Understanding Batch Normalization in Deep Learning
Deep learning has revolutionized numerous fields, from computer vision to natural language processing. However, training deep neural networks can be challenging due to issues like unstable gradients. In particular, gradients can either explode (grow too large) or vanish (shrink too small) as they propagate through the network. This instability can slow down or completely halt the learning process. To address this, a powerful technique called Batch Normalization was introduced.
The Problem: Unstable Gradients
In deep networks, the issue of unstable gradients becomes more pronounced as the network depth increases. When gradients vanish, the learning process becomes very slow, as the model parameters are updated minimally. Conversely, when gradients explode, the model parameters may be updated too drastically, causing the learning process to diverge.

Introducing Batch Normalization
Batch Normalization (BN) is a technique designed to stabilize the learning process by normalizing the inputs to each layer within the network. Proposed by Sergey Ioffe and Christian Szegedy in 2015, this method has become a cornerstone in training deep neural networks effectively.
How Batch Normalization Works
Batch Normalization normalizes the input features for each mini-batch by adjusting and scaling the inputs. Here’s a step-by-step breakdown of the process:
Step 1: Compute the Mean and Variance
For each mini-batch of data, Batch Normalization first computes the mean (μB) and variance (σ²B) for each feature. These statistics are then used to normalize the inputs.
Example:
Consider a mini-batch with three examples and three features:
| Example | Feature 1 | Feature 2 | Feature 3 |
|---|---|---|---|
| 1 | 1.0 | 3.0 | 2.0 |
| 2 | 2.0 | 4.0 | 3.0 |
| 3 | 3.0 | 5.0 | 4.0 |
For Feature 1, the mean (μB1) and variance (σ²B1) are calculated as follows:
Step 2: Normalize the Inputs
Next, the inputs are normalized by subtracting the mean and dividing by the square root of the variance (with a small constant ε added to avoid division by zero):
hat{x}^{(i)} = frac{x^{(i)} - μ_B}{sqrt{σ_B^2 + ε}}
This normalization ensures that the inputs have a mean of 0 and a variance of 1.
Step 3: Scale and Shift
After normalization, Batch Normalization introduces two learnable parameters for each feature: γ (scale) and β (shift). These parameters allow the network to adjust the normalized data to match the original input distribution if needed.
z^{(i)} = γ hat{x}^{(i)} + β
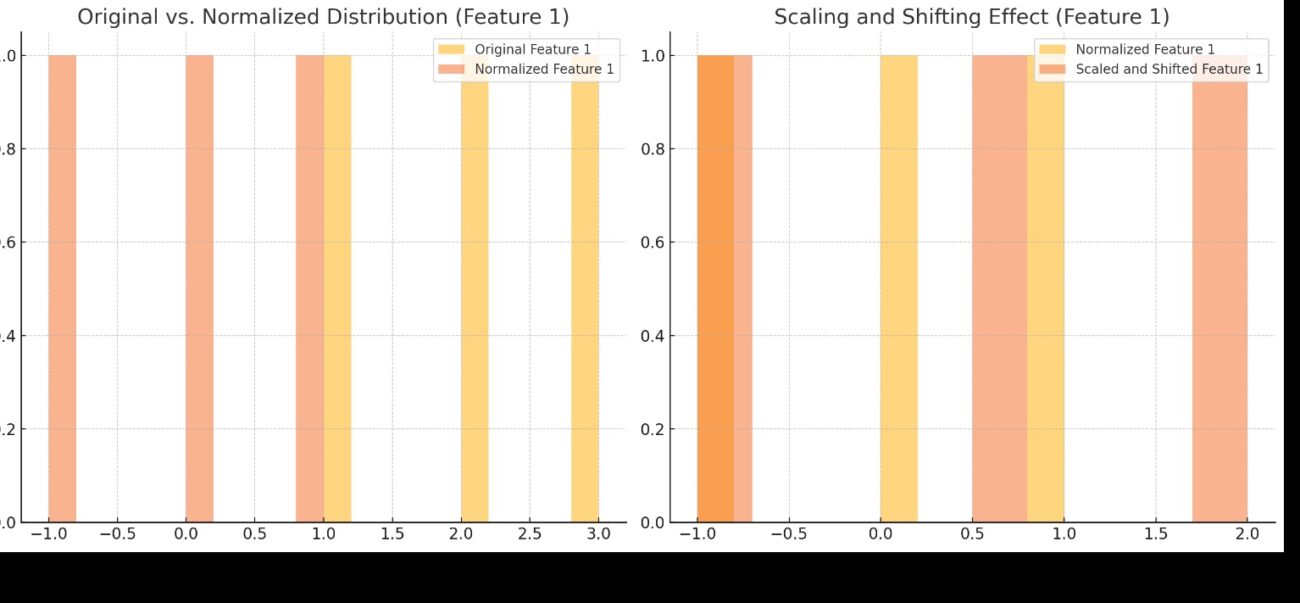
Visual Example: Scaling and Shifting Effect
To better understand the impact of scaling and shifting, consider Feature 1 from the earlier example. Below is a graph that compares the distribution of the original data, the normalized data, and the scaled and shifted data. You will find this graph at the end of the article.
Practical Example and Table
Here’s a summary of the process for the three features in our example:
| Example | Feature 1 | Feature 2 | Feature 3 | Normalized Feature 1 | Normalized Feature 2 | Normalized Feature 3 | Scaled and Shifted Feature 1 | Scaled and Shifted Feature 2 | Scaled and Shifted Feature 3 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1.0 | 3.0 | 2.0 | -1.224 | -1.224 | -1.224 | -1.336 | -1.224 | -1.112 |
| 2 | 2.0 | 4.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.5 | 0.0 | -0.5 |
| 3 | 3.0 | 5.0 | 4.0 | 1.224 | 1.224 | 1.224 | 2.336 | 1.224 | 0.112 |
Graphical Representation
Here is the graph illustrating the scaling and shifting effect for Feature 1:
T
Benefits of Batch Normalization
Batch Normalization offers several significant benefits:
- Faster Training: By stabilizing the input distributions, BN allows for the use of higher learning rates, speeding up the training process.
- Reduced Sensitivity to Initialization: The network becomes less dependent on careful initialization of parameters, as BN mitigates the effects of poor initial conditions.
- Improved Regularization: BN can have a slight regularizing effect, reducing the need for other forms of regularization like dropout.
Conclusion
Batch Normalization is a vital technique in deep learning, enabling faster, more stable, and more effective training of deep neural networks. By normalizing the inputs within each mini-batch and then scaling and shifting them, BN addresses the issue of unstable gradients and enhances the network’s ability to learn complex patterns.
By incorporating Batch Normalization into your deep learning models, you can significantly improve their performance and training efficiency.