = self.gru(x) out = self.fc(out[:, -1, :]) return out model = GRUModel(input_size=10, hidden_size=20, output_size=1)Use Cases:
- Music Modeling and Speech Signal Processing benefit significantly from GRU’s efficiency, particularly in systems that prioritize real-time performance and memory constraints.
—
LSTM in 2024: Still a Heavyweight
Although GRUs are faster, LSTMs remain the go-to model for tasks that require a deep understanding of long-range dependencies. The additional cell state in LSTMs allows them to retain information over longer periods, making them suitable for time series forecasting, language modeling, and stock market prediction.
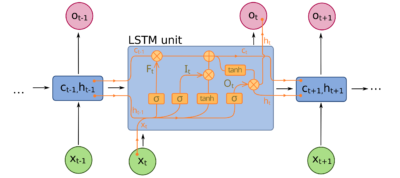
Mathematics Behind LSTM:
LSTMs update their cell state and hidden state with the following equations:






Relation to RNNs:
LSTMs improve over vanilla RNNs by solving the vanishing gradient problem. RNNs tend to “forget” early inputs as time progresses, but LSTMs address this by using their cell state to retain information over longer sequences. The forget and input gates in LSTMs allow selective memory updates, enabling them to excel in tasks with long-term dependencies, such as machine translation.
PyTorch Implementation:
import torch import torch.nn as nn class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(LSTMModel, self).__init__() self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): out, _ = self.lstm(x) out = self.fc(out[:, -1, :]) return out model = LSTMModel(input_size=10, hidden_size=20, output_size=1)Use Cases:
- Machine Translation and complex time series forecasting tasks still favor LSTMs when long-range dependencies need to be learned and retained.
—
1D Convolution + GRU: Hybrid Models
In modern architectures, the combination of 1D Convolutional layers and GRUs has become a popular hybrid approach for time series analysis. Conv1D layers can efficiently extract features from sequences, while the GRU captures longer-term dependencies. This hybrid approach has been particularly useful in domains like audio processing and biomedical signal processing.
Mathematics Behind Conv1D:
A 1D convolution operation is given by:

By applying 1D convolutions before GRUs, you reduce the complexity of the input and capture local patterns before the GRU layer learns the global sequence structure.
Relation to RNNs:
Traditional RNNs and GRUs can struggle to capture both short-term and long-term dependencies efficiently. By combining Conv1D layers, which act as local feature extractors, and GRUs, which focus on long-term dependencies, hybrid models can handle both local and global patterns in the data.
PyTorch Implementation:
import torch import torch.nn as nn class ConvGRUModel(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(ConvGRUModel, self).__init__() self.conv1d = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3, stride=1) self.gru = nn.GRU(16, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): x = self.conv1d(x.unsqueeze(1)) x = x.transpose(1, 2) <!-- Switch to batch_first --> out, _ = self.gru(x) out = self.fc(out[:, -1, :]) return out model = ConvGRUModel(input_size=10, hidden_size=20, output_size=1)—
WaveNet and Transformers in 2024: Modern Solutions for Sequence Modeling
WaveNet and Transformers have become dominant models in 2024, particularly for tasks such as speech synthesis, audio generation, and NLP. While recurrent models like GRU and LSTM rely on sequential processing, WaveNet and Transformers leverage parallel processing for faster training and inference.
WaveNet, developed by DeepMind, relies on dilated convolutions rather than recurrence, which allows it to efficiently capture long-range dependencies without sequential backpropagation.
Transformers, on the other hand, use self-attention mechanisms to process the entire sequence at once, making them particularly powerful for tasks requiring long-range context, such as machine translation and text summarization.
Relation to RNNs:
Both WaveNet and Transformers represent a significant departure from traditional RNN-based models. Instead of relying on recurrence to process sequences, these models handle long-range dependencies either through dilated convolutions (WaveNet) or self-attention mechanisms (Transformers), bypassing the limitations of recurrence entirely.
PyTorch Implementation (WaveNet & Transformers):
WaveNet:
class WaveNetModel(nn.Module): def __init__(self, in_channels, out_channels, num_layers): super(WaveNetModel, self).__init__() self.dilated_convs = nn.ModuleList( [nn.Conv1d(in_channels, out_channels, kernel_size=2, dilation=2**i, padding=2**i) for i in range(num_layers)] ) def forward(self, x): for conv in self.dilated_convs: x = conv(x) return xTransformers:
import torch.nn as nn import torch.nn.functional as F class TransformerModel(nn.Module): def __init__(self, input_size, num_heads, hidden_size, num_layers): super(TransformerModel, self).__init__() self.transformer = nn.Transformer( d_model=input_size, nhead=num_heads, num_encoder_layers=num_layers ) self.fc = nn.Linear(input_size, hidden_size) def forward(self, src, tgt): out = self.transformer(src, tgt) out = self.fc(out) return out—
Table Summarizing Modern Sequence Models
| Model | Relation to RNNs | Mathematical Principle | 2024 Use Cases |
|---|---|---|---|
| LSTM | Improves RNN by solving vanishing gradients using memory cells. | Separate cell state  and hidden state and hidden state  , with gates for controlling information flow. , with gates for controlling information flow. |
Machine translation, time series forecasting |
| GRU | Faster, simpler version of LSTM with fewer gates. | Combines memory and state with two gates: update  and reset and reset  . . |
NLP, speech recognition, time series analysis |
| 1D Convolution + GRU | Combines RNN-like sequence modeling with convolution for local patterns. | Convolutional layers extract local patterns, followed by GRU capturing long-term dependencies. | Audio processing, biomedical signal processing |
| WaveNet | Avoids recurrence by using dilated convolutions. | Stacked dilated convolutions with causal padding. | Speech synthesis, audio generation |
| Transformers | Completely replaces RNN recurrence with self-attention. | Self-attention mechanism, processes the entire sequence at once without recurrence. | NLP, machine translation, question answering |
—
Conclusion: The Evolution of Sequence Models in 2024
In 2024, sequence models have evolved beyond their recurrent roots. LSTMs and GRUs are still widely used, but newer architectures like Transformers and WaveNet have become the models of choice for many applications, particularly in NLP and speech synthesis.
While LSTMs are effective for tasks requiring long-term dependencies, GRUs offer faster training and are preferred in situations where computational efficiency is essential. Hybrid models, like Conv1D + GRU, combine local feature extraction with long-term sequence modeling, offering robust performance in fields like time series analysis and audio processing.
Finally, Transformers and WaveNet are reshaping the field by enabling efficient parallel processing, solving many of the limitations inherent in RNN-based models. Whether you’re working on natural language processing, machine translation, or speech generation, these models are pushing the boundaries of what’s possible in AI and deep learning.
By understanding how each of these architectures relates to traditional RNNs and how they are implemented in frameworks like PyTorch, you can choose the best solution for your specific application in 2024.