Understanding Recurrent Neural Networks (RNNs) and CNNs for Sequence Processing
Introduction
Introduction
In the world of deep learning, neural networks have become indispensable, especially for handling tasks involving sequential data, such as time series, speech, and text. Among the most popular architectures for such data are Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Although RNNs are traditionally associated with sequence processing, CNNs have also been adapted to perform well in this area. This blog will take a detailed look at how these networks work, their differences, their challenges, and their real-world applications.

1. Unrolling RNNs: How RNNs Process Sequences
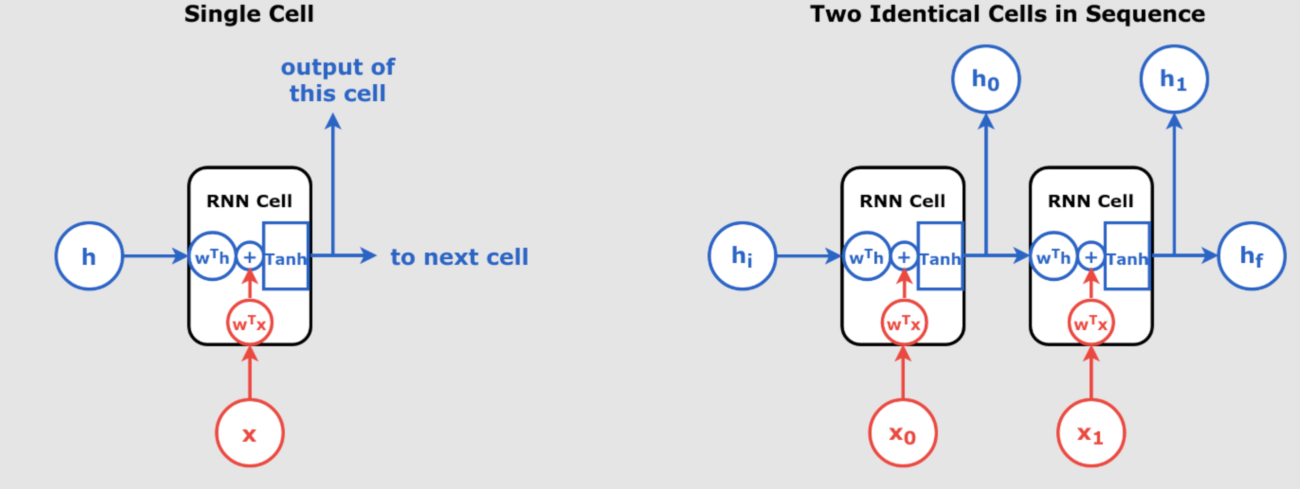
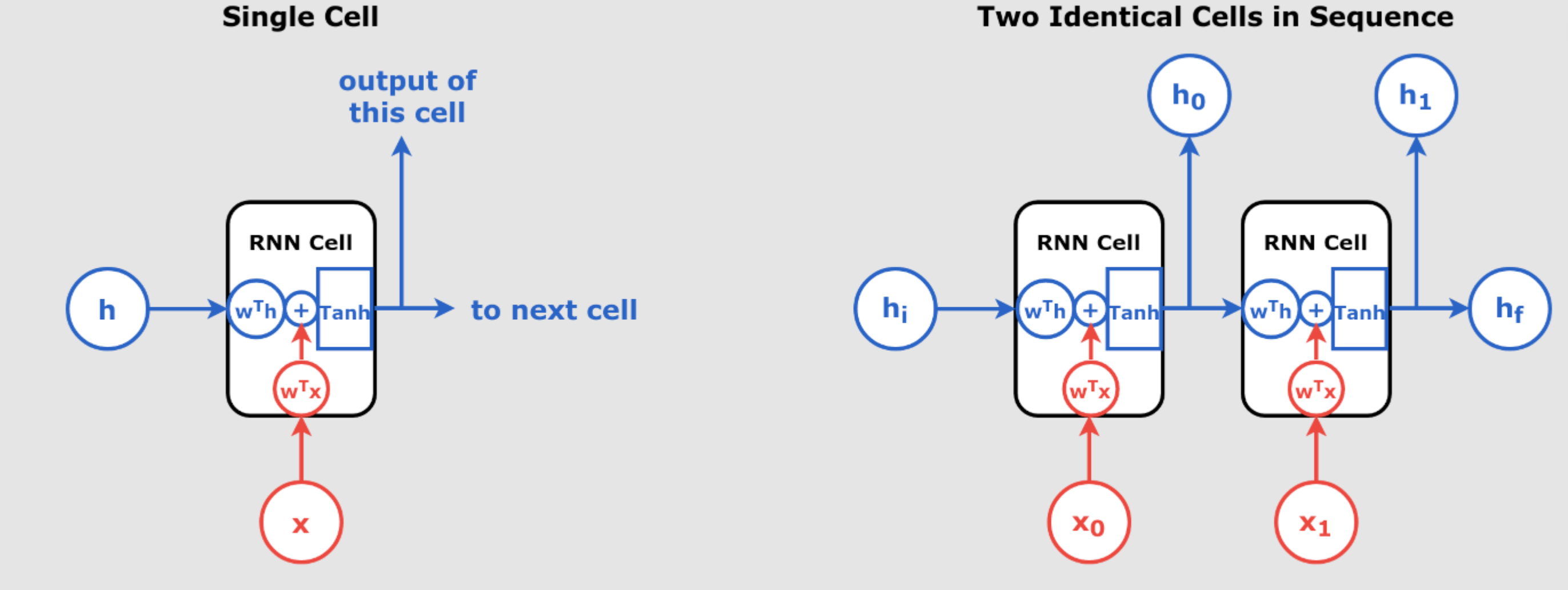
One of the most important concepts in understanding RNNs is unrolling. Unlike feedforward neural networks, which process inputs independently, RNNs have a “memory” that allows them to keep track of previous inputs by maintaining hidden states.
Unrolling in Time
At each time step \( t \), an RNN processes both:
- The current input \( x(t) \)
- The hidden state \( h(t-1) \), which contains information from the previous steps
The RNN essentially performs the same task repeatedly at each step, but it does so by incorporating past data (via the hidden state), making it ideal for sequence data.
| Time Step | Input | Hidden State (Memory) | Output |
|---|---|---|---|
| t=1 | x(1) | h(0) = Initial State | y(1) |
| t=2 | x(2) | h(1) = f(h(0), x(1)) | y(2) |
| t=3 | x(3) | h(2) = f(h(1), x(2)) | y(3) |
2. Challenges in Training RNNs
Despite the power of RNNs in handling sequence data, training them can be problematic due to two key issues:
2.1 Vanishing Gradients
When training RNNs using backpropagation through time (BPTT), the model learns by calculating the gradients of the loss function with respect to each weight. However, as these gradients are passed back through many layers (i.e., time steps), they can become incredibly small. This is known as the vanishing gradient problem, and it prevents the model from learning long-term dependencies in the data.
Solution: Architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) were developed to mitigate this issue by allowing the network to better retain information over longer sequences.
2.2 Lack of Parallelization
Unlike CNNs, which can process all inputs simultaneously, RNNs process sequences step-by-step, making them computationally slower. This is especially problematic when dealing with very long sequences or large datasets.
Solution: Faster models like CNNs or Transformer models are often used in practice when efficiency is critical, or RNNs are optimized through parallel computing techniques.
3. Applications of RNNs in the Real World
RNNs, especially LSTMs and GRUs, have a wide range of applications across industries:
3.1 Natural Language Processing (NLP)
RNNs are heavily used in NLP tasks such as:
- Language Translation: Understanding sequential context allows RNNs to excel in translating sentences from one language to another.
- Text Generation: RNNs can generate coherent text by predicting the next word based on previous words in the sequence.
3.2 Time-Series Forecasting
In fields like finance and energy, RNNs are used to predict future data points based on historical trends. This is useful for:
- Stock Price Prediction
- Energy Demand Forecasting
3.3 Speech Recognition
In speech recognition systems, RNNs are capable of converting spoken language into text by processing sequential audio data.
4. CNNs for Sequence Processing: An Alternative Approach
Although CNNs are traditionally used for images, they have been adapted for sequential data like audio and text. While RNNs focus on long-term dependencies, CNNs excel at detecting local patterns within sequences.
4.1 How CNNs Process Sequences
In sequence processing, CNNs use 1D convolutions to detect short-term relationships in data. For example:
- In text data, CNNs can recognize word patterns.
- In audio data, CNNs can detect frequency changes in short time windows.
This makes CNNs faster and more parallelizable than RNNs, although they might struggle with long-range dependencies, which RNNs handle better.
| Feature | RNN | CNN |
|---|---|---|
| Strength | Long-term dependencies | Local pattern detection |
| Memory Handling | Stores hidden states over time | No memory across time steps |
| Efficiency | Slower, sequential processing | Faster, parallelizable |
| Common Use Cases | NLP, time-series forecasting | Audio, text classification |
5. Overcoming RNN Limitations: Advanced Techniques
To address the challenges of training RNNs, several techniques and architectures have been developed:
5.1 LSTM and GRU
Both LSTM and GRU are designed to retain information over long time steps by using gates that control the flow of information:
- LSTM: Uses forget, input, and output gates to determine what to keep, what to update, and what to output.
- GRU: A simpler version of LSTM that uses fewer gates but still provides good performance for many tasks.
5.2 Dropout and Gradient Clipping
- Dropout: To prevent overfitting, dropout is used within RNN layers to randomly drop some connections during training.
- Gradient Clipping: In cases of exploding gradients, where the gradient becomes too large, gradient clipping ensures it stays within a manageable range, preventing the network from diverging during training.
6. RNNs vs. CNNs: Choosing the Right Model
When deciding whether to use an RNN or a CNN for a sequence processing task, it’s important to weigh the strengths of each model based on the specific problem at hand.
RNNs:
- Best for tasks requiring the network to remember information over long sequences (e.g., language translation).
CNNs:
- Ideal for tasks where detecting patterns in short time frames or data windows is important (e.g., sound classification).
Conclusion: The Right Model for the Right Job
Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) both have their strengths in sequence processing. RNNs, particularly LSTM and GRU variants, are best for tasks that require the memory of long-term dependencies, while CNNs are ideal for efficient parallel processing of local patterns. In many advanced tasks, these architectures are combined for even better performance.
As the field of AI evolves, so too do the models we use to understand sequential data. Understanding the nuances between RNNs and CNNs is critical for selecting the right tool for your machine learning project.
FAQs
- Why are RNNs good for sequential data?
RNNs are ideal for sequential data because they have a memory mechanism that allows them to retain information from previous time steps, making them effective at handling long-term dependencies.
- What is the vanishing gradient problem in RNNs?
The vanishing gradient problem occurs during training when gradients become very small, hindering the model’s ability to learn long-term dependencies.
- How do LSTM and GRU improve RNN performance?
LSTM and GRU are RNN variants that include gates to control the flow of information, allowing the network to retain important information over longer sequences.
- Can CNNs be used for sequential data?
Yes, CNNs can process sequential data by applying convolution operations over the sequence, making them efficient for tasks involving local pattern recognition.
- What is unrolling in RNNs?
Unrolling refers to the process of breaking down the RNN’s operations over time steps, revealing how the network processes each step in sequence.
- When should I use RNNs over CNNs?
Use RNNs for tasks that require understanding of long-term dependencies, like language translation or time-series forecasting. Use CNNs for tasks that focus on recognizing local patterns, like audio classification.