Step-by-Step Explanation of RNN for Time Series Forecasting
In this article, we’ll walk through the detailed explanations of RNN-based methods for time series forecasting, using real number examples and corresponding mathematical operations behind them. We’ll use both TensorFlow and PyTorch examples for each step.
Step 1: Simple RNN for Univariate Time Series Forecasting
Explanation:
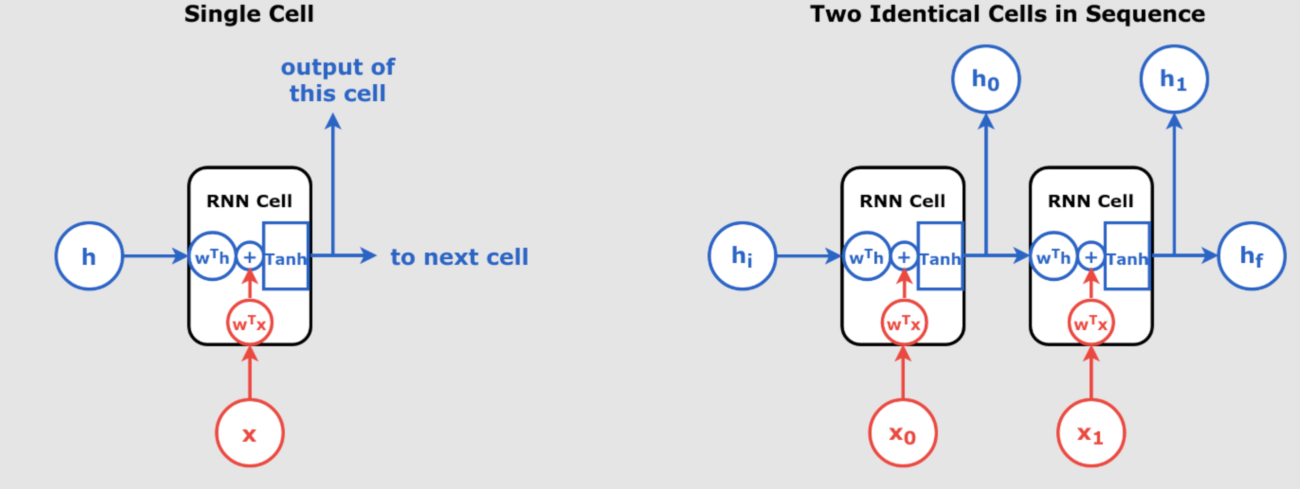
An RNN processes sequences of data, where the output at any time step depends on both the current input and the hidden state (which stores information about previous inputs). In this case, we use a Simple RNN with only one recurrent neuron.

TensorFlow Code:
model = tf.keras.Sequential([ tf.keras.layers.SimpleRNN(1, input_shape=[None, 1]) ])
Numerical Example:
Let’s say we have a sequence of three time steps: ![[x_1, x_2, x_3] = [0.1, 0.2, 0.3]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-4e6d13b6dde5b5da63922f588ac9cf83_l3.png "Rendered by QuickLaTeX.com") .
.
1. Input and Hidden State Initialization:
The RNN starts with an initial hidden state  , typically initialized to 0. Each step processes the input and updates the hidden state:
, typically initialized to 0. Each step processes the input and updates the hidden state:

where:
 is the weight for the hidden state.
is the weight for the hidden state.- is the weight for the input.
 is the bias term.
is the bias term. is the activation function (hyperbolic tangent).
is the activation function (hyperbolic tangent).
 is the weight for the hidden state.
is the weight for the hidden state. is the weight for the input.
is the weight for the input. is the activation function (hyperbolic tangent).
is the activation function (hyperbolic tangent).Assume:



Let’s calculate the hidden state updates for each time step:
Time Step 1:

Time Step 2:

Time Step 3:

Thus, the final output of the RNN for the sequence is  .
.
PyTorch Equivalent Code:
import torch import torch.nn as nn class SimpleRNNModel(nn.Module): def __init__(self): super(SimpleRNNModel, self).__init__() self.rnn = nn.RNN(input_size=1, hidden_size=1, batch_first=True) def forward(self, x): output, hidden = self.rnn(x) return output[:, -1, :] # returning only the final output # Model instantiation model = SimpleRNNModel()
—
Step 2: Understanding the Sequential Process of the RNN
Explanation:
At each time step, the RNN processes the input by updating the hidden state based on both the current input and the previous hidden state. This hidden state acts like “memory,” allowing the RNN to capture temporal dependencies.
Let’s break down the calculations we did above:
- At time step 1: The hidden state is computed as
 .
. - At time step 2: The hidden state is updated to .
- At time step 3: The final hidden state becomes .
 .
. .
. .
.The RNN effectively “remembers” the inputs from earlier time steps through the hidden state. This process can be repeated for sequences of any length.
—
Step 3: Larger RNN with a Dense Output Layer
Explanation:
To improve performance, we increase the number of neurons in the RNN and add a fully connected Dense layer. This allows the model to capture more complex relationships and map the RNN’s output to a single prediction.
TensorFlow Code:
univar_model = tf.keras.Sequential([ tf.keras.layers.SimpleRNN(32, input_shape=[None, 1]), tf.keras.layers.Dense(1) ])
Numerical Example:
Let’s extend our example with a larger RNN that has 32 neurons. The hidden state now becomes a vector of 32 values, instead of just 1.
Let’s assume:
 for each time step is now a vector of length 32.
for each time step is now a vector of length 32.- The final hidden state at time step 3,
 , will also be a vector of length 32.
, will also be a vector of length 32.
 for each time step is now a vector of length 32.
for each time step is now a vector of length 32.The Dense layer will then map this vector to a single output. Suppose the Dense layer has weights  and bias
and bias  . The output is computed as:
. The output is computed as:

Where is a vector of length 32, and  is the hidden state vector from the last RNN layer.
is the hidden state vector from the last RNN layer.
PyTorch Equivalent Code:
class SimpleRNNWithDense(nn.Module): def __init__(self): super(SimpleRNNWithDense, self).__init__() self.rnn = nn.RNN(input_size=1, hidden_size=32, batch_first=True) self.fc = nn.Linear(32, 1) def forward(self, x): x, _ = self.rnn(x) x = x[:, -1, :] x = self.fc(x) return x # Model instantiation model = SimpleRNNWithDense()
—
Step 4: Building a Deeper RNN (Stacked RNN Layers)
Explanation:
In a deeper RNN (also called a stacked RNN), multiple RNN layers are placed on top of each other. The first RNN layer processes the input sequence and passes its output (a sequence of hidden states) to the second RNN layer, and so on. Each layer refines the representation of the input data, helping the network learn more complex temporal dependencies.
TensorFlow Code:
deep_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, return_sequences=True, input_shape=[None, 1]), # First RNN layer
tf.keras.layers.SimpleRNN(32, return_sequences=True), # Second RNN layer
tf.keras.layers.SimpleRNN(32), # Third RNN layer
tf.keras.layers.Dense(1) # Dense output layer
])
Numerical Example:
Let’s use a **3-time-step sequence** as input.
We will assume that each RNN layer has:
- A hidden size of 32 neurons.
- Weight matrices (hidden-to-hidden weights), (input-to-hidden weights), and biases .
- as the activation function.
First RNN Layer:
At each time step, the input  and the previous hidden state
and the previous hidden state  are combined to produce the new hidden state
are combined to produce the new hidden state  for the first layer:
for the first layer:

For simplicity, assume  and
and  . The initial hidden state
. The initial hidden state  .
.
Time Step 1:

Time Step 2:

Time Step 3:

At the end of the first RNN layer, we have the following hidden states for all time steps:
![[h_1^1, h_2^1, h_3^1] = [0.149, 0.268, 0.366]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-8a46c0d4b52d6f39c009cc9f0d8144c1_l3.png "Rendered by QuickLaTeX.com")
Second RNN Layer:
The second RNN layer takes the outputs from the first RNN layer and processes them similarly. Assume  and
and  .
.
Time Step 1:

Time Step 2:

Time Step 3:

After the second RNN layer, we have:
![[h_1^2, h_2^2, h_3^2] = [0.138, 0.285, 0.414]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-39b3fdad2f9201f99cd8b2de343cf321_l3.png "Rendered by QuickLaTeX.com")
Third RNN Layer:
The third RNN layer follows the same process. Assume  and
and  .
.
Time Step 1:

Time Step 2:

Time Step 3:

The output of the third RNN layer at the final time step  is passed to the Dense Layer.
is passed to the Dense Layer.
Dense Layer Output:
Assume the Dense layer has weights  and bias
and bias  . The final prediction is computed as:
. The final prediction is computed as:

Thus, the final output of the stacked RNN is  .
.
—
Step 5: Forecasting Multivariate Time Series
Explanation:
In multivariate time series, each time step contains multiple features (e.g., temperature, humidity, and wind speed). The RNN takes these multiple features and updates its hidden state based on all of them.
TensorFlow Code:
mulvar_model = tf.keras.Sequential([ tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]), # 5 features per time step tf.keras.layers.Dense(1) ])
Numerical Example:
Let’s assume we have a **3-time-step sequence** with **5 features** at each time step. For simplicity, let’s use the following input:

The input matrix  has 3 time steps (rows) and 5 features (columns).
has 3 time steps (rows) and 5 features (columns).
Assume:
- is a matrix of size
 (to process 5 features and produce 32 hidden states).
(to process 5 features and produce 32 hidden states). - is a matrix of size
 (to process the previous hidden state of 32 units).
(to process the previous hidden state of 32 units). - The biases are vectors of size 32.
- The activation function is .
 (to process 5 features and produce 32 hidden states).
(to process 5 features and produce 32 hidden states). (to process the previous hidden state of 32 units).
(to process the previous hidden state of 32 units).Let’s calculate the hidden state updates for each time step:
Time Step 1:
The input at the first time step is ![x_1 = [0.1, 0.2, 0.3, 0.4, 0.5]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-9c56ef07e76b7382b8c4fee36b4fcbd9_l3.png "Rendered by QuickLaTeX.com") .
.
The hidden state is updated as:

For simplicity, assume ![W_x \cdot x_1 = [0.15, 0.2, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-2aeafd2528a12b81f55c47ad900ce29f_l3.png "Rendered by QuickLaTeX.com") (a vector of 32 values) and the bias
(a vector of 32 values) and the bias  adds a small value to each component. The hidden state becomes a vector of length 32:
adds a small value to each component. The hidden state becomes a vector of length 32:
![h_1 = \tanh([0.15, 0.2, \dots]) = [0.149, 0.197, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-003f34b34c8a1257b2f52dafe7e8357d_l3.png "Rendered by QuickLaTeX.com")
—
Time Step 2:
The input at time step 2 is ![x_2 = [0.2, 0.3, 0.4, 0.5, 0.6]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-5ecd19b56f27e9ec463abe738c4819bf_l3.png "Rendered by QuickLaTeX.com") . The hidden state is updated as:
. The hidden state is updated as:

Assume ![W_h \cdot h_1 = [0.12, 0.18, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-79db02b939b4da2405754a934a26be54_l3.png "Rendered by QuickLaTeX.com") and
and ![W_x \cdot x_2 = [0.25, 0.3, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-33145f2cd518cb7844ed3bc1c5093a85_l3.png "Rendered by QuickLaTeX.com") . The hidden state becomes:
. The hidden state becomes:
![h_2 = \tanh([0.37, 0.48, \dots]) = [0.354, 0.447, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-33dca372c59c507334ce4fb482932fb3_l3.png "Rendered by QuickLaTeX.com")
—
Time Step 3:
The input at time step 3 is ![x_3 = [0.3, 0.4, 0.5, 0.6, 0.7]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-cc66c1605c1201e5a2094ab4a55c44d1_l3.png "Rendered by QuickLaTeX.com") . The hidden state is updated as:
. The hidden state is updated as:

Assume ![W_h \cdot h_2 = [0.2, 0.25, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-8e6b6d62717b76d2a7554abef73e8183_l3.png "Rendered by QuickLaTeX.com") and
and ![W_x \cdot x_3 = [0.3, 0.35, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-95d362aa4ad207c52e1e8a53ccd7e0ab_l3.png "Rendered by QuickLaTeX.com") . The final hidden state becomes:
. The final hidden state becomes:
![h_3 = \tanh([0.5, 0.6, \dots]) = [0.462, 0.537, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-325d164730067d83d07e8cab169d8bec_l3.png "Rendered by QuickLaTeX.com")
—
Dense Layer Output:
The final hidden state is passed to the Dense layer, which outputs the prediction. Assume the Dense layer has weights ![W_d = [0.5, \dots]](https://ingoampt.com/wp-content/ql-cache/quicklatex.com-6a94d54c4bb6263eeb989b54e50fd48f_l3.png "Rendered by QuickLaTeX.com") and bias . The output is:
and bias . The output is:

Thus, the final prediction is  .
.
—
Key Takeaways:
- Step 4: In stacked RNNs, each layer processes the sequence and passes it on, allowing the network to learn deeper temporal dependencies.
- Step 5: For multivariate time series, RNNs can process multiple features at each time step, updating the hidden state based on the combined information from all the features.