

Fine-Tuning vs. Transfer Learning: Adapting Voice Synthesis Models
Introduction
In the world of deep learning, transfer learning and fine-tuning are essential techniques that enable pre-trained models to quickly adapt to new tasks. These techniques are especially valuable in complex tasks like voice synthesis, where the model must capture the unique characteristics of a speaker’s voice. This post explores the differences between transfer learning and fine-tuning, why fine-tuning is essential for personalized voice synthesis, and includes an example code to fine-tune a voice synthesis model using Google Colab.
What is Transfer Learning?
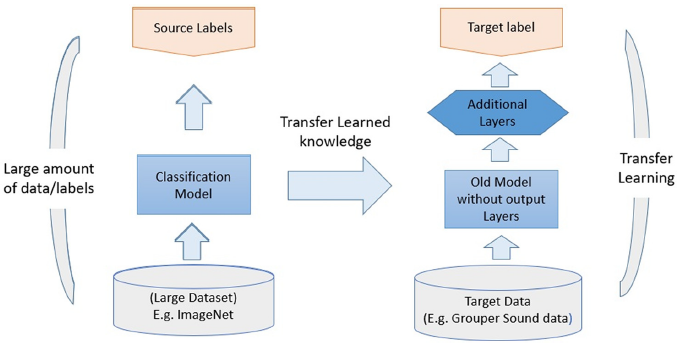
Transfer learning involves taking a model pre-trained on a large, general dataset and reusing it for a related, new task. The model already has knowledge of general patterns (e.g., shapes in images or phonemes in speech) from its original training, which is then transferred to the new task. This allows the model to adapt faster, often with limited data.
For simpler tasks, such as image classification, transfer learning typically involves:
- Freezing the internal layers to retain the general features the model learned.
- Replacing the final layer to fit the specific task at hand.
However, this approach may not be sufficient for complex tasks like voice synthesis, where capturing a speaker’s unique characteristics requires deeper model adjustments.

What is Fine-Tuning?
Fine-tuning is a specific type of transfer learning in which multiple layers of the pre-trained model are further trained on the new dataset. Unlike standard transfer learning, fine-tuning adjusts the model’s internal parameters to capture intricate details of the target task.
For voice synthesis, fine-tuning is necessary because:
- It helps the model learn unique vocal features such as pitch, tone, and rhythm specific to a speaker.
- The model adapts to the fine-tuning dataset, refining its sound generation to replicate the new voice more accurately.
Fine-Tuning vs. Transfer Learning in Voice Synthesis
For a voice synthesis task, capturing the precise vocal tone, pitch, and style requires more than just modifying the output layer. Here’s how transfer learning and fine-tuning compare:
| Feature | Transfer Learning (without Fine-Tuning) | Fine-Tuning |
|---|---|---|
| Task Complexity | Suitable for simpler tasks (e.g., image classification) | Required for complex tasks (e.g., voice synthesis, style replication) |
| Model Adaptation | Only the final layer is modified | Multiple layers are trained, adapting to nuanced characteristics |
| Customization | Limited; relies on general features learned in pre-training | High; captures unique voice details |
| Output Quality | Produces generic output, not specific to any unique style or tone | Replicates specific voice characteristics, making speech sound personalized |
| Use Case in Voice Models | Not effective for detailed tone or pitch replication | Essential for tasks requiring accurate voice replication |
Code Example: Fine-Tuning a Voice Synthesis Model (YourTTS)
Below is an example code to fine-tune the YourTTS model in Google Colab, adapting it to a specific voice.
# Step 1: Install Dependencies !pip install speechbrain !pip install torchaudio !pip install datasets !pip install gdown # for downloading pre-trained models if needed # Step 2: Import Libraries import torchaudio from speechbrain.pretrained import Tacotron2 # Import Tacotron2 only from datasets import load_dataset # Step 3: Download and Prepare the Dataset # Use the actual LibriSpeech dataset instead of the dummy dataset librispeech = load_dataset("librispeech_asr", "clean", split="validation") # Changed to the actual librispeech dataset # Step 4: Preprocess Data # Convert dataset to compatible format for fine-tuning audio_samples = [] for sample in librispeech: # The 'audio' column contains the audio data waveform = sample['audio']['array'] sample_rate = sample['audio']['sampling_rate'] audio_samples.append(torch.from_numpy(waveform)) # Convert to PyTorch tensor # Define a directory and save the audio samples (if needed for custom processing) import os import torch os.makedirs("prepared_data", exist_ok=True) for idx, audio in enumerate(audio_samples): torchaudio.save(f"prepared_data/audio_{idx}.wav", audio, sample_rate) # Step 5: Fine-Tune the YourTTS Model (pre-trained TTS model) # Fine-tune the model on the prepared audio dataset !git clone https://github.com/Edresson/YourTTS.git %cd YourTTS !python train.py hparams/finetune.yaml --data_folder ../prepared_data --output_folder ./fine_tuned_model # Step 6: Inference - Convert Voice Tone # Load the fine-tuned Tacotron2 model tacotron2 = Tacotron2.from_hparams(source='./fine_tuned_model', hparams_file='hparams/finetune.yaml') # Load HiFi-GAN vocoder (we use SpeechBrain's default vocoder instead of directly importing HiFi-GAN) hifi_gan = Tacotron2.from_hparams(source="speechbrain/tts-hifigan-ljspeech") # Text to be synthesized with the fine-tuned voice text = "This is a voice tone modification test." # Perform text-to-speech synthesis mel_output, mel_length, alignment = tacotron2.encode_text(text) waveforms = hifi_gan.decode_batch(mel_output) # Save and play the output torchaudio.save('output_audio.wav', waveforms.squeeze(1), 22050) # Step 7: Listen to the Output from IPython.display import Audio Audio('output_audio.wav')Why Transfer Learning Alone Isn’t Sufficient for This Code
For the example code provided, using only transfer learning without fine-tuning would not be effective or practical due to the nature of the task. Here’s why:
1. Nature of the Task (Voice Synthesis)
- Complexity of Speech Synthesis: Voice synthesis models, like YourTTS, need to generate natural, human-like speech. This involves understanding the intricate patterns of human voice, including pitch, tone, and intonation, which are specific to different speakers.
- Customization Required: The goal is to make the model sound like a particular speaker or match a specific voice tone. This requires the model to adjust its learned parameters to better capture the nuances of the target voice.
2. Transfer Learning Without Fine-Tuning
- What It Typically Means: Transfer learning without fine-tuning usually means using a pre-trained model as a feature extractor—keeping all its internal layers frozen and only replacing the final layer to adapt it to a new task (e.g., using a pre-trained model to classify new categories of images by changing the output layer).
- Limited Adjustments: For tasks like image classification, this approach is often sufficient because the pre-trained model can extract features (edges, shapes, textures) that are useful for a wide range of image types.
- Not Suitable for Voice: In voice synthesis, however, simply changing the final layer won’t make the model adapt to a new voice style or tone. The entire model needs to be tuned to adjust to the specific patterns of speech found in the new speaker’s data.
3. Why Fine-Tuning Is Necessary Here
- Deep Customization: To make the generated speech match a new speaker’s voice, the model must be re-trained on examples of that voice, so it can learn specific voice characteristics throughout its layers.
- Multiple Layers Adaptation: Fine-tuning allows adjustments in many layers of the model—not just the last one—so that the entire network can better mimic the fine details of the target voice.
- Maintains Pre-Trained Knowledge: Fine-tuning starts with the knowledge the model has from its original training on a large dataset (like LibriSpeech) but adapts it to better match the specifics of your target voice dataset.
In Summary:
- Not Possible with Just Transfer Learning (Without Fine-Tuning): Voice synthesis models like YourTTS require fine-tuning to adapt the entire network to the new speaker’s style.
- Why Not: If we only used the pre-trained model and adjusted the last layer (transfer learning without fine-tuning), the model wouldn’t effectively capture the unique vocal nuances required for convincing and natural-sounding voice generation.
- Fine-Tuning is Transfer Learning: Fine-tuning is, in fact, a form of transfer learning but applied more comprehensively, adjusting deeper layers rather than just the final one. This makes it suitable for complex tasks like adapting a model to a new voice.
Thus, for the specific example of adapting YourTTS to a new voice, fine-tuning is the necessary and effective approach to achieve the desired output.